API Versioning
The plugin API system is one of the central pieces of technology in The Machinery. Plugins can use it to call APIs defined in the engine, call APIs from other external plugins, or expose APIs of their own. The Machinery is essentially just a collection of plugins collaborating through these interfaces.
I’ve written about the plug-in system before:
Today, I want to focus on a new feature that I’ve been working on for the 2021.9 release: API versioning.
Motivation
Versioning is needed for plugins to deal with changes to other plugins. For example, suppose the engine has this API (APIs in The Machinery are structs with function pointers):
struct tm_engine_api { // v1
void *(*allocate)(uint64_t size);
};
and you use that in your plugin:
struct tm_engine_api *tm_engine_api = reg->get("tm_engine_api");
thing_t *p = tm_engine_api->allocate(sizeof(thing_t));
You compile your plugin to a DLL that gets used by thousands of happy users. Then, one day, we decide to change our API to add tags to allocations:
struct tm_engine_api { // v2
void *(*allocate)(uint64_t size, const char *tag);
};
Users who use your DLL with our new engine version will now have the allocate() function called
with the wrong number of parameters. This won’t result in any helpful error message, because
there’s no runtime check that a function is called with the right number and type of parameters
— all those checks happen at compile time. Instead, the function will just try to get the
parameters from the stack, get some garbage values back and most likely crash horribly.
You can fix this by compiling a new version of the DLL, fixing all the Not enough parameters for function allocate() compile errors you get and then try to get that new DLL out to the users as
soon as possible.
But it’s kind of annoying that the crashes even happen in the first place. It’s also annoying that you have to tell the users to use the right version of the DLL with the right version of the engine or everything will crash.
And there might be many reasons why you can’t just compile a new version of your DLL at the drop of a hat. Maybe you have other stuff to do? Maybe you have moved on to greener pastures? Maybe your DLL depends on some other DLL and you have to wait for that DLL to upgrade first. For users, trying to puzzle together a working application from DLLs of different versions can quickly become a nightmare (known as dependency hell).
This is not a great situation. What we would like instead would be something like:
-
As far as possible, the engine should be backward compatible with older DLLs. I.e., a DLL compiled for an older version of the engine should continue to run on the new version.
-
If we can’t do that, we should at least fail gracefully instead of bringing the whole editor down. This would mean showing an error message, saying something like “plugin XXX was compiled for an older version of the engine” and then disabling the plugin before it can do any damage.
If we can solve this, we can continue to evolve the engine rapidly without constantly breaking everybody’s projects.
Backward compatibility
To preserve backward compatibility, we must make sure that whatever changes we make to an API does not cause any problems for a plugin that was compiled against an older version of that API.
We could achieve this by not changing the API at all, but that’s not very interesting. We want to change the API, to add new features, fix bugs, and adapt the code to new use cases. Being flexible and easy to change is the most important property of code. Code that can’t change is doomed to die.
So let’s look at what changes we can make.
For binary compatibility between different versions of DLLs and executables, what matters is not the API (the definitions in the header file), but the ABI (the Application Binary Interface) — the binary layout of structs and function parameters. As long as the changes we make to the API do not change the ABI, everything is good.
This can be a bit tricky if you are not used to thinking and reasoning about the ABI, so let’s look at some examples:
struct tm_my_api { // v1
void (*f)(uint32_t x);
};
struct tm_my_api { // v2
void (*f)(uint32_t y);
};
Old code calling v1 of this API will still work with v2. It doesn’t matter that we changed the name of the parameter because the name isn’t a part of the ABI. In compiled code, we don’t reason about the names of function parameters, only about how they are passed (in registers or on the stack). Even though the names differ, code using v1 will put the parameter in the place where v2 expects to find it.
In fact, the name of the parameter doesn’t even appear anywhere in the compiled code (it’s saved in the PDB though, so the debugger can use it).
The same is true for fields in structs:
struct bla { // v1
uint32_t people;
uint32_t cats;
};
struct tm_my_api { // v1
void (*f)(struct bla bla);
};
struct bla { // v2
uint32_t number_of_people;
uint32_t number_of_cats;
};
struct tm_my_api { // v2
void (*f)(struct bla bla);
};
tm_my_api (v1) and tm_my_api (v2) are still binary compatible. In the ABI, the struct fields
have no names, just byte offsets. The caller puts the number of people at a certain byte offset in
the struct and the callee looks for the number of people at that same offset. It doesn’t matter what
the struct fields are called.
Renaming the function pointers in the API struct is safe too. They are just fields in the API structs, so the same thing applies to them. As long as the same function is found at the same offset in the API struct, it doesn’t matter what it’s called.
Note: This is true for function pointers in a struct, but it’s not true for exported functions. If you export a function from a DLL with
__declspec(dllexport), the name of the function gets saved in the DLL so that it can be retrieved byGetProcAddress()ordlsym(), but since the plugin system in The Machinery is based around API structs with function pointers rather than exported symbols, I won’t dwell on this further.
Let’s look at a change that would cause problems:
struct bla { // v2
uint32_t cats;
uint32_t people;
};
Here we have switched the order of the fields in the struct. The first four bytes of the struct
data, at offset 0, are now interpreted as the number of cats while the next four bytes, at offset
4, are interpreted as the number of people. A caller that was compiled for v1 of the API would
put the people count in the first 4 bytes and the cats in the last 4 bytes. If that caller was used
with v2 of the API, the callee would see the value that the caller put in the people field in the
cats field and vice versa. Effectively, we have transformed people into
cats.
Let’s recap quickly:
- Safe: Changing the name of struct fields and/or function parameters.
- Unsafe: Changing the order of struct fields and/or function parameters.
- Unsafe: Changing the types of struct fields and/or function parameters.
- Unsafe: Adding or removing struct fields and/or function parameters.
Another safe thing we can do is make use of unused bits and bytes in the struct, as long as we know they have been zeroed. For example, suppose we have:
struct bla { // v1
const char *name;
// Must be zero
uint32_t reserved;
};
We can now do:
struct bla { // v2
const char *name;
float height;
};
Hey now, this doesn’t look very safe. We changed the type of the reserved field from uint32_t
to float and didn’t I just say that we can’t change the types of fields?
But in this case, it actually works. Both unit32_t and float have the same size and alignment,
so they end up at the same position in the struct. The only allowed value for reserved in v1 is
0, which is represented in memory as four zero bytes: 0 0 0 0.
So if v2 gets called from v1, it will find four zero bytes in the height field: 0 0 0 0. But
these four bytes are also a valid value for a float. In fact, they represent the floating-point
zero: 0.0f. (Making sure that setting all the bytes of a data structure to 0 results in a good
default value is a good idea generally.)
So as long as the code in v2 has been written to handle the case where 0.0f is passed in the
height field (which it should be since the whole goal here is to maintain backward
compatibility), everything will work out fine.
If you expect that you will need more data in a struct in the future, you can pad it with
reserved fields so you have somewhere to put that data when the time comes. You can find lots of
examples of this in the Microsoft APIs, for example, the
WIN32_FIND_DATA
structure has two reserved fields called dwReserved0 and dwReserved1.
Personally, I’m not a huge fan of this approach. First, I find it aesthetically displeasing. Second, anticipating future needs is really hard. How do you know which structs are going to need more fields in the future and which aren’t? How many bytes of reserved data should you put in? 4? 8? 128? Third, this has the danger of running into Hyrum’s Law.
Hyrum’s Law says that if your API has enough users, it doesn’t matter what your documentation says. Any observable behavior of your code will be depended on by somebody.
You said the reserved field had to be zero, right? But did you actually check it? And did you
crash if it wasn’t zero? Because if you didn’t, you know some user will have called it with
garbage data instead of zero:
// Bla is created on the stack, contains random data.
struct bla bla;
// bla.name is set to a reasonable value, but bla.reserved
// is still uninitialized.
bla.name = "Niklas";
tm_my_api->f(bla);
This works fine in v1 of the API since we didn’t really use the reserved field for anything.
But in v2, this passes random data in the height field which will likely lead to unexpected
behavior.
How you look at this situation depends on how you feel about backward compatibility. You could say
that any developer who passed random data in the reserved field was using the API wrongly and
doesn’t deserve backward compatibility in the first place. It’s their fault if the code crashes
in a future version and you take no responsibility for it. We can call that the Apple approach.
Or, you can say that you value backward compatibility above everything else. Since some apps have
been passing garbage data in the reserved field and you don’t want to crash those apps you can
now never use the reserved field for anything. It will just have to sit there unused in your API
for all eternity. We can call that the Microsoft approach.
Another “prepare for the future approach” that you can see in Microsoft APIs is to have a size field specifying the size of the struct:
struct bla { // v1
// Must be set to sizeof(struct bla).
uint32_t size;
const char *name;
};
struct tm_my_api { // v1
void (*f)(const struct bla *bla);
};
struct bla { // v2
// Must be set to sizeof(struct bla).
uint32_t size;
const char *name;
float height;
};
struct tm_my_api { // v2
void (*f)(const struct bla *bla);
};
Here, the first field of bla specifies the size of the struct. When f() receives a struct, it
can check this value to figure out if a struct bla (v1) or a struct bla (v2) was passed and act
accordingly. Note that for this to work, we must pass the struct as a pointer to f(), because
if we passed it by value, the stack layout would depend on the size of the struct.
You can see the use of a dwSize field for this purpose all over the Microsoft APIs, for example
in
PROCESSENTRY32.
There’s nothing magic about using the size of the struct for this purpose. You could use anything
that makes it possible to identify specific versions of the struct. For example, you could have an
explicit version number. But using the size is kind of convenient since it changes automatically as
you add new stuff and you don’t have to figure out what version number to use. You can just type
sizeof(struct bla) and you will always get the right value.
Note: If you forgot to put in a version number and realize you need one later, you might be able to reuse some bits for that purpose. Find a bit that a v1 caller would never set (for example, the highest bit of a size field) and set that to
1to mean v2 or later and then of course add a version number, so you don’t have to resort to tricks like that again.
Again, I’m personally not a huge fan of the dwSize field approach that Microsoft uses. I can
see the value when you want to maintain backward compatibility at all costs, but I find it ugly to
have .dwsize = sizeof(BLA) all over the code.
A final observation about this. The dwSize field is needed when you want to pass a struct
pointer into an API function. However, if the API returns a struct pointer, you can actually do
without it:
struct foo { // v1
const char *name;
};
struct tm_my_api { // v1
struct foo * (*f)(void);
};
struct foo { // v2
const char *name;
float height;
};
struct tm_my_api { // v2
struct foo * (*f)(void);
};
Consider here what happens if the v1 code runs against the v2 interface. We will get back a pointer
to a block of memory containing a v2 struct. The first bytes of that block are identical to the v1
struct. After that, we have some extra data (the height field), but the v1 code doesn’t know
about this data and won’t care if it’s there or not.
Since the APIs in our plugin system are structs returned by pointers, the same is true for them:
struct tm_my_api { // v1
void (*f)(void);
};
struct tm_my_api { // v2
void (*f)(void);
void (*g)(void);
};
Code that is written for this v1 API will work just fine with the v2 API. It will find all the v1
functions at the expected position in the struct tm_my_api * (v2) and doesn’t care that there
are additional functions at the end of it. So we can add new functions to an API without breaking
backward compatibility, which is really nice.
In fact, our APIs also have a certain amount of forward compatibility. When we register an API,
we copy the API struct to a memory block that has some extra space initialized to zero. This means
that if code that has been compiled for v2 runs against the v1 ABI, tm_my_api_v2->g is guaranteed
to be NULL. The code can check for this to determine if it’s running against the v1 or v2
version of the ABI.
Let’s summarize all we have learned:
- Safe: Changing the name of struct fields and/or function parameters.
- Unsafe: Changing the order of struct fields and/or function parameters.
- Unsafe: Changing the types of struct fields and/or function parameters.
- Unsafe: Adding or removing struct fields and/or function parameters.
- Safe: Repurposing unused bits and bytes in structs, as long as they are zero-initialized.
- Safe: Changing the layout of structs passed as pointers, as long as we have a way of distinguishing different versions of the struct (e.g. a
sizefield). - Safe: Adding fields at the end of structs returned as pointers.
- Safe: Adding functions at the end of API structs.
Breaking backward compatibility
As we saw above, it’s possible to modify an API without breaking backward compatibility, but it comes at a cost. We must be careful about what changes we make. Over time, the API will tend to acquire more and more “cruft” — stuff that’s just there to provide backward compatibility for older users.
So there’s a tradeoff to be made here. We can either prioritize stability or we can prioritize rapid development and being able to easily change and refactor the code. There’s no right answer. Down one path lies the trap of stagnation and obsolescence, down the other you run the risk of annoying your users with constantly breaking changes.
The tradeoff might change during the lifetime of the API too. In the beginning, when the API is new and doesn’t have many users, it might be more important to focus on development speed and being able to fix any design mistakes. Later, when the API has matured and has more users, stability is more important. It also depends on whether the API is internal — i.e., mostly used by your own code — or external and affecting other users.
We want an approach that supports both these modes of development.
My initial plan was to not have version numbers for APIs in The Machinery, but instead do something like this:
- While APIs are “under development” or “unstable” — we change them at will and do not promise anything about backward compatibility.
- When a particular API becomes “locked” or “stable” — we maintain backward compatibility by only adding new functions at the end of the API struct.
- If we need to break backward compatibility of a stable API — we do it by introducing a completely new API.
Say we’re working on the tm_ui_api for example. We could add new functionality to it by adding
functions at the end of the API. If we needed to change the parameters of a function, we could do
so by deprecating the old function and adding a new one at the end of the API:
struct tm_ui_api { // v1
...
void (*set_active)(tm_ui_o *ui, uint64_t id);
...
};
struct tm_ui_api { // v2
...
void (*set_active_v1)(tm_ui_o *ui, uint64_t id);
...
void *(*set_active)(tm_ui_o *ui, uint64_t id, tm_strhash_t active_data_format);
};
Note that this change is backward compatible. We’re not changing the parameters of the original
set_active() function, just its name, which is ok. And we’re adding the new set_active() at
the end of the API struct which is also OK. Also, note that we’ve complicated the API with some
cruft — an extra function for backward compatibility.
If we for some reason need to make a breaking change (hopefully that’s rare) we can do it by introducing a whole new API:
struct tm_ui_api {
// original layout
};
#define TM_UI_API_NAME "tm_ui_api"
struct tm_ui_api_v2 {
// new layout
};
#define TM_UI_API_V2_NAME "tm_ui_api_v2"
struct tm_ui_api *tm_ui_api = reg->get(TM_UI_API_NAME);
struct tm_ui_api_v2 *tm_ui_api_v2 = reg->get(TM_UI_API_V2_NAME);
For a time, the application can continue to expose both tm_ui_api and tm_ui_api_v2 until
tm_ui_api is deprecated and all clients are switched over to tm_ui_api_v2.
I still think this is a pretty decent plan. It maximizes backward compatibility and clients don’t have to deal with versioning (which is an extra burden). So what’s the problem?
The main issue is the “unstable” APIs. We kind of need them, because when we add a new API, we don’t want to promise stability from day one. We want to be able to experiment and explore the design space. This is especially true since a lot of users are working directly against our master branch and see every little change we make to the engine, not just fixed release points.
This means that if anyone uses one of these unstable APIs and we make a change to it, their plugin will just crash and bring down the whole editor. That’s not really a tenable situation. We could tell people to just not use any of the “unstable” APIs or we could wait with publishing them until they’re “done”. But that’s not a great approach either. We believe in iterative workflows, pushing early and often. We want the development of the engine to move fast, and we want to encourage people to experiment with it. It’s very valuable to have real users try out an API at an early stage to get feedback on it.
Versioning
So looks like we’re going to need versioning of APIs. This means:
- We assign a version number to each API.
- Any time the API changes, we update the version number.
- When you request an API, you specify which version of the API you want.
- If you request a version that’s not available, an error message will be printed and your plugin will be disabled. The same happens if the API doesn’t exist at all.
We have some additional requirements too. We want the system to be easy to use in the most common case (get the latest version), but support more advanced use cases when we need them. It should also support both forward and backward compatibility.
For version numbers, we’ll use the semver standard. Semver version numbers consist of three numbers: major, minor, and patch (e.g. 10.2.3):
struct tm_version_t {
uint32_t major;
uint32_t minor;
uint32_t patch;
};
The server standard also specifies how these numbers should be updated:
- If you make a breaking change to the API, you should increase the major version number (and set minor and patch to 0).
- If you add new functionality to the API in a backward compatible way, you should increase the minor version number (and set patch to 0). In our case, this usually happens when we add new functions at the end of the API.
- If you fix bugs in the implementation without changing the API, you should increase the patch version.
- When the major version is 0, the API is considered unstable. In this case, nothing is promised about backward compatibility.
For basic versioning support, we will just add version numbers to the functions that query for and register APIs:
tm_ui_api = reg->get(TM_UI_API_NAME, (tm_version_t){1,0,0});
reg->set(TM_UI_API_NAME, (tm_version_t){1,0,0}, tm_ui_api, sizeof(*tm_ui_api));
Many systems that work with version numbers allow for more complex queries. For example, you may
ask for >2.0.0 (any version greater than 2.0.0) or 3.1.* — requiring major version 3 and
minor version 1, but any patch number.
However, for our purposes, I don’t think such queries are necessary. What’s special about our system is that it uses binary versions shipped in an executable whereas many other versioning systems are created to work with source code modules stored on a server.
With source code modules, using a different major version than the one you requested might very well work — as long as you are not calling any of the functions that changed. And if you do, you will get an error message when you compile the final executable. In contrast, with binary versions, a major version mismatch will almost guarantee a crash, with no way of fixing it (unless you are the developer of the crashing plugin). So we really want the major version to match exactly what the user asked for.
When it comes to minor and patch versions, since APIs with the same major version are backward compatible, there is really no point for a plugin/executable to export multiple APIs with the same major version (e.g. 2.1.0, 2.2.1, 2.2.2, etc). The plugin/executable can just export the latest one (2.2.2) and clients that ask for an earlier version (2.1.0) can just use that since it’s backward compatible.
If a client asks for a later minor version of the same major version (e.g. 2.3.0), I think the right thing to do is to fail the request. 2.3.0 may have some additional API functions that are not there in 2.2.0, and if the client asks for 2.3.0, we must assume that they might call those functions, which would crash on 2.2.0. So we fail the request with a message that 2.3.0 is not available.
What about the patch version? What should we do if the client asks for 2.2.2, but we only have 2.2.1. My mind is a bit split on this one. On the one hand, the client might depend on a bug fix that was done in 2.2.2 and crash under 2.2.1. On the other, maybe it’s better to run with the 2.2.1 than to not be able to run the client at all. For now, I’ve decided to fulfill the request in this case.
Since unstable APIs (major version 0) don’t promise anything about backward compatibility, a request for an unstable API will only succeed if the version matches exactly.
If a plugin fails to obtain an API that it depends on we want to disable that plugin. Let’s see how this can work in practice:
void load(tm_api_registry_api *reg, bool load)
{
tm_engine_api = reg->get("tm_engine_api", (tm_version_t){1,0,0});
tm_other_api = reg->get("tm_other_api", (tm_version_t){1,0,0});
reg->set("my_api", (tm_version_t){1,0,0}, &my_api, sizeof(my_api));
}
You might think that disabling the plugin could be implemented like this:
if (tm_engine_api && tm_other_api)
reg->set("my_api", (tm_version_t){1,0,0}, &my_api, sizeof(my_api));
But in The Machinery tm_engine_api will always be non-NULL, because we allow the get() and
set() calls to resolve in any order — i.e., set() can be called after get().
When get() is called we return a pointer to a pre-sized internal buffer filled with NULL values.
Then later, when set() is called, for the same API and version, that buffer gets populated with
the actual API struct through a memcpy().
So we can’t really check if get() was successful or not until we have loaded all the plugins
(and know all the set() calls that were made).
To do that, we can simply record all the get() and set() calls made by a plugin in the load
phase. When loading has completed, we go through all the get() calls that we recorded and check
if we were able to find matching APIs. If any of the get() calls failed, we print an error
message and disable the plugin. “Disabling” in this case, means just going through all the
set() calls that we recorded and undoing them — effectively removing the APIs from the
registry. In the example above, if the plugin was not able to retrieve tm_other_api, my_api API
will be removed.
Note that this can cause a cascading effect where one plugin gets disabled because it’s missing a dependency, which in turn causes other plugins to be disabled because they depended on that plugin, etc.
This is what it might look like when we get a cascade of dependency failures:
Disabling tm_application_api in libthe-machinery-dll.dylib (tm_dxc_shader_compiler_api 1.0.0)
Disabling tm_draw2d_api in libtm_ui.dylib (tm_application_api 1.0.0)
Disabling libtm_pong_tab.dylib (tm_draw2d_api 1.0.0)
tm_application_api was disabled because it couldn’t get the tm_dxc_shader_compiler_api. The
tm_draw2d_api in turn was disabled because it depends on the tm_application_api and then the
Pong Tab plugin was disabled because it uses the tm_draw2d_api.
To help diagnose dependency problems, I made a quick helper tool that can print the dependencies of
a plugin in GraphViz format. For example, here are the current dependencies of the tm_entity_api:
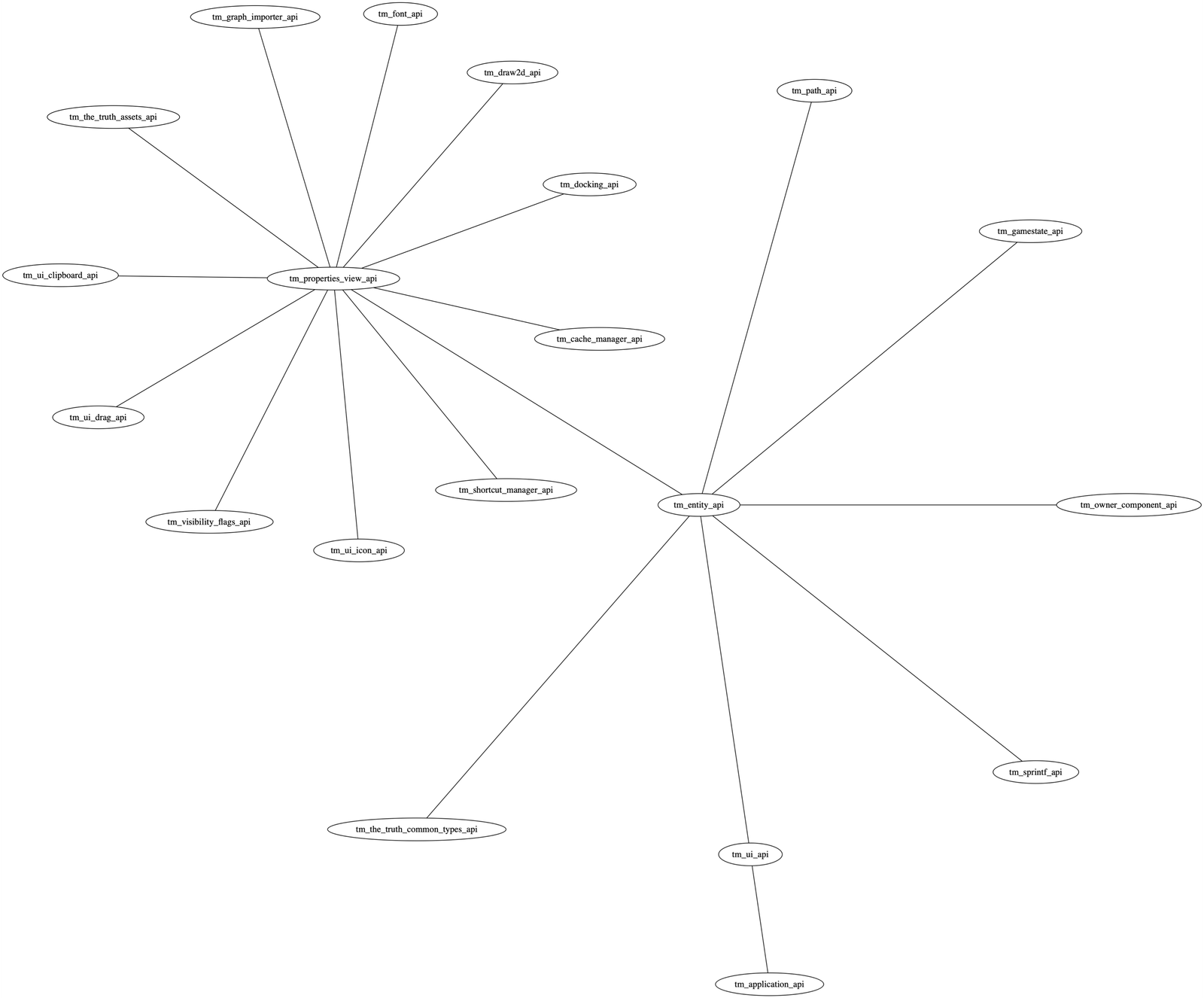
Dependencies of tm_entity_api.
If you are not careful, you can easily end up in situations where your API depends on everything, because it depends on something, that depends on something, that depends on something else.
To help break those dependency chains we have the concept of an optional dependency. An optional dependency means that your plugin will use the API if it’s there, but the plugin will still run even if it’s not:
reg->get_optional(&tm_other_api_opt, "tm_other_api", (tm_version_t){1,0,0});
Unlike get(), get_optional() doesn’t return the API pointer, instead, we pass in a pointer
to the API pointer. This lets the API registry patch the pointer in the set() and remove()
calls. So we can determine if the optional API has been loaded with a simple test of the pointer:
if (tm_other_api_opt)
tm_other_api_opt->foo();
Ergonomics
Being able to set() and get() specific versions of an API and handling errors is really all we
need for the versioning system to work. But I also wanted to do something to improve the
ergonomics of using this functionality.
When I’m talking about ergonomics of code I mean things that don’t really change the functionality but make the code easier to use and steers the user in the right direction. Let’s look again at our basic call for accessing an API. In context, it will look something like this:
static struct tm_engine_api *tm_engine_api;
// ...
tm_engine_api = reg->get("tm_engine_api", (tm_version_t){1,0,0});
There are multiple things that can go wrong here.
- The user may request the wrong version of the API. While there are legitimate use cases for requesting a specific, older version of the API (and we’ll talk more about that later), the typical case is that you want to compile your code against the current version of the API. If the user types in a manual version number there’s a chance they type the wrong thing. It can also be a bit of a chore to keep updating the version number (although you could argue that it’s good to make a conscious choice about what version you are depending on).
- The user may misspell the name of the API in the request. For example, a request for
tm_egine_apiwill fail. - Since C doesn’t have generics, the
get()call returns avoid *. The user must assign this to an API pointer of the right type. This is another possibility for mistakes.
None of these issues are super serious. It’s fairly easy to make mistakes, but the issues will be pretty obvious — the API will fail to load or you will get a crash as soon as you try to call something. Still, I think it can be useful to help the users a little bit. As programmers, we are constantly dealing with mental overload. Anything we can do to improve that situation is worth it.
For the first issue, we can simply define a macro that holds the current version number:
#define tm_engine_api_version TM_VERSION(2, 1, 0)
Now the call becomes:
tm_engine_api = reg->get("tm_engine_api", tm_engine_api_version);
We could do the same thing for ”tm_engine_api” and introduce a define tm_engine_api_name.
But since we want the name to always be the same as the name of the API, we can use the
preprocessor’s ability to stringify symbols instead:
#define tm_get_api(reg, TYPE) reg->get(#TYPE, TYPE##_version)
Which can be used like this:
tm_engine_api = tm_get_api(reg, tm_engine_api);
The # macro operator turns tm_engine_api into the string "tm_engine_api" while ##
concatenates the symbols tm_engine_api and _version into tm_engine_api_version. So the
preprocessor expands this into the same text as we earlier wrote by hand.
We can use this same macro to provide type safety too:
#define tm_get_api(reg, TYPE) (TYPE *)reg->get(#TYPE, TYPE##_version)
When expanded, this will cast the void * returned by get() into a tm_engine_api * . If the
type of the tm_engine_api variable doesn’t match, an error will be generated.
We have a similar macro for setting an API:
#define tm_set_or_remove_api(reg, load, TYPE, ptr) \
do { \
if (load) { \
struct TYPE *typed_ptr = ptr; \
reg->set(#TYPE, TYPE##_version, typed_ptr, sizeof(struct TYPE)); \
} else \
reg->remove(ptr); \
} while (0)
Here we assign ptr to a local variable typed_ptr to ensure type safety. We also use # and
## to generate the API name and version number as before. Finally, we use the same macro to both
set the API (when load is true) and remove the API (when load is false). This lets us
run the same code snippet for load and unload of the API, ensuring that the set() and remove()
calls match up.
I’m a bit of two minds when it comes to the use of preprocessor macros like this. I’m not a huge fan of macros that expand to huge globs of stuff. It makes it hard to read the code and figure out what’s going on. On the other hand, macros are the only way to get something akin to type-safe generics in C, so we kind of need them. And for things like this, a few well-chosen macros can reduce the amount of code we need by a lot and change things that would have been runtime errors into compile errors, which is always good.
Forward and backward compatibility
Let’s see how this solution works for forward and backward compatibility. We’ll assume that we
have a plugin API my_plugin_api that has been compiled against an engine API tm_engine_api of
version 2.1.0.
Compatibility with a new minor version
A new version of the engine is released. In this version tm_engine_api has version 2.2.0.
The compiled plugin will request 2.1.0 of the API. According to our rules, the 2.2.0 version that
the engine has is compatible, so the engine will return it. Since 2.2.0 is backward compatible, the
plugin will be able to call it the same way as it called 2.1.0 and everything will work
automatically.
Compatibility with an old minor version
In this case, someone takes our plugin — that was compiled for version 2.1.0 — and tries to run it with an engine that just has 2.0.0.
What happens here depends on what our plugin is doing. If our plugin is requesting the latest
version of tm_engine_api with a call such as:
tm_engine_api = tm_get_api(reg, tm_engine_api);
The version we’re requesting will be locked to the value that tm_engine_api_version has when we
compile our plugin, i.e. 2.1.0. This means that the call will fail with the older engine version.
The plugin is requesting 2.1.0 and the engine only has 2.0.0 available and according to our rules,
2.0.0 cannot be returned for a request for 2.1.0.
If you want to make sure that your plugin is compatible with older engine versions, you have to make sure to explicitly request the API from that version, even if a newer version is available. The easiest way of doing that is by using a header from that older version of the engine:
#include "engine_api_200.h"
tm_engine_api = tm_get_api(reg, tm_engine_api);
By including the older header rather than the current one, you get the tm_engine_api_version that
was used in that header (2.0.0). You also make sure that you don’t accidentally use any
functionality that was added in 2.1.0 (which would be easy to do if you included the latest
header). This is important because using those functions would crash when run against 2.0.0.
Compatibility with a new major version
Suppose a new version of the engine is released and in this engine, the API has version 3.0.0. Your plugin won’t work with this API, because 3.0.0 is not backward compatible with 2.1.0. Your only hope in this situation is that the developers of the API decided to provide backward compatibility with the 2.1.0 version. They could do that by publishing both a 2.1.0 and a 3.0.0 version of the API. But it’s up to them and what they want to prioritize. If their main focus is on developing new features, they may decide to just ship a 3.0.0 version and force everybody to recompile their plugins to work with the new version. If they are willing to put in the extra work to support backward compatibility they may export both 2.x.x and 3.x.x versions.
Similarly, you, as a developer of tm_my_api may decide if you want to ship multiple versions of
the API or not.
Compatibility with an old major version
Suppose that in addition to running on an engine that has the 2.0.0 API, you want your plugin to also work with engines that have the 1.0.0 API. You can achieve this by requesting both 1.0.0 and 2.0.0 and use whichever one is available.
struct tm_engine_api_100 *tm_engine_api_100;
struct tm_engine_api *tm_engine_api;
reg->get_optional(&tm_engine_api_100, TM_STRINGIFY(tm_engine_api),
(tm_version_t){1,0,0});
reg->get_optional(&tm_engine_api, TM_STRINGIFY(tm_engine_api),
tm_engine_api_version);
Note the use of get_optional() instead of get() here. We don’t want our plugin to fail if
1.0.0 is not available, since we’re fine with using 2.0.0. Similarly, we don’t want to fail if
2.0.0 is not available either, since we can do with 1.0.0.
Also note that in this case, we need a separate type struct tm_engine_api_100 to represent the
layout of the API struct as it looked in version 1.0.0.
Conclusions
I feel pretty happy with the way the version system came out. Though it adds a bit of complexity, by using the helper macros, users that just want to compile with the latest version can pretty much ignore the versioning system and still get the benefit of getting explicit errors if there is a version mismatch. At the same time, users who want to dig deep and make sure they are compatible with multiple versions can do so.