Borderland between Rendering and Editor — Part 2: Picking
In early March I wrote a post about the rendering of grids in our editor. Before we dive into today’s topic, I wanted to show off a trivial addition to the grid rendering I’ve added since the last post, rendering of an object local grid to guide moving of objects when snapping is enabled:
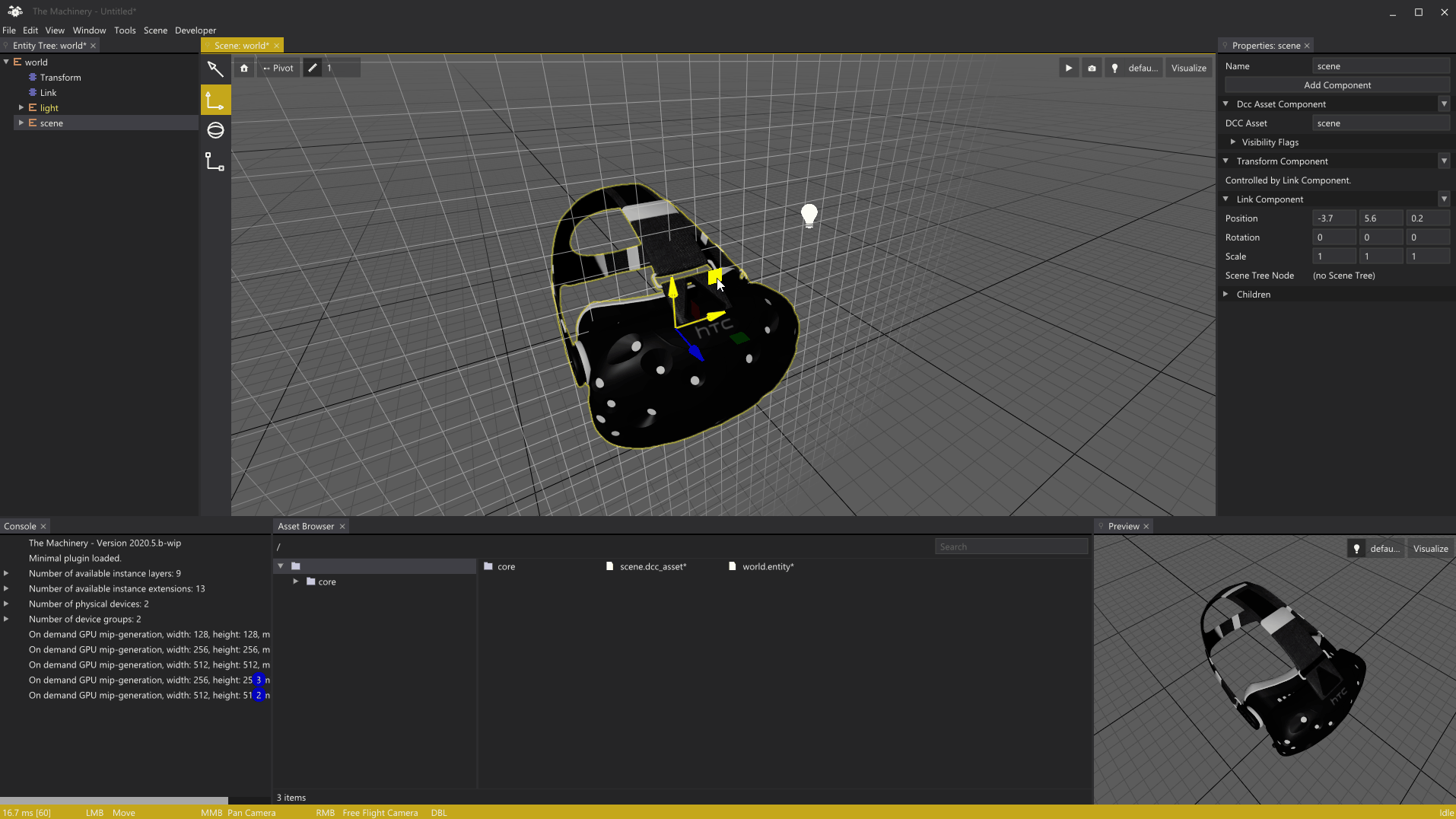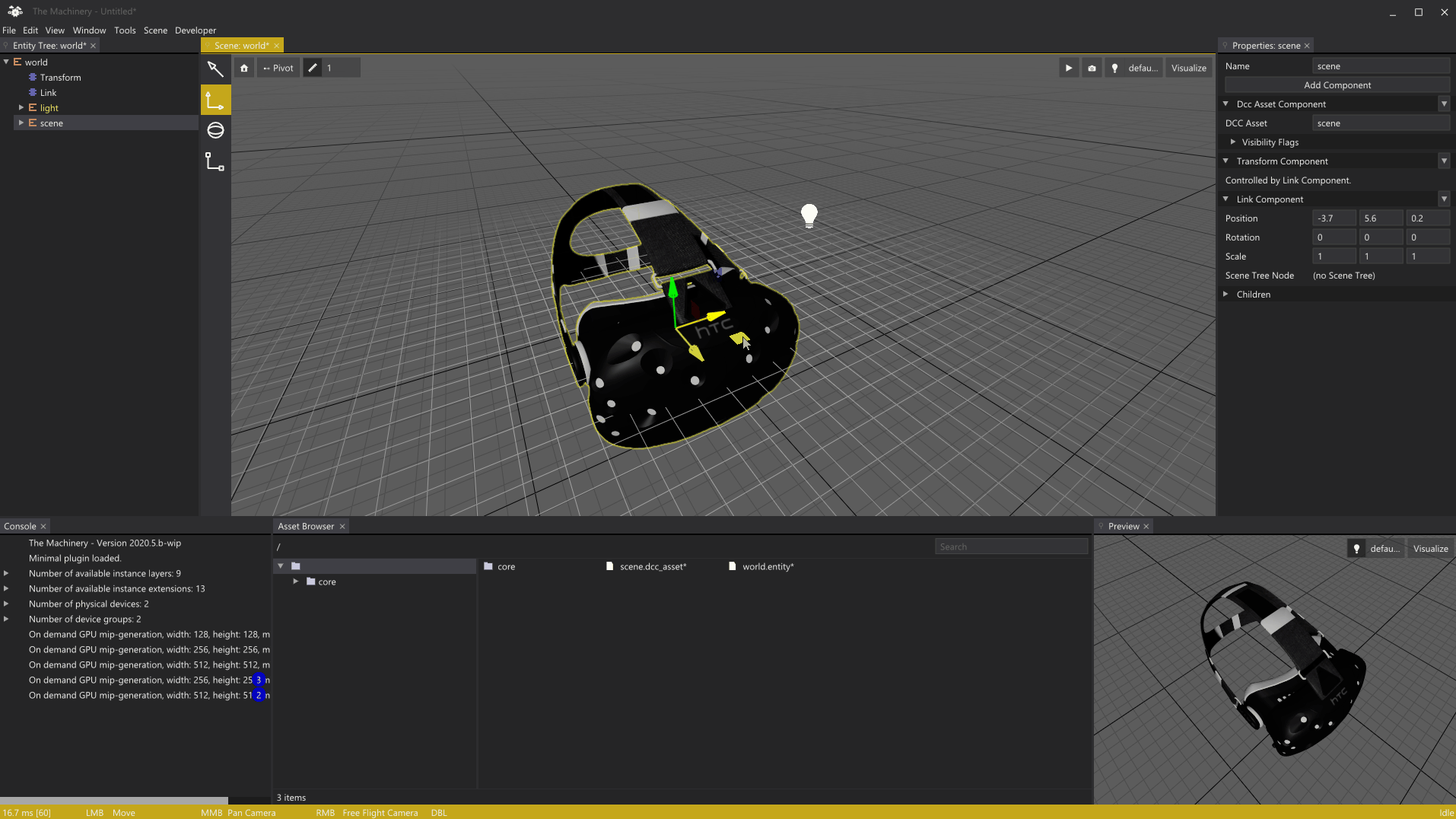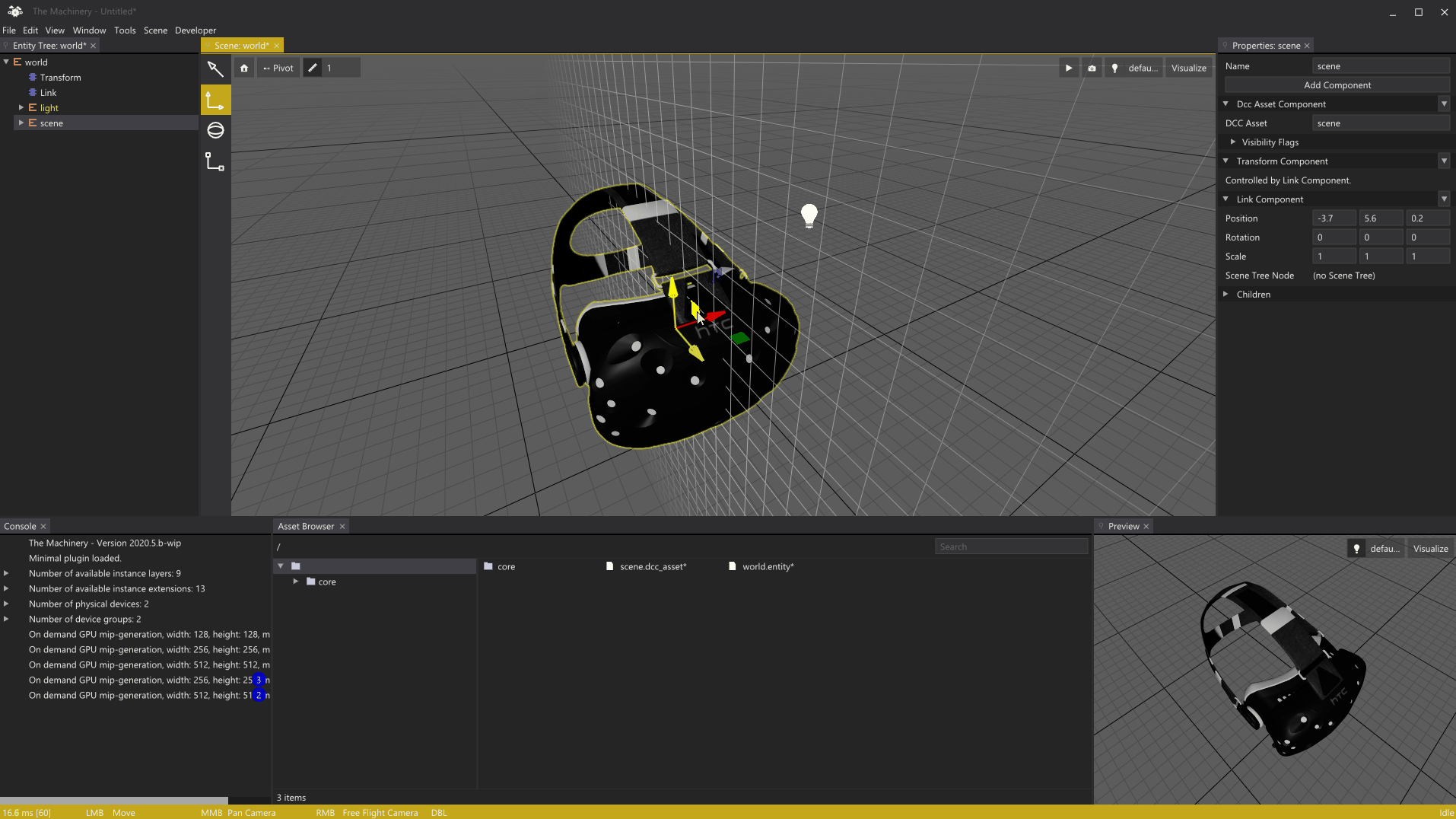
Local grid to guide snapping.
I think it turned out quite nice and it feels like a good example of how well the modularity aspects
of The Machinery work in practice — just query access to the tm_grid_renderer_api and add whatever
grid rendering your plugin might need.
Anyway, let’s move on. In today’s post, we’ll talk about mouse picking.
Picking — Background
All types of 3D-editors tend to need some way to determine the object identity of whatever object that happens to be under the mouse pointer when the user clicks inside a viewport. I’ll be referring to this process as “picking”.
Picking, just like grid rendering, is one of those problems that typically are considered too boring, or unimportant, for graphics programmers to even care about. Instead, it tends to end up in the lap of some tools programmer to come up with a solution in one way or another. Usually, by doing some form of ray cast from the position of the viewport camera through the mouse pointer coordinate projected on the camera’s near plane.
The two most common approaches to implementing picking that I’ve seen are:
- Reuse an already existing system for doing ray casting, like physics.
- Implement a special ray casting structure, only used for editor picking.
The whole situation with distinct silos between rendering and tools folks, the prima donna attitude among rendering programmers, and the two most common solutions to the problem are bad in so many ways it makes me wanna cry.
Relying on e.g. the physics system will break as soon as you need to pick stuff that doesn’t have a physics representation, and there are typically lots of objects rendered in a viewport that don’t need one. A common user workaround is to start adding physics representations just for the sake of making stuff pickable in the editor. Not ideal…
On the other hand, implementing a specific ray casting system only used for doing editor picking can be a significant amount of work. Sure, the implementation doesn’t have to be the fastest in the world since you will typically only be casting a single ray per frame (or less), but still, you’ll definitely need some kind of acceleration structure (like a BVH-tree) as you definitely want to pick against the actual rendered triangles and not some proxy. That structure will consume both memory and take some time to cook, and as soon as you start dealing with somewhat more complicated scenes with lots of objects (>10K) you’ll probably need to add another level of acceleration structure.
Not to mention the fact that neither of these approaches will likely handle picking against deformable objects (like skinned characters), or picking through alpha masked objects (e.g. in-between the leaves on a tree), or handle purely voxel-based objects, or any kind of “Nanite” -solution.
Clearly, this is not what you want. Even if it’s doable to implement a decent solution on the CPU, what you really want is a GPU based picking solution. You want to know the identity of the pixel under the mouse cursor, not the identity of some invisible proxy. The second you’ve worked with a pixel-perfect solution that handles all kinds of geometry deformations and surface types, you will never again be okay with anything that’s less accurate.
Ironically, implementing the foundations of a GPU-based picking solution is really straight forward, much easier than any CPU-based picking solution you can think of. So let’s take a look at the implementation we have in The Machinery.
GPU Picking — Implementation
First of all, our solution relies on a few prerequisites, so let’s get them out of the way as I won’t cover them in more detail in this post:
-
First of all, we rely on our shader system being able to efficiently select a different shader variation for all drawn objects in the viewport. We handle this using the “Systems”-concept described in this post.
-
Secondly, we rely on always running on hardware that supports binding Unordered Access Views (UAVs) to the pixel shader.
So the idea is very simple. When the user clicks inside a viewport, we activate a special shader
system called picking_system. That means that any shader that implements support for the
picking_system will activate a slightly different code path in the pixel (or compute) shader used
for rendering the object on screen.
The activated shader variation adds a call to update_picking_buffer() which is defined in the
picking_system. The actual picking buffer is something as silly as a 12 bytes buffer, bound as a
UAV, wrapping a simple struct:
struct tm_gpu_picking_buffer_t
{
float depth;
uint64_t identity;
};
A naive implementation of update_picking_buffer() looks something like this:
// `pos` should be SV_Position.xy (or comparable writing from a CS).
//
// `identity` is a unique identifier of the rendered object. In TM this is
// typically the ID of the entity issuing the GPU work.
//
// `z` is the Z depth value of the shaded point.
//
// `opacity` is the opacity value of the currenly shaded pixel.
void update_picking_buffers(uint2 pos, uint2 identity, float z, float opacity)
{
// If the opacity of the pixel is less than the "opacity picking threshold"
// -- return.
if (opacity < load_opacity_threshold())
return;
// If this pixel is not under the mouse cursor -- return.
uint2 cursor_pos = load_cursor_pos();
if (pos.x != cursor_pos.x || pos.y != cursor_pos.y)
return;
// Compare pixel z against the currently stored z-value in the
// picking_buffer. If it's greater or equal (behind) -- return.
uint d = asuint(z);
if (d >= picking_buffer.Load(0))
return;
// Update picking buffer.
picking_buffer.Store3(0, uint3(d, identity));
}
While this naive implementation will produce the correct picking result most of the time, it will
occasionally fail and return a picking result that is behind the closest surface. This is because we
need to protect against concurrent access to the picking_buffer.
We can use atomics together with exploiting the sign bit of d to implement a spinlock mechanism
that prevents concurrent updates to the picking_buffer from happening. The implementation is a bit
hairy, but looks something like this:
uint d = asuint(z);
uint current_d_or_locked = 0;
do {
// `z` is behind the stored z value, return immediately.
if (d >= picking_buffer.Load(0))
return;
// Perform an atomic min. `current_d_or_locked` holds the currently stored
// value.
picking_buffer.InterlockedMin(0, d, current_d_or_locked);
// We rely on using the sign bit to indicate if the picking buffer is
// currently locked. This means that this branch will only be entered if the
// buffer is unlocked AND `d` is the less than the currently stored `d`.
if (d < (int)current_d_or_locked) {
uint last_d = 0;
// Attempt to acquire write lock by setting the sign bit.
picking_buffer.InterlockedCompareExchange(0, d, asuint(-(int)d),
last_d);
// This branch will only be taken if taking the write lock succeded.
if (last_d == d) {
// Update the object identity.
picking_buffer.Store2(4, identity);
uint dummy;
// Release write lock.
picking_buffer.InterlockedExchange(0, d, dummy);
}
}
// Spin until write lock has been released.
} while((int)current_d_or_locked < 0);
With the spinlock-update in place, you should always be getting the closest surface in the picking buffer.
So that’s it on the shader side of things, now let’s move over to the CPU side and take a look at
the C-API we have in place for scheduling and reading back the result of the picking_buffer from
the GPU to the CPU. It’s called tm_gpu_picking_api and looks like this:
struct tm_gpu_picking_api
{
struct tm_gpu_picking_o *(*create)(struct tm_allocator_i *allocator,
struct tm_renderer_resource_command_buffer_o *res_buf,
struct tm_shader_system_o *picking_system,
struct tm_shader_o *clear_picking_buffer_shader);
void (*destroy)(struct tm_gpu_picking_o *inst,
struct tm_renderer_resource_command_buffer_o *res_buf);
bool (*update_cpu)(struct tm_gpu_picking_o *inst,
struct tm_renderer_backend_i *rb, bool activate_system,
const tm_vec2_t cursor_position, float opacity_threshold,
uint64_t *result);
void (*update_gpu)(struct tm_gpu_picking_o *inst,
struct tm_shader_system_context_o *context,
struct tm_renderer_resource_command_buffer_o *res_buf,
struct tm_renderer_command_buffer_o *cmd_buf,
uint32_t device_affinity_mask);
};
create() and destroy() are simply responsible for creating and destroying a picking object. Each
viewport that supports picking has its own tm_gpu_picking_o. Internally, tm_gpu_picking_o owns
the picking_buffer and some state.
update_cpu() is typically called every frame somewhere inside the UI/editor code and does two
things:
-
Checks if there’s a new read-back result available for the
picking_buffer. If so theidentitypart of thepicking_bufferis returned inresultand the function returns true. Object selection tracking in The Machinery is based on the entity ID so we can simply pass the entity ID as part of a constant buffer to all draw and dispatch calls which means that the returned value inresultcan be used directly without any additional lookup. -
If the user clicked the mouse button somewhere inside a viewport, true should be passed to
activate_systemtogether with the cursor position and an arbitrary opacity threshold. This prepares the state that will be passed to thepicking_systemthrough a constant buffer and queues it for activation. The opacity threshold controls at which surface opacity value a pixel should be clicked-through (i.e., rejected). I have plans exposing control over the opacity threshold in the editor but haven’t got around to it, right now we only pass 0.5 which feels like a decent default value. Any pixel with opacity less than 0.5 will be clicked through.
update_gpu() is called whenever we’re about to render a viewport. It does the following:
-
If the
picking_systemwasn’t activated when the last call toupdate_cpu()was made, it just returns immediately. -
Queues a compute dispatch call to clear the
picking_buffer, scheduled to execute before any other rendering happens in the viewport. -
Updates the constant buffer associated with the
picking_systemwith the mouse cursor position and opacity threshold passed toupdate_cpu(). -
Queues an asynchronous read-back operation of the
picking_bufferfrom the GPU to CPU, scheduled to run after all rendering has finished in the viewport.
As we don’t want to stall the GPU with the read-back of the picking_buffer, it can take a few
frames until the result is available and true is returned from update_cpu(). In practice though,
this delay hasn’t been noticeable from a user’s perspective.
Here’s a gif-animation showing the picking system in action:
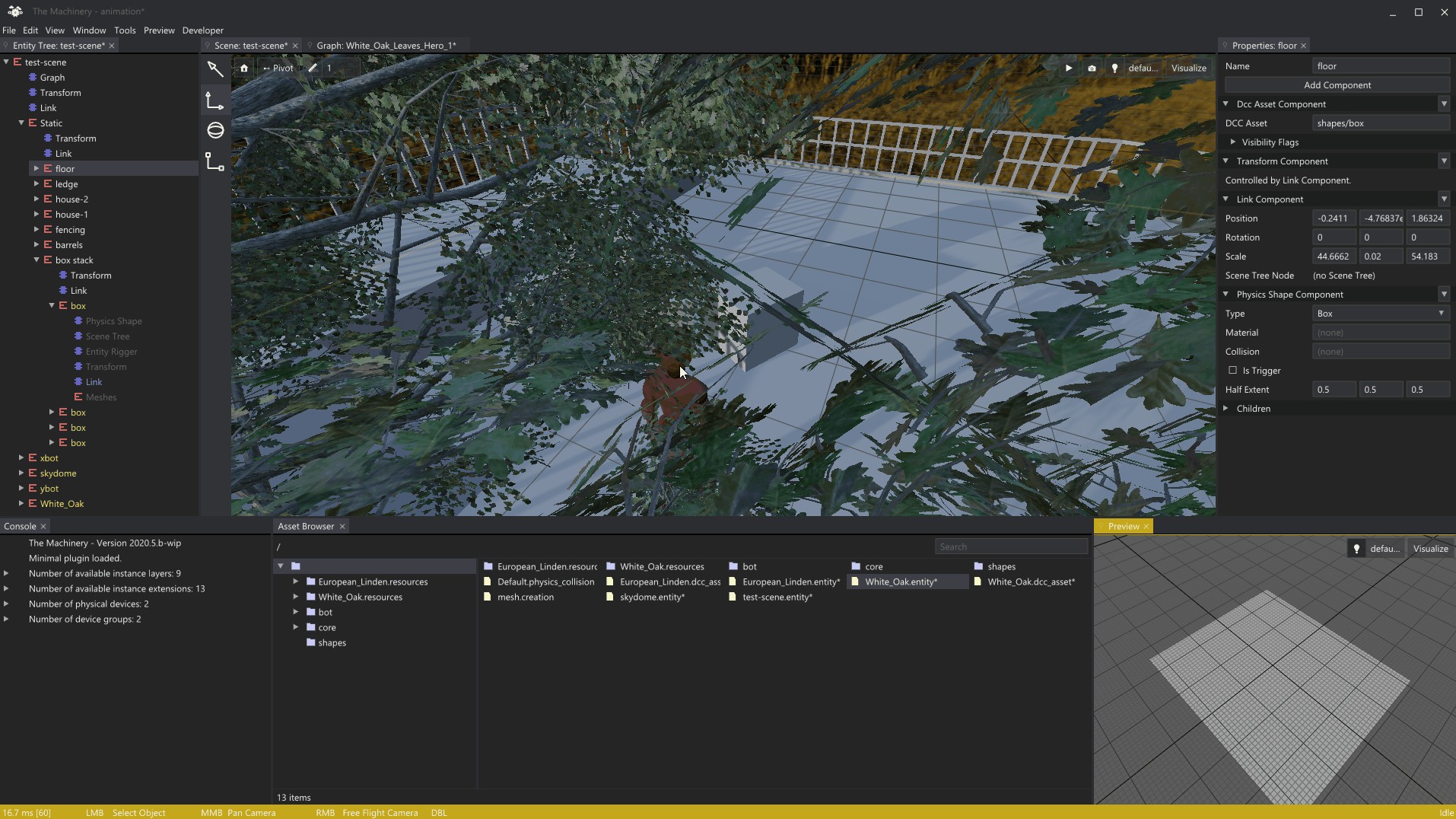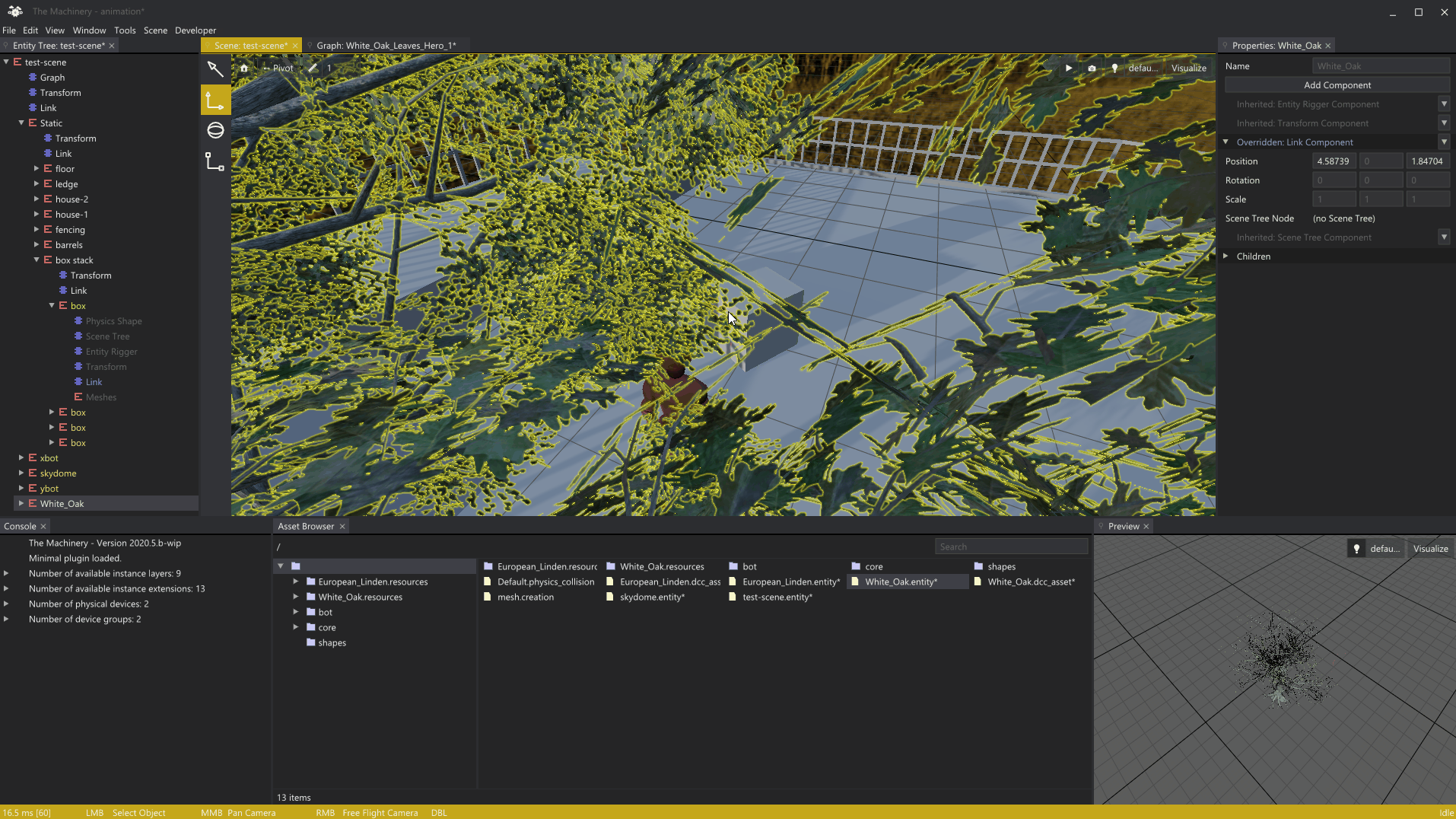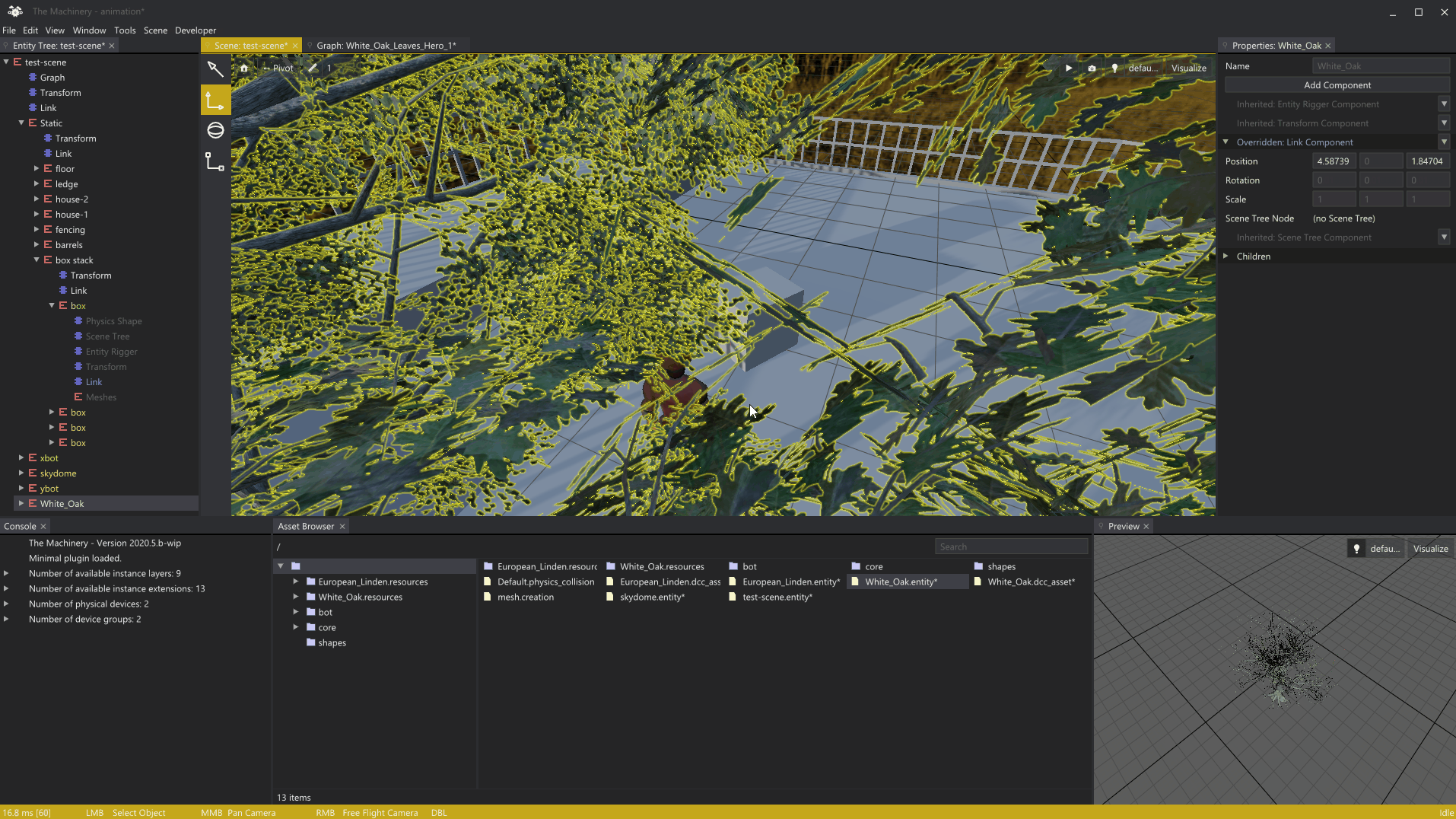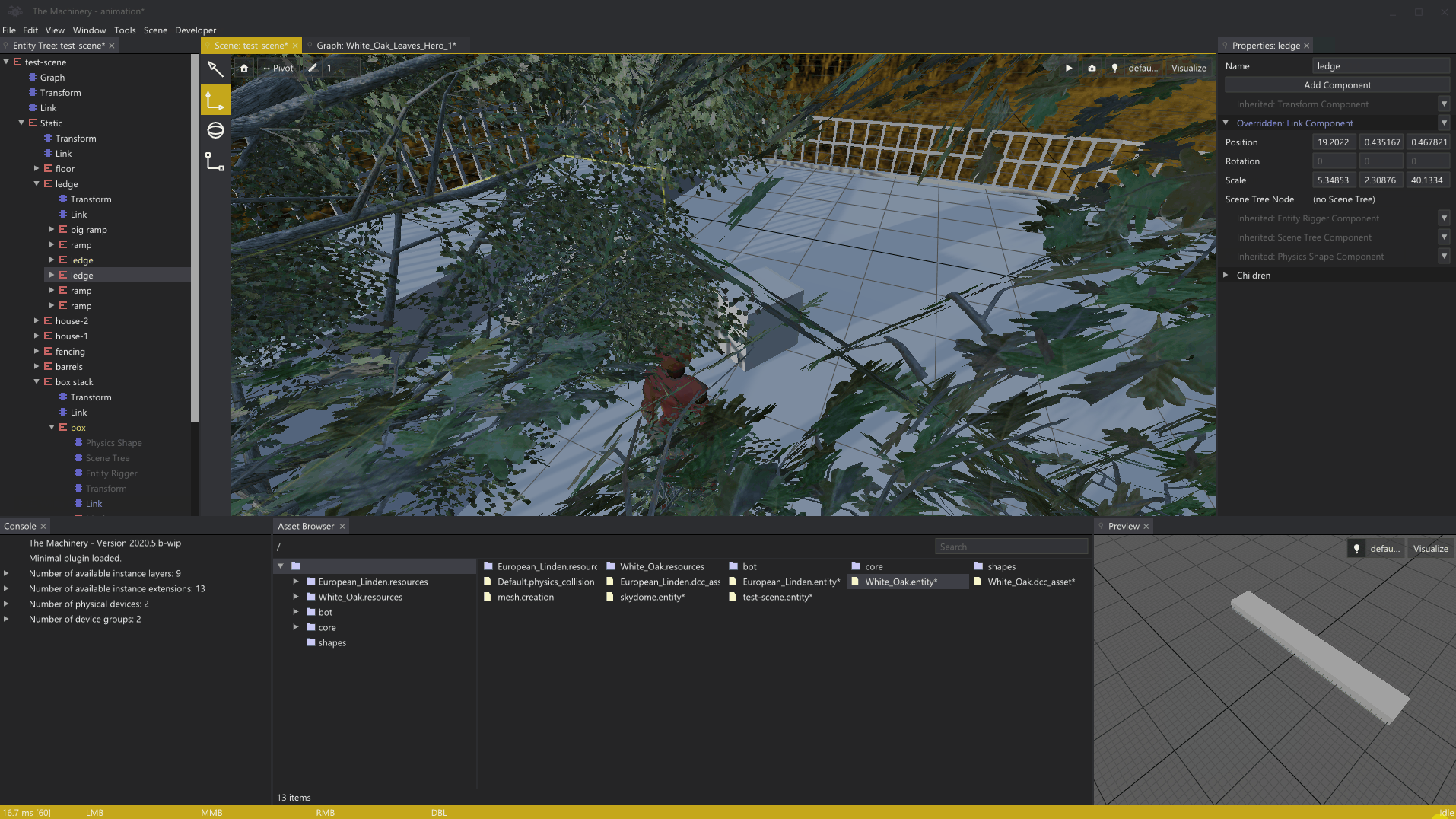
Pixel-perfect picking through alpha masked leafs.
Wrap up
With a GPU-based picking solution you’ll never again have to struggle with complicated picking code
on the CPU-side, anything that’s visualized on screen can be picked as long as the shader implements
the picking_system which isn’t more than a couple of lines of code.
Also note that while the code examples from above only cover pixel-perfect selection, there’s nothing preventing you from extending it to do more of a fuzzy selection, just calculating the distance between the cursor and the current pixel and accept a distance value less than n pixels. This can be useful when dealing with selection of editor gizmos and similar.
Until next time…