A Taxonomy of Bugs
Debugging is often an undervalued skill. It’s not really taught in schools (as far as I know), instead, you kind of have to pick it up as you go along. Today, I’ll try to remedy that by looking at some common bugs and what to do about them.
The default strategy I use with any bug is to:
- Try to find a way of reliably reproducing the bug so that I can
- break into the debugger when the bug happens and
- step through the code line by line to
- see how what it is doing differs from what I think it should be doing.
Once you understand how the code’s actual behavior differs from your mental model of its behavior, it is typically easy to identify the problem and fix it.
I know that there are some very successful programmers that don’t really use debuggers but instead
rely completely on printf() and logging. But I don’t really understand how they do it. Trying
to understand what the code is doing by inserting one printf() at a time and then re-running the
tests seems so much more inefficient than using a debugger. If you’ve never really used a debugger
(I know, they don’t teach these things in school), I suggest you try it! Get comfortable with
stepping through the code and examining what it does.
Of course, there are some situations where you can’t capture the bug in the debugger and have to resort to other methods, but we’ll get to that later, so let’s get started.
The Typo
Unlike most other bugs, the Typo is not caused by any flawed reasoning. You had the right idea, you just happened to type something else. Luckily, most typos are caught by the compiler, but sometimes your boo-boos compile:
if (set_x)
pos.x = new_pos.x;
if (set_y)
pos.x = new_pos.y;
if (set_y)
pos.z = new_pos.z;
Once you see them, typos are trivial to fix. The hard part is seeing them in the first place.
Typos can be hard to spot because just as when you read text with spelling errors, your brain auto-corrects the code as you read it. To be good at proofreading, you have to force your brain to go into a different mode where it focuses more on the text itself than the meaning of the text. This can be tricky, but you get better with practice.
If you can’t spot the typo just from reading the code, you can switch to our default debugging method — stepping through the code line by line and checking that each line does what you expect it to.
How can you prevent typos? It might seem that there is nothing you can do. Your brain will just glitch every once in a while and there is nothing you can do to stop it.
I don’t believe in such fatalism. Instead, I subscribe to the philosophy of continuous small improvements. The goal is not to be perfect, the goal is to do a little better each day and over time the accumulation of all those small improvements will add up to big gains.
So let’s try again. How can you make typos a little less likely?
First, you should enable as many compiler warnings as possible and also tell the compiler to treat warnings as errors. The goal is to have the compiler detect as many typos as possible so that you can fix them before they turn into actual bugs.
A warning that makes a big difference for me is -Wshadow. -Wshadow makes it an error to reuse a
variable name in a sub-scope. This prevents stupid mistakes like:
int test = x;
{
int test = f();
g(test); // <-- Meant to use `test` from outer scope.
}
Before I enabled -Wshadow, I made a lot of these mistakes. Mostly with very generic variable
names, such as i or x.
Second, use a source code formatter and run all your source code through it. We use
clang-format and run it automatically on Save and git commit. The source code formatter can
sometimes reveal typos. For example, if you type this:
if (x > max);
max = x;
the source code formatter will change it to:
if (x > max)
;
max = x;
Which makes the bug more obvious.
Another thing you can do is to write things in a way that produces fewer typos. For example, I used to write for-loops like this:
for (uint32_t i=0; i<tm_carray_size(items); ++i) {
child_t *children = get_children(items[i]);
for (uint32_t j=0; j<tm_carray_size(children); ++j)
...
}
However, I noticed that this would often result in typos where I would write children[i] instead
of children[j]. So I started changing to:
for (uint32_t item_i=0; item_i<tm_carray_size(items); ++item_i) {
child_t *children = get_children(items[item_i]);
for (uint32_t child_i=0; child_i<tm_carray_size(children); ++child_i)
...
}
With this, I’m much less likely to write children[item_i]. These days, I’ve switched to just
iterating over the pointers instead:
for (const item_t *i = items, *ie = tm_carray_end(items); i != ie; ++i) {
child_t *children = get_children(*i);
for (const child_t *c = children, *ce = tm_carray_end(children); c != ce; ++c)
...
}
Since i and c now have different types, it is impossible to confuse them. And if I would
accidentally write *ce = tm_carray_end(items) this would also give a compile error.
Everybody makes different typos, so find defensive strategies that work with the kind of typos you usually make. A general tip is to use const for variables that don’t change:
const uint32_t n = tm_carray_size(items);
This prevents you from accidentally changing the variable later.
Finally, a pretty common source of typos for me is when I copy-paste some code but don’t patch it up correctly. The first code snippet above is an example of that:
if (set_x)
pos.x = new_pos.x;
if (set_y)
pos.x = new_pos.y;
if (set_y)
pos.z = new_pos.z;
I copy-pasted the first two lines and then forgot to change one of the x to an y. But I don’t
want to stop copy-pasting, it saves a lot of time. I’m also not sure that hand-typing repetitive
code would really reduce the error rate.
I’ve found two things that help with this. The first is the multi-select feature that is
available in many modern code editors, such as VS Code. Using that, I would first paste the code
and then multi-select all three xs by selecting the first one and pressing Ctrl-D repeatedly
until they all are selected and then finally change them all to y with a single keystroke.
The second is Copilot, the AI-assisted auto-completion technology from GitHub. Copilot is great at recognizing repetitive programming patterns like this and I find that having Copilot autofill in the code is less error-prone than copy-pasting and tidying it up by hand. I’m not willing to let an AI drive my car just yet, but I’m willing to have it write my repetitive code for me. If you haven’t tried out Copilot yet, I suggest you do.
The Logical Error
The Logical Error is perhaps the thing you mostly think of when you think bug. A logical error occurs when the code you wrote doesn’t actually do the thing you meant for it to do.
A common example is the off-by-one error, where you do one thing more or one thing less than you should. For example, this code for removing an item from an array:
memmove(arr + i, arr + i + 1, (num_items - i) * sizeof(*arr));
--num_items;
The nice thing about logical errors is that once you have a repro case it tends to be 100 % reproducible because the code behaves the same every time. So you can usually figure out what’s going on by stepping through the code.
To reduce the risk of logical errors, the first thing you can do is to simplify your expressions. The simpler and easier the code is to read, the smaller is the chance that you’ll get confused about the logic.
Another thing that helps is to reduce the number of possible paths through the code. I.e. instead of something like this:
// Fast path for removing the last item in the array.
if (i == num_items - 1)
--num_items;
else {
--num_items;
memmove(arr + i, arr + i + 1, (num_items - i) * sizeof(*arr));
}
just call the memmove() every time and count on the fact that a memmove() of zero bytes will
still be pretty fast.
Why? Well, to begin with, having less code means a smaller risk for bugs. But more importantly, if you have code paths that only occasionally get exercised, they won’t get as much testing as the rest of the code. A bug could hide there and sneak past your quick tests only to blow up in production.
In general, strive for linear code — code that progresses in a logical fashion from one line to the next, that you can read as a coherent story instead of having to jump around in the code a lot to understand what is going on.
Another thing that can help is to use standard idioms. For example, if you need to erase items a lot, you can introduce a macro for it:
#define array_erase_item(a, i, n) \
(memmove((a) + (i), (a) + (i) + 1, ((n) - (i) - 1) * sizeof(*(a)), --(n))
Now if there is a logic error, the error will be in a single place and can be fixed more easily.
The Unexpected Initial Condition
Another possibility is that your logic is flawless, but your code still fails, because the initial state of the data was one you didn’t expect. I.e., if the data had been in the state you had expected, everything would have worked out fine, but since it wasn’t, the algorithm failed:
flag_t flags[MAX_FLAGS];
uint32_t num_flags;
void add_flag(flag_t flag) {
flags[num_flags++] = flag;
}
The code above works well under the assumption that num_flags < MAX_FLAGS, but otherwise it will
write beyond the end of the array.
Does this mean that the code should be rewritten to use dynamically allocated memory to remove the
MAX_FLAGS limit? No, not necessarily. It is perfectly fine to have limits in what you support,
in fact, all code does. If you switched to a dynamically allocated array, the code would still fail
if you had more than UINT32_MAX flags. And if you changed num_flags to an uint64_t or some
kind of “bignum” you would still eventually run out of memory at some point.
If you don’t ever expect to have more than a handful of flags, it is perfectly fine to have a
MAX_FLAGS of 32 or something similar.
The best way of dealing with unexpected initial conditions is to make your expectations explicit. Some languages have facilities for this built into the language in the form of preconditions that you can specify for a function. In C, the best way is through an assert:
flag_t flags[MAX_FLAGS];
uint32_t num_flags;
void add_flag(flag_t flag) {
assert(num_flags < MAX_FLAGS);
flags[num_flags++] = flag;
}
Sometimes it can be unclear who is responsible for the bad initial condition. Is it the fault of the function for not handling that special case or is it the fault of the caller for sending the function bad data? Clearly documenting the acceptable initial conditions and adding asserts to detect them puts the responsibility on the caller.
The Memory Leak
A memory leak occurs when your code allocates memory that it never frees. Memory leaks are not the
only leaks you have to worry about, code can also leak other things like threads, critical
sections, or file handles. But memory leaks are by far the most common ones, so let’s focus on
that.
In C and C++, the standard way to allocate memory is to just call malloc() or new to get some
memory from the system allocator. Many other languages have a similar approach where creating an
object will allocate some memory from a global allocator.
Finding and fixing memory leaks in such setups is really hard. First, you typically don’t even know that there’s a memory leak until you completely run out of system memory or notice in the Task Manager that you are using gigabytes more than you expect. Smaller memory leaks will probably never be detected or fixed.
Second, to fix it, you need to find out who allocated memory that they never released. That is
really hard because in the code, you just have a bunch of sprinkled malloc() and free() calls
— how are you supposed to know where a free() is missing?
In languages with automated memory management — garbage collection or reference counting — this is less of a problem because in these languages the memory is automatically freed when there are no more references to it. However, this does not completely get rid of leaks. Instead, it will trade memory leaks for reference leaks, where someone holds a reference to something they should have let go of. This reference keeps the object alive, sometimes a whole tree of objects, wasting memory.
Reference leaks can be even harder to deal with than memory leaks. Manual memory management forces you to be explicit about who owns a piece of memory, so if that piece of memory doesn’t get released, you will know who is at fault. With automatic memory management, there is no single designated owner, anyone can hold a reference that keeps the memory alive.
The best way of dealing with memory (and other resource) leaks is to add instrumentation to
memory allocations. I.e., instead of calling malloc() directly, you call a wrapper function
that lets you pass in some extra parameters. For example:
item_t *p = my_malloc(sizeof(item_t), __FILE__, __LINE__);
my_malloc() can use this extra information to record all memory allocations: the size, pointer,
file name, and line number where the allocation happened. A corresponding my_free() function can
record all the free() calls. We can then dump all the calls to a log (or analyze them in some
other way) to find memory leaks. If someone is allocating memory without freeing it, we can pinpoint
the file name and line number where that happens which is usually enough to figure out the bug.
Recording all the memory calls has a bit of overhead, so you might want to save that for special
“Instrumental” builds, especially if you have lots of small memory allocations. (Which you should
generally try to avoid.)
In The Machinery, we go one step further. Instead of having a single global allocator that everything goes through, each system in the engine has its own allocator. In many cases, the system allocator just forwards the allocation calls to the global allocator, but the advantage of having a system-specific allocator is that we can keep track of the total allocated memory in that system without much overhead (we just add the allocated size to a counter and subtract on free). This allows us to easily see the amount of memory used in each system. Also, when a system is shut down, we make sure that the memory counter is at zero. If not, we report a memory leak in that system and the user can do a more detailed analysis by using an instrumented build for that system.
With this approach, the problem of memory leaks almost completely disappears. We will still occasionally create memory leaks because we are human and errors happen, but they get detected and fixed quickly.
The Memory Overwrite
A memory overwrite happens when a piece of code writes to some memory location that it doesn’t own. There are typically two cases where this happens.
- “Write after free” is when the system writes to a pointer after freeing it.
- “Buffer overflow” is when the system writes beyond the end of an array that it has allocated.
The biggest problem with memory overwrite bugs is that they usually don’t manifest immediately. Instead, they might blow up later, in a completely different part of the code. In the write after free case, the system allocator might have recycled the freed memory and allocated it to somebody else. The write operation will then trash that system’s data which might cause a crash or a weird behavior when that system tries to use it.
In the buffer overflow case, most commonly the code will write over the bytes immediately after the allocated memory. Typically, those bytes are used by the memory allocator to store various kinds of bookkeeping data, for example, to link memory blocks together in chains. The write will trash that data which will usually cause a crash inside the memory allocator at some later point when it tries to use the data.
Since the crash happens in a completely different part of the code than where the bug originated it can be hard to pin down the problem.
The tell-tale sign of a memory overwrite bug is that you get lots of weird crashes in different parts of the code, often in the memory allocator itself, and when you look at the data it looks trashed. Some managed languages make memory overwrites impossible by completely preventing code from accessing memory that it doesn’t “own”. But note that this also often limits what the language can do. For example, it can be hard or impossible to write a custom memory allocator in such languages.
Sometimes you can guess where the problem might be by the pattern of where the crashes occur.
Another thing you might try is to turn off big parts of the application to try to pinpoint it. For
example, if the bug disappears when you disable sound, you can suspect that the issue is in the
sound system. If the bug appeared recently, you can also try git bisect to find the commit that
introduced it.
But these are pretty blunt instruments. It would be much better if we could capture the bug as it happens instead of having things blow up later.
In The Machinery, we have a method for doing just that. Remember how I said we use custom
allocators everywhere. To catch memory overwrite bugs, we switch out our standard allocator for an
End-Of-Page allocator. This allocator does not use malloc(), instead, it allocates whole pages
of memory directly from the VM and it positions the memory the user requested at the very end of
the memory page (hence the name end-of-page allocator):
A
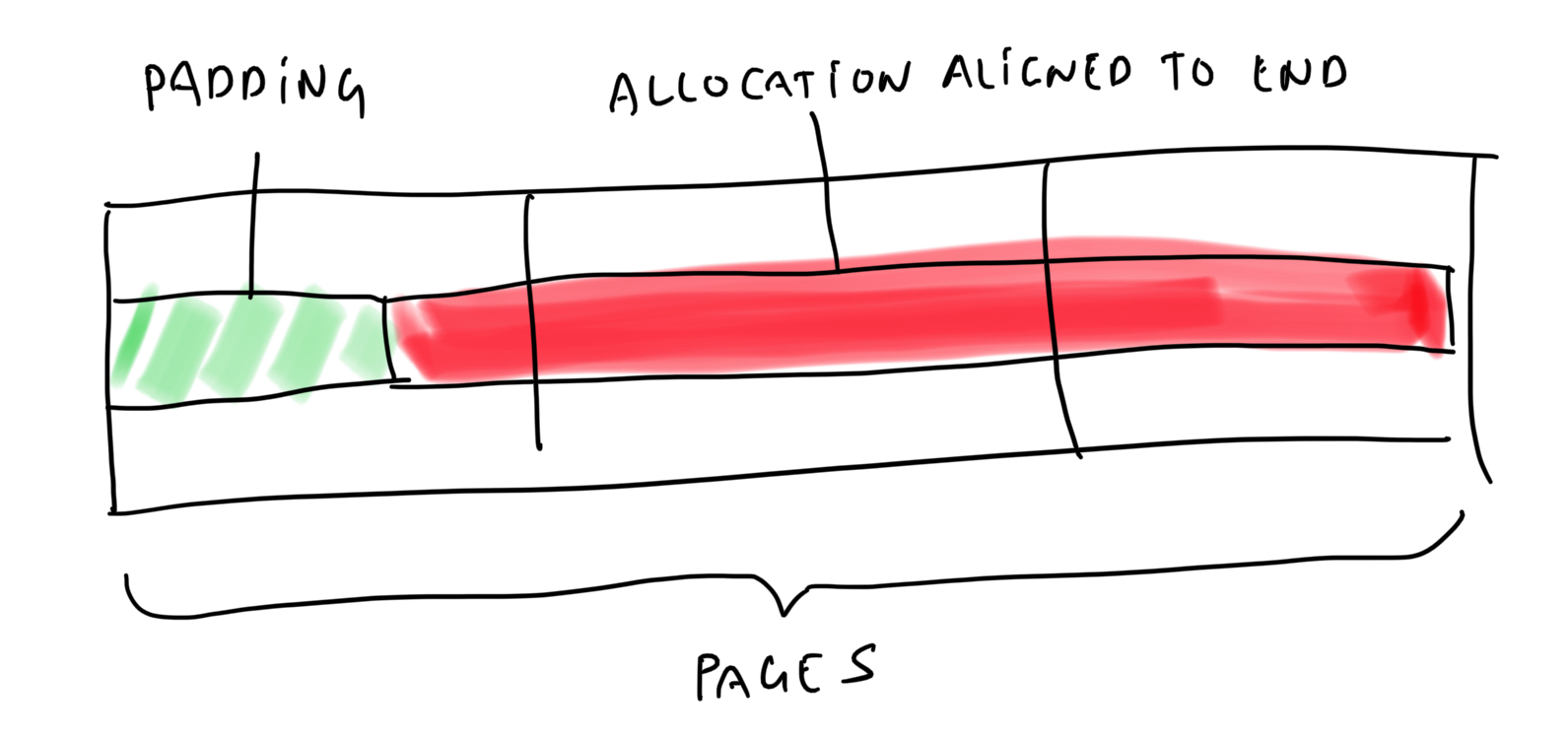
Aligning an allocation to the end of the pages.
In code this just looks something like this:
const uint64_t size_up = (size + page_size - 1) / page_size * page_size;
char *base = tm_os_api->virtual_memory->map(size_up);
const uint64_t offset = size_up - size;
return base + offset;
Similarly, when we free the memory, we free the whole page.
Since free() now completely unmaps the memory in the VM, writing after free will no longer trash
some other poor system’s data. Instead, it will cause an immediate access violation. This means
that you no longer will have to play the guesswork of trying to figure out where the bad write came
from, you will get an access violation at the exact point in the code where it happened. And from
there, figuring out the bug is usually straightforward.
Similarly, since we positioned the allocation at the very end of the page, a buffer overflow will go into the next page, which has not been mapped and again trigger an access violation.
Since we started to use this strategy we haven’t really had any big issues with memory overwrite bugs. They still happen from time to time, but when we notice the tell-tale signs, we can usually find them and squash them quickly by enabling the end-of-page allocator.
The Race Condition
I’ll use race condition as a common name for any kind of multithreading bug. Race conditions occur when different threads touch the same data and their changes interact in unexpected ways.
Race conditions can be tricky because they are timing-related. I.e., the bug may only happen if two threads happen to touch the exact same thing at the exact same time. That could mean that the bug shows up on one machine, but not on another. It can also mean that if you add some print statements to figure out what is going on, the timing changes and the bug disappears. Which can be really frustrating.
They can also be tricky because multi-threaded code is hard to reason about. Especially in this day and age when the code you write can be reordered by the compiler or the CPU.
So what can you do about threading bugs?
Well, you could use a language that eliminates the possibility of race conditions. Yes, Rust-gals and Rust-guys, this is the moment you have been waiting for! This is your time to shine!
Rust kind of ingeniously gets rid of most (not all) threading issues by keeping track of who has the right to write to every piece of data and making sure that no two threads simultaneously have write access to the same piece of data.
Rust aficionados argue that since the future will be more and more multi-threaded and since multi-threaded code without these kinds of checks is too hard to write, Rust is the future of systems programming. I’m not convinced. I value simplicity a lot and Rust seems like a very complicated language, but we will see.
Barring Rust, what else can you do about these bugs?
Well first, it pays to make sure that you are actually looking at a threading bug and not something else. I like to have a flag in each system that forces it to go single-threaded. That way, it’s a fairly quick check to see if disabling the multi-threading resolves the issue. If so, you can suspect a threading bug and start to dig deeper.
The next step might be to insert some extra critical sections into suspicious parts of the code to force it to run one thread at a time. If that fixes it, you can suspect that there’s a problem with the multithreading logic in that part of the code.
But race conditions are always tricky to fix. The best thing is if you can prevent them from happening in the first place.
A good way of doing that is to simplify your threading code. I find multi-threaded code really hard to reason about. With single-threaded code, you can just step through it in your head line-by-line. With multi-threaded code, you have to consider every possible order the threads might execute the instructions, including possible reorderings by the compiler or the CPU. That’s a lot of permutations for one little brain to deal with.
So don’t try to be fancy with multi-threaded code. Don’t try to implement clever lock-free algorithms unless you are really, really, really, really, really sure that you need it. Stick to a few well-known patterns and use them throughout the code.
A good example of this is Go. Go doesn’t have the same multi-threading safety features as Rust does. But the multi-threading model that Go encourages with goroutines and channels is simple to understand and pushes users towards safe multi-threaded programming patterns even if it doesn’t completely eliminate the possibility of error.
Another useful tool to have in your race condition arsenal is Clang’s thread sanitizer. The thread sanitizer can alert you to many possible race conditions before they happen.
The Design Flaw
Sometimes the problem is not a bug in a particular piece of the code, the problem is that the code cannot possibly work, no matter how you write it, because the whole thinking behind it is flawed. This may sound weird, so let’s look at a simple example:
// If `s` is not HTML-encoded, adds HTML-encoding (< etc) to `s` and
// returns it, if `s` is already HTML-encoded, returns it unchanged.
const char *ensure_html_encoded(const char *s);
At first glance, this may seem reasonable, but the thinking behind this function is flawed. The
problem is that there is no way of telling whether a string is HTML-encoded or not. The string
< might either be an HTML-encoded version of the string < or it might be that the user
actually wanted to take the string < and HTML-encode that!
This design flaw could lie buried in a program for a really long time until one day someone tries
to use ensure_html_encoded() to encode a string that looks like an already HTML-encoded string
and then the whole thing will blow up.
There is no way of fixing this by changing the implementation of ensure_html_encoded(). The only
way to fix it is to change the design itself and replace ensure_html_encoded() with something like
html_encode() that always HTML-encodes the input string, whether it looks like it’s already
HTML-encoded or not.
But you can’t simply replace all the calls to ensure_html_encoded() with calls to html_encode(),
because some of the strings passed in to ensure_html_encoded() might be already encoded, if you
call html_encode() on them, they will be doubly encoded. Instead, you must overhaul the entire
logic of HTML-encoding and make sure you properly keep track of what is HTML-encoded and what isn’t.
Design flaw bugs can be tricky, especially for beginning programmers, because they require you to take a step and look at the bigger picture and realize that the problem is not the particular bug that you are trying to fix, the problem is that the whole thinking is flawed.
The example above is pretty simple, design flaws can get a lot hairier and harder to spot than
this. A pretty common case is that you have a function f() that gets called from two (or more)
places g() and h(), where g() and h() expect f() to do its thing a little bit differently
(the documentation doesn’t exactly specify what f() does). The author of g() files a bug report
about f()’s behavior, but fixing that bug breaks h() who then files a new bug report, that can
only be fixed by breaking things for g(), etc. In the end, the only solution is splitting f()
into two separate functions f_a() and f_b() that do similar but slightly different things.
There is no easy way of finding design flaws, the best you can do is to take a step back and carefully consider the unstated assumptions that may exist about what a piece of code does and make sure to change those unstated assumptions to stated assumptions.
Similarly, there is no easy way of fixing design flaws. Depending on how big the issue is and how often the code gets called, it may require a big refactor.
The Third-Party Bug
The third-party bug is a bug that’s not in your code, but in someone else’s code that you happen to be using. You might think that the third-party bug shouldn’t be your problem because it’s not your fault! But guess what, if the bug is preventing your software from working, it is your problem. Sucks to be you!
Third-party bugs fall into a variety of different categories:
- There might be a genuine bug in the third-party library that you are using.
- You might be using the library in the wrong way, so actually, it is your fault.
- The documentation for the third-party library might not be very clear about exactly how it’s supposed to behave in certain situations, making it unclear if there’s a bug or not. The makers of the third-party library might not even know.
When it comes to fixing third-party bugs, there are three possible situations you can find yourself in:
- The creators of the third-party library respond quickly to the bug report and help you resolve the situation.
- The creators are not really that responsive, but you have the source code to the library, so you can try to diagnose what is going on and fix it yourself.
- The creators are not responsive and you don’t have the source code, you are essentially dealing with a black box.
When it comes to The Machinery, we try to be in category 1. In addition, if you have a Pro license, you also have the source code.
If you’re in the second case where you have the source code but little or no support, you’re faced with the task of understanding how somebody else’s source code works. This can be anywhere from relatively easy to crazy hard depending on the state and quality of that code. It’s also its own special kind of skill that you can get better at with time.
The third case can be extremely frustrating. If you are faced with trying to debug a black box, the only thing you can do is to try to poke it in various ways to see what happens. If you are lucky, you might be able to make an accurate enough mental model of the black box to fix the bug. Maybe some of the flags don’t work the way the documentation says they work. Maybe the function crashes on certain types of input. Perhaps you can write a little loop that calls the black box with all kinds of different values to figure out what triggers the issue. Good luck!
The Failed Specification
Guess what, sometimes you are the third party. Oh, how the tables have turned!
Of course, when you wrote the function that somebody else is calling, your perspective completely changes. Instead of an inscrutable black box that reacts in completely incomprehensible ways to perfectly sensible input, you now see an army of ignorant users calling your functions in the wrong order with a combination of parameters that make no sense at all.
But if you want to be a successful library writer, you shouldn’t regard this as just a user error. Instead, you should view it as a failure of communication. You failed to communicate to the users how to properly use your API.
What can you do about that? You can provide better documentation or working code samples that show how to use the API.
But even better is to design the API to prevent misuse, or at least, make sure that misuse results in a decipherable error message.
How do you design to prevent misuse? Make sure that each function has a clear, single purpose that is easy to understand. Don’t have functions completely change behavior based on what arguments/flags are passed in. Avoid designs that require functions to be called in a certain order or that require the system to be in a certain “state”. Of course, these things can’t always be avoided, but minimize them as much as you can. Make use of the type system to prevent your API from being used in the “wrong” way.
Let’s look at an example:
// Begins a profiling scope.
void profiler_begin_scope(const char *name);
// Ends a profiling scope started with [[profiler_begin_scope()]].
void profiler_end_scope();
Looks decent, but there is a potential for misuse. What if someone calls profiler_end_scope()
without having started a scope first.
// Begins a profiling scope.
profiler_scope_t profiler_begin_scope(const char *name);
// Ends a profiling scope started with [[profiler_begin_scope()]].
void profiler_end_scope(profiler_scope_t scope);
Here we require the user to pass in an identifier for the scope. Note that from the profiler’s
point of view, this isn’t strictly necessary. The profiler could keep track of any scope-related
data on an internal stack. But by requiring the scope parameter, the user can’t just call
profiler_end_scope() without calling profiler_begin_scope() first. And if the user calls:
profiler_scope_t p = profiler_begin_scope("update");
without a matching profiler_end_scope(), the compiler will give a warning about an unused
variable p.
Also, inside the profiler, we can add runtime checks (asserts) that trigger if the identifiers
passed to profiler_begin_scope() and profiler_end_scope() don’t match up.
Finally, it’s always good to give users the source code so that they can debug the problem themselves. Even if you are building proprietary, commercial software, consider having some way of sharing source with your advanced users. It will make your support easier and usually, the risks are low (even when there are big public source code leaks it doesn’t seem to adversely affect the companies much).
The Hard-To-Reproduce Bug
The standard debugging technique depends on us being able to reproduce the bug so that we can look at it in the debugger. This fails right away if we can’t reliably reproduce the bug.
When dealing with hard-to-reproduce bugs, the best first step is to try to increase the reproduction rate. Sometimes you can do this by stress-testing the system. Do you suspect a bug in the threading system? Maybe if you spawn 10,000 threads you can increase the likelihood that the bug will appear. Does the bug sometimes happen when you open or close a window? Maybe if you make your update function open and close 1,000 windows every frame, you will trigger the bug quicker.
If you are unable to get the reproduction rate high enough that you can debug the issue on your local machine, a second tactic is to try to collect as much information as possible when the bug does occur. This typically involves printing or logging some data and making sure that data gets sent to you. Either manually, by people who are able to reproduce the bug, or automatically, whenever the bug occurs.
Exactly what data you should send, depends a lot on what bug you are trying to fix. Basically, you want to send enough information that you can figure out where your mental model of the code goes wrong. This may involve several runs of back-and-forth where you add some debug printing, get error logs back, realize this is still not enough to tell you what is going on, add more printing, etc.
A good starting point is to print stack traces. This will tell you in broad strokes how the computer got there.
Another thing that can be useful is to add code to detect when the bug has happened. If you need to log a lot of debugging information, you might not want to do it all the time. The logs might become really large and the logging might slow down the execution of the program. To prevent this, instead of logging to disk, you could just log to a fixed-size circular buffer in memory. When you detect that the bug has occurred, you write out the content of this buffer. If the bug is an access violation or some other kind of crash, you may need to use structured exception handling to detect it.
Another tool to be aware of is remote debugging. Remote debugging is when you connect your debugger to a process on a remote machine. I don’t find remote debugging super useful in general, because it can be hard to coordinate a debugging session with a remote location. But there are some situations where it can be helpful, for example, to investigate what is happening on a production server. Also, if you are developing for a non-desktop platform, such as a phone, an integrated circuit, or a game console, all debugging sessions will be remote debugging sessions, since you can’t run a local debugger on that hardware.
The Statistic
When you start to have a huge number of users and those users generate a huge number of bugs, there eventually comes a point where it becomes impractical to look at every single bug that occurs. What do you do when you can’t do a qualitative analysis of every single bug? You have to turn to quantitative analysis — or statistics.
The goal of quantitative bug analysis is to:
- Automatically gather all bugs that occur and
- find out which the most important ones are so that
- you can focus your debugging efforts on them.
Unfortunately, statistics can’t fix the bugs for us, all it can do is to point us to the bugs that are most important to fix.
It’s important to set up automatic bug gathering because most end-users will not bother to report bugs to you. Only people who want to use your software and believe in your ability to address its issues will bother to make the effort of writing a bug report. It’s important to keep that in mind if you’re ever tempted to be rude or dismissive when replying to a bug — the people reporting bugs are doing you a favor.
Your automatic bug reporting system will probably be limited to a few obvious bugs, such as crashes or memory leaks. For more subtle bugs, such as “the uniform in the first cutscene was not available in that color until 1942” you will still have to rely on manual bug reports.
To find the most important bugs, you want to know:
- How many users are affected by the bug?
- How often does the bug occur?
To answer these questions, you first have to figure out what is meant by “the bug”. I.e., how do you know when two of these automatic bug reports refer to the same bug? There is no surefire way. I think the best approach is to group bugs by stack trace + error message. This is not guaranteed to work. For example, it could be possible to reach the same faulty code through two different paths in which case the stacks would be different even though it’s the same bug. And some bugs (e.g., memory overwrites) tend to crash all over the place so they will generate a lot of noise in the system. But I think it’s the best we can do.
Once you have identified the important bugs, you need to fix them. This can be tricky because you have no information about what the user did to cause the crash. Some high-level logging, similar to the strategy for hard-to-reproduce bugs can be useful to get context. You can also have the bug report include a memory dump so that you can inspect the state of the system when the crash occurred.
The Compiler Bug
A compiler bug is when you wrote your code correctly, but the compiler did not generate the right machine code for it because of an error in the compiler.
Some people will confidently state that “it’s never a compiler error”. This comes from bad communication patterns where junior programmers get overzealous in blaming the compiler for their own mistakes and jaded seniors reply “It’s not the compiler. It’s never the compiler. Fix your code.” In this case, everyone would benefit from approaching the situation with a bit more humility and empathy. We’re all in this great big world together.
It’s true that compiler bugs are rare. Much, much, much, much rarer than other bugs. So they should never be your first go-to. Only suspect a compiler bug when you’ve exhausted the other options.
But compiler bugs do happen. Compilers are software and as programmers, we know better than anybody else that all software comes with bugs. I don’t run into them often. Maybe once every six months or so, hard to say exactly.
How do I know for sure that they were compiler bugs and not problems in my own code?
Well, sometimes the compiler actually tells you and that makes it pretty cut-and-dry. For
example, in Visual Studio, you will get the dreaded fatal error C1001: Internal compiler error.
That’s a compiler bug if I ever saw one.
Unfortunately, not all compiler bugs give this clear-cut error message. Sometimes they just generate the wrong code. How do you know in this case if you’re dealing with a compiler error or something else? Well, you can try:
- Compiling the code with a different compiler. (VS/llvm/gcc)
- Changing the optimization settings.
If that makes the bug go away, you might be dealing with a compiler bug. But it’s still not 100 % certain. For example, the bug could be caused by uninitialized stack variables and when you switch compiler or change optimization settings, that data might just happen to end up being zeroed and the bug goes away.
The only way to know for sure if you are dealing with a compiler bug is to look at the assembly generated by the compiler. I think that in this day and age, learning how to write assembly is usually not necessary for a systems programmer. But learning how to read assembly and especially to understand how C code is translated to assembly can be very useful. If you can see that the compiler is generating the wrong assembly, you can start to blame the compiler. A good learning tool is the Godbolt compiler explorer.
But even with looking at the assembly, you still need to be careful. Modern C and C++ compilers make use of undefined behavior in the language to optimize the code. I.e., they assume that undefined behavior will never happen because if it did, the compiler is technically allowed to do whatever it wants anyway. This can sometimes allow the compiler to remove whole swaths of code.
For example, this code:
int foo (int x) {
return (x + 1) > x;
}
When compiled with -O2 compiles into just:
foo(int):
mov eax, 1
ret
I.e., the function always returns 1. This is because overflowing an int is an undefined behavior,
so the compiler assumes that it doesn’t happen and if the int doesn’t overflow, then x + 1 is
always bigger than x.
In contrast, if you compile the same code without optimizations, the generated code will actually
perform the addition and the comparison. In this case foo() will return 0 when called with
INT_MAX.
You can discuss whether this use of undefined behavior for optimization is a good thing or not. Personally, I’m skeptical. I think doing a more literal translation of what the programmer wrote helps with predictability, which is good for programmers, even if the code runs a little slower.
But, this is the world we live in, so you have to be aware of optimizations the compiler might make around undefined behavior. Before you blame the compiler, even when looking at the assembly, you have to make sure that there’s no lurking undefined behavior that would make it legal for the compiler to generate that code.
If you do run into an actual, real compiler bug, what do you do?
You can report the bug of course, but it will probably take a long time until any fixes make their way back into the compiler you are using and, in the meantime, your code is not compiling. So again, what can you do?
The only way I’ve found to deal with compiler bugs is to slightly massage the code until it starts working. Most compilers go through a lot of testing so when they fail it’s usually not a single thing that fails, but some complex interaction of inlining, optimizations, etc. In my experience, it’s hard to tell exactly what is triggering the failure. So I just move the code around a little… change the order of some operations… write things a little differently. It can be frustrating because I have no idea what will work, but eventually, I hit on something that does and the code starts working again.
Did I Forget Anything?
Did I forget your favorite kind of bug or your favorite debugging technique? Let me know in the comments!