Data Structures Part 1: Bulk Data
Any programmer can benefit from some understanding of different data structures and how to analyze their performance. But in practice, I’ve never found any use for AVL trees, red-black trees, tries, skip lists, etc. Some data structures I just use for one particular algorithm, and nothing else (e.g., heaps to implement the priority queue for A* search).
In most of my day-to-day work, I get by with surprisingly few data structures. What I mostly need is:
- Bulk data — a way of efficiently storing a large number of objects.
- Weak references (or handles) — a way of referencing objects in the bulk data without crashing if an object has been deleted.
- Indices — a way of quickly accessing specific subsets of the bulk data.
- Arrays of arrays — a way of storing dynamically sized bulk data objects.
In the next few blog posts, I’ll show how I implement these things. Let’s start with the simplest and most useful one — bulk data.
Bulk Data
There is no good term for it that I’m aware of, but I use bulk data to mean any large collection of similar objects. It might be things like:
- All the bullets in the game.
- All the trees in the game.
- All the coins in the game.
Or, if you are writing your code at a higher abstraction level, it might be things like:
- All the entities in the game.
- All the meshes in the game.
- All the sounds in the game.
Typically each system (rendering, sound, animation, physics, …) in the game has a couple of different types of objects that it needs to keep track of. For example, for a sound system it might be:
- All the sound resources that can be played.
- All the currently playing sounds.
- All the effects (fades, pitches, etc) that are being applied to the sounds.
For the bulk data, I will assume that:
- The order in which the objects are stored doesn’t matter. I.e., we think of it as a set of objects.
- Each object is represented as a fixed-size
POD-struct that can be moved or duplicated
with
memcpy().
It is certainly possible to think of cases where order does matter. For example, if the objects represent renderable items we might want to sort them front-to-back before rendering to reduce overdraw.
However, in most cases, I think it is preferable to sort the data as it is being used, rather than storing the data in a sorted container, such as a red-black tree or B-tree. For example, we can sort our renderable objects front-to-back before passing them down to the renderer, or sort our files alphabetically before showing them in a list. It might seem expensive to sort the data every frame, but in many cases, we can do it in O(n) with a radix sort.
As for only using POD-structs, I prefer plain C structs to C++ objects, because it is easier to see what is going on in memory and reason about the performance implications. However, there are situations where you might want to store something in the bulk data that doesn’t have a fixed size, like a name or a list of child objects. I will discuss this in a future post when I talk about “arrays of arrays”. For now, let’s just assume that all objects are fixed-size PODs.
As an example, here’s what the bulk data structures for our hypothetical sound system might look like:
typedef struct {
resource_t *resource; // Resource manager data
uint64_t bytes; // Size of data
uint64_t format; // Data format identifier
} sound_resource_t;
typedef struct {
sound_resource_t *resource; // Resource that's playing
uint64_t samples_played; // Number of samples played
float volume; // Volume of playing sound
} playing_sound_t;
typedef struct {
playing_sound_t *sound; // Faded sound
float fade_from; // Volume to fade from
float fade_to; // Volume to fade to
double fade_from_ts; // Time to start fade
double fade_to_ts; // Time to end fade
} playing_fade_t;
When thinking about how to store bulk data, we have a couple of goals:
-
Adding and deleting objects should be fast.
-
The data should be laid out in a cache-friendly way so that we can iterate quickly over it for system updates.
-
It should support referencing — there should be a way to talk about specific objects in the bulk data. In the example above, the fade needs to be able to indicate which sound it is fading. I’ve written the references as pointers in the example but depending on how we implement the bulk data we might use something else.
-
The data should be allocator friendly — it should use a few large allocations, rather than allocating single objects on the heap.
The two simplest ways of representing bulk data is to use a static array or a C++ vector:
// Static array
#define MAX_PLAYING_SOUNDS 1024
uint32_t num_playing_sounds;
playing_sound_t playing_sounds[MAX_PLAYING_SOUNDS];
// C++ vector
std::vector<playing_sound_t> playing_sounds;
Using an array is super simple, and it can be a great choice if you know exactly how many objects your application will need. If you don’t know, you’ll either waste memory or run out of objects.
Using an std::vector is a pretty decent, simple solution too, but you should be wary of a few
things:
-
The standard
std::vectorimplementation in Visual Studio runs slow in Debug mode, because of Debug iterators. Make sure to set _ITERATOR_DEBUG_LEVEL=0. -
std::vectoruses constructors and destructors to create and destroy objects which in some cases can be significantly slower thanmemcpy(). -
std::vectoris a lot harder to introspect than a simple stretchy buffer implementation.
Also, without some additional measures, neither plain arrays or vectors support referencing individual objects. Let’s look into that, as well as the other main design decisions that come into creating a custom bulk data solution.
Deletion strategy
The first important decision is what to do when an object a[i] gets deleted. There are three main
options:
- You can move all the subsequent elements:
a[i+1]→a[i],a[i+2]→a[i+1], etc, covering the empty slot. - You can move the last element of the array into the empty slot
a[i] = a[n-1]. - Or, you can leave the slot empty, creating a “hole” in the array. This hole can later be used to allocate a new object.
The first option is terrible — moving all those elements costs O(n). The only useful thing about
the first method is that if the array is sorted, it preserves the order. But, as stated above, we
don’t care about the order. Beware, if you use a.erase() to delete an element in an std::vector,
this is exactly what it will do!
The second option is often called a “swap-and-pop”. Why? Because if you are using a C++ vector, you would typically implement it by swapping the element you want to delete with the last one and then erasing or popping the last element:
std::swap(a[i], a[a.size() - 1]);
a.pop_back();
Why all this? Well, in C++, if we did assignment a[i] = a[n-1], then we would first have to
destroy a[i] , calling its destructor, then call the copy constructor to create a copy of a[n-1]
at position i and then finally call the destructor of a[n-1] when we shrink the vector. If the
copy constructor allocates memory and copies data, that can be pretty bad. By using std::swap
instead of assignment, we can get by with only using move constructors and don’t need to allocate
memory.
Again, this is why I prefer POD structures and C operations to C++. There are a lot of performance traps you can fall into in C++ if you don’t know exactly what is going on behind the scene. In C, the swap-erase operation would just be:
a.data[i] = a.data[--a.n];
Using swap-and-pop keeps the objects tightly packed. To allocate a new object, we just tuck it on to the end of the array.
In contrast, if we use the “with holes” approach, when we allocate a new object we first want to check if there are any “holes” we can reuse. We only want to grow the array if there are no “holes” available. Otherwise, the array would grow indefinitely, as objects are deleted and created.
We could use a separate std::vector<uint32_t> to keep track of the positions of all the holes, but
there is a better approach that doesn’t require any additional memory.
Since the object data in the “holes” isn’t used for anything we can repurpose it to hold a pointer to the next free hole. All the holes in the array thus form a singly linked list, and we can add and remove items from this list as needed.
This kind of data structure, where we repurpose the unused memory to link the free items together is usually called a free list.
In a traditional linked list, a special list header item points to the first node in the list and then the last item in the list points to NULL, indicating the end of the list. I prefer using a circularly linked list instead, where the header is just a special list item and the last item in the list points back to the header item:
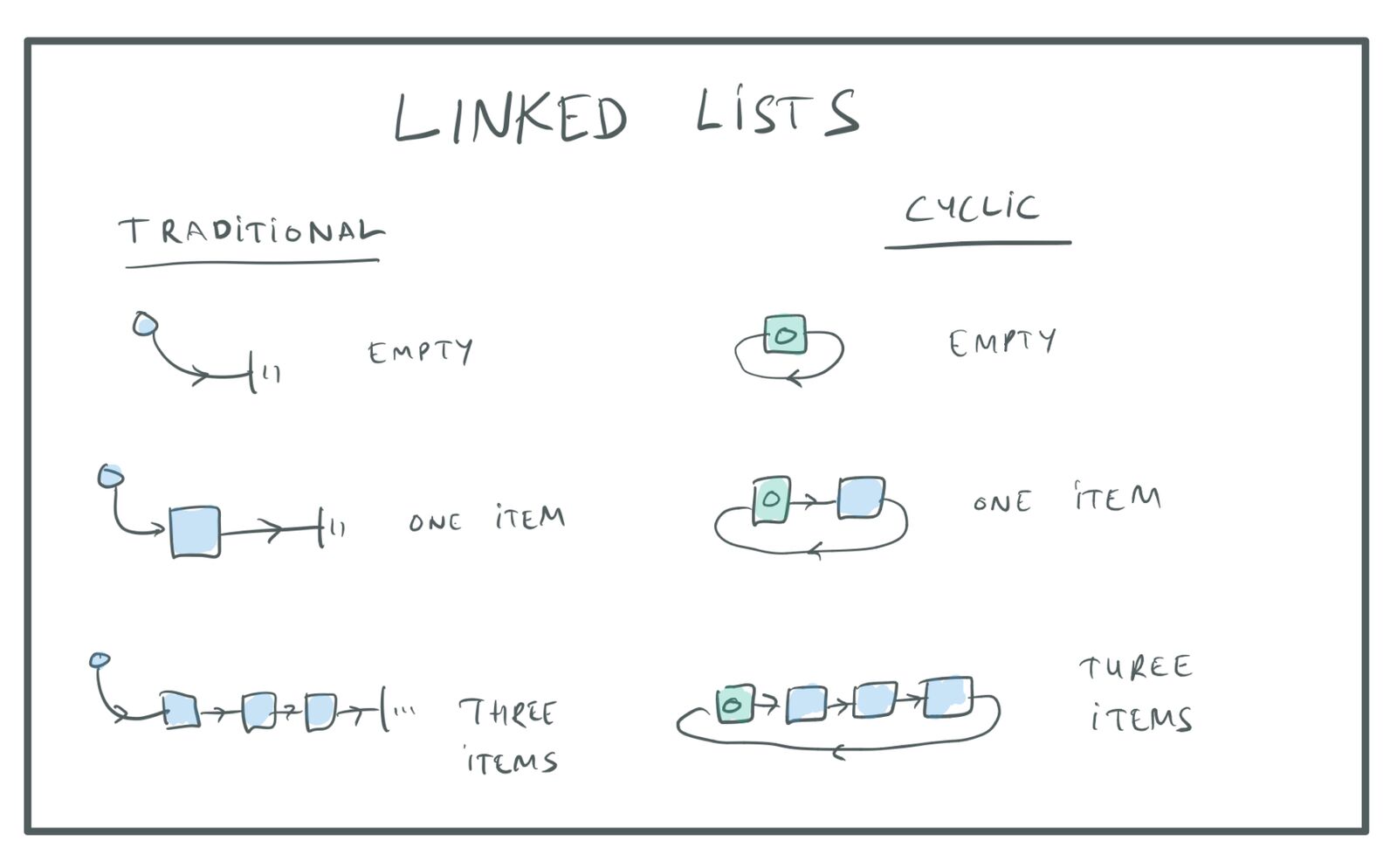
Traditional and cyclic linked lists.
The advantage of this approach is that the code becomes a lot simpler with fewer special cases for the start and the end of the list.
Note that if you are using an std::vector for storage of the objects, the pointers to the objects
will change every time the vector is reallocated. This means you cannot use regular pointers for the
linked list since the pointers keep changing. To get around this, you can use indices as your
“pointers” in the linked list, since an index will permanently identify a specific slot, even if the
array gets reallocated. I will talk a bit more about reallocation in the next section.
We can make room for the special list header item, by always storing it in slot 0 of the array.
With this, the code might look something like this:
// The objects that we want to store:
typedef struct {...} object_t;
// An item in the free list points to the next one.
typedef struct {
uint32_t next;
} freelist_item_t;
// Each item holds either the object data or the free list pointer.
typedef union {
object_t;
freelist_item_t;
} item_t;
typedef struct {
std::vector<item_t> items;
} bulk_data_t;
void delete_item(bulk_data_t *bd, uint32_t i) {
// Add to the freelist, which is stored in slot 0.
bd->items[i].next = bd->items[0].next;
bd->items[0].next = i;
}
uint32_t allocate_slot(bulk_data_t *bd) {
const uint32_t slot = bd->items[0].next;
bd->items[0].next = bd->items[slot].next;
// If the freelist is empty, slot will be 0, because the header
// item will point to itself.
if (slot) return slot;
bd->items.resize(bd->items.size() + 1);
return bd->items.size() - 1;
}
Which deletion strategy is best? Moving the last item to the empty slot, keeping the array tightly packed or keeping all the items in place, creating a “hole” in the array where the deleted item was?
There are two things to consider:
-
Iteration is faster over a tightly packed array because we are traversing less memory and don’t have to spend any time skipping over empty slots.
-
If we use a tightly packed array, items will move. This means that we cannot use an item’s index as a permanent ID to reference items externally. Instead, we have to assign another ID to each item and use a lookup table to resolve these permanent IDs to the objects’ current indices. This lookup table could be a hash table, or it could be an
std::vectorwith holes, just as we described above, which is faster. But either way, we need some extra memory for this table and an extra indirection step to lookup IDs.
Which approach is better depends on your circumstances.
You could argue that keeping the array tightly packed is better because iterating over all elements (for a system update) happens more often than resolving external references. On the other hand, you could argue that the performance of the “array with holes” is only bad if there are a lot of holes, and in game development we usually care about worst-case performance (we want to hit that 60 Hz frame rate even when we have a lot of stuff going on). The worst-case performance is when we have the maximum number of live objects, and in this case, the array will have no holes. Holes are only created when the object count goes down and we delete some of those objects.
There are also strategies we can use to speed up the processing of arrays with lots of holes. For example, we can keep track of the run-length of sequences of holes, so that we can skip over an entire sequence of holes at once, instead of skipping element by element. Since this data is only needed for “holes” and not for regular items, we can store it together with the free list pointer in the unused object memory and it won’t consume any extra memory.
In my view, unless you need to optimize for fast iteration, you are probably better of using the “array with holes” approach. It is more straightforward, doesn’t require any additional lookup structures and you can just use an object’s index as its ID, which is nice. Not having to worry about objects moving around can also eliminate some potential bugs.

Bulk data deletion strategies.
Weak Pointers
As a side note, it is easy to support “weak pointers” or “handles” to our bulk data objects.
A weak pointer is a reference to an object that can somehow detect if the object its referencing has been deleted. The nice thing about weak pointers is that it lets us delete objects without worrying about who might be referencing them. Without weak pointers, to delete an object, we would have to find every single reference to it and invalidate it. This can be especially tricky if references are held by script code, other computers on the network, etc.
Remember that we already have an ID to uniquely identify live objects. In the “with holes” approach, this ID is simply the index of the item (since items never move). In the “tightly packed” case, this the index of the object’s entry in the lookup array.
The ID by itself cannot be used as a weak pointer, because IDs can be reused. If the item gets
deleted and a new item gets created in the same slot, there is no way for us to detect it with just
the ID. To get a weak pointer, we can combine the ID with a generation field:
typedef struct {
uint32_t id;
uint32_t generation;
} weak_pointer_t;
The generation field is a field in the object struct that keeps track of how many times a slot in
our bulk data array has been reused. (In the “tightly packed” case, it keeps track of how many times
the slot in the lookup array has been reused.)
Whenever we delete an item, we tick the generation number in its slot. To test if a weak pointer is
still valid, we check whether the generation in the weak pointer’s struct matches the generation
in the slot indicated by the id. If they match, it means the original object we referenced is
still alive. If not, it means it has been deleted and that the slot is either in the free list or
that it has been reused for a newer object.
Note that since the generation field is needed both for “holes” and for actual objects, you should
make sure that it is stored outside the union:
typedef struct {
uint32_t generation;
union {
object_t;
freelist_item_t;
};
} item_t;
Allocation Strategy
If you use an std::vector for storing the item data, the entire array of elements will be
reallocated whenever the array is full and needs to grow. The existing elements are then copied over
to the new array.
std::vector grows geometrically. That means
that every time the vector needs to grow, the number of allocated elements is multiplied by some
factor (typically ×2). Geometric growth is important because it keeps the cost of growing the array
constant.
When we reallocate the array, we need to move all elements, which has a cost of O(n). However, we also add room for n more elements, as we double the size. This means that we won’t have to grow again until we have pushed n more elements to the array. So the cost of growing is O(n), but we only do it every O(n) th time we push, which means that on average the cost of pushing a single element is O(n) / O(n) = O(1).
The cost of pushing an element is said to be amortized constant because if you average it out over all the pushes we make, the cost is constant. We shouldn’t forget though, that before we take the average, the cost is super spiky. Every O(n) pushes, we get a spike that is O(n) high:
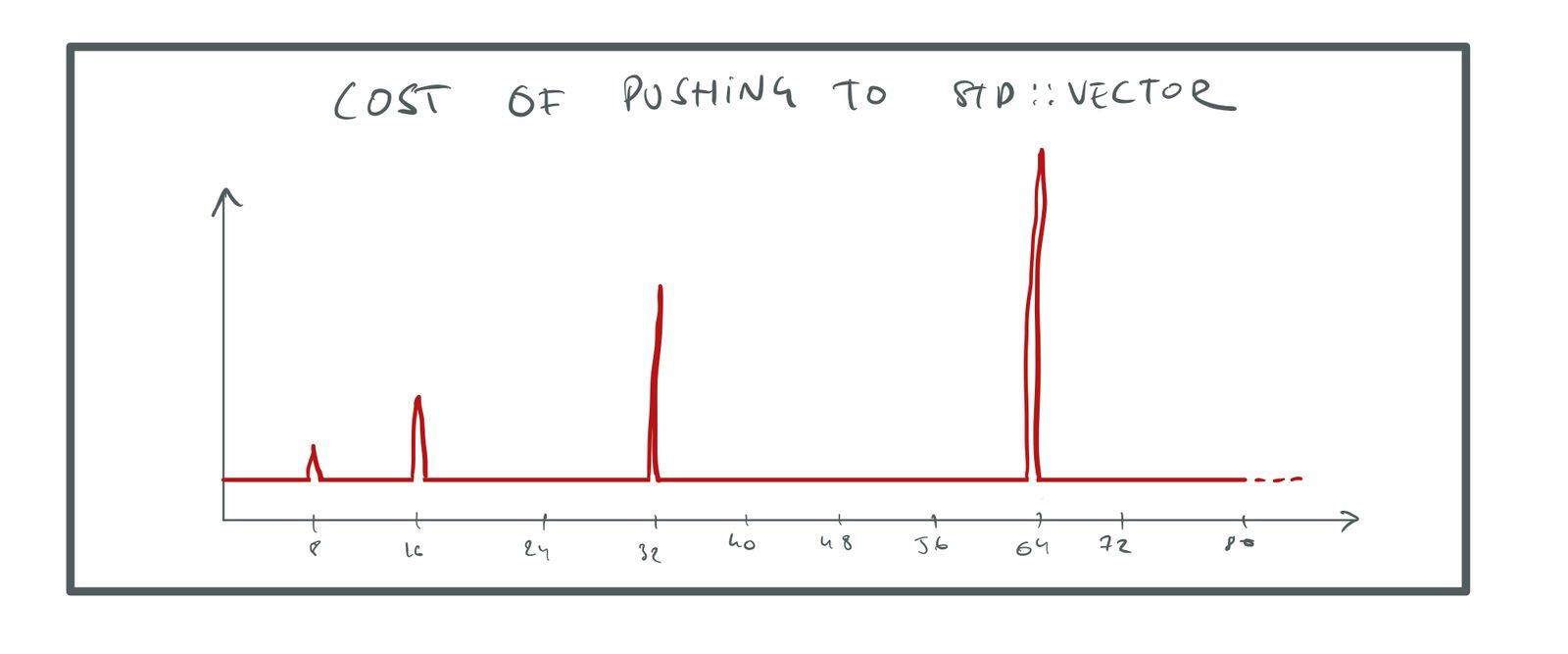
Cost of pushing to std::vector.
Note what happens if we don’t use geometric growth. Say that instead of doubling the memory when we need to grow, we just add 128 more slots. Moving the old data still costs us O(n), but now we have to do it for every 128 elements we add, so the average cost is now: O(n) / O(128) = O(n). The cost of pushing an element to the array is proportional to the size of the array, so as the array gets big, pushing will slow to a crawl. Oops!
The std::vector allocation strategy is a good default and works well in a lot of cases, but there
are some problems with it:
-
“Amortized constant” is not great for real-time software. If you have a really large array, say with hundreds of millions of items, then growing that array and moving all the elements will cause a noticeable frame rate stall. This is problematic for the same reason that garbage collection can be problematic in games. It doesn’t matter if the average cost is low if the cost can spike in some frames, causing the game to glitch.
-
Similarly, this allocation strategy can waste a lot of memory for large arrays. Suppose we have an array of 16M items and we need to push one more. This forces the array to grow to 32M. We now have 16M items in the array that we don’t use. On a memory-constrained platform, that is a lot of wasted memory.
-
Finally, the reallocation will move objects in memory, invalidating all object pointers. This can be a source of subtle bugs.
As an example of bugs that can occur when objects are moved, look at this code:
// Create two items and return the sum of their costs.
float f(bulk_data_t *bd) {
const uint32_t slot_1 = allocate_slot(bd);
item_t *item_1 = &bd->items[slot_1];
const uint32_t slot_2 = allocate_slot(bd);
item_t *item_2 = &bd->items[slot_2];
return item_1->cost + item_2->cost;
}
The problem here is that allocate_slot() may need to reallocate the array to make room for
item_2. In this case, item_1 will be moved in memory and the item_1 pointer will no longer be
valid. In this specific case, we can fix the issue by moving the assignment of item_1, but bugs
like this can show up in subtler ways. I’ve personally been bitten by them many times.
It is also treacherous because the bug will only trigger if the reallocation of the array happens
exactly when slot_2 is allocated. The program may run fine for a long time until something changes
the allocation pattern and triggers the bug.
We can fix all these issues by using a different allocation strategy. Here are some options:
-
We can allocate a sequence of geometric growing buffers: 16, 32, 64, … etc, but keep the old buffers as we are allocating new ones. I.e., the first 16 elements are stored in one buffer, the next 32 elements in the next, etc. To keep track of all these buffers we can store pointers to them in a separate
std::vector. -
We can allocate a sequence of fixed-size buffers and store as many elements will fit into each buffer. Since we can pick the size of the buffers, we can choose them to be a multiple of the page size. That way we can allocate the memory directly from virtual memory and avoid going through the heap. Note that using a fixed size does not cause O(n)
push()performance in this case, because we never move the old elements. -
We can use the virtual memory system to reserve a huge array — enough to hold all the objects we will ever need, but then only commit the memory that we are using.
Again, each method has advantages and drawbacks. The last approach is nice because the elements will still be contiguous in memory and you only have a single buffer to keep track of, so you won’t need any additional vectors or lists to keep track of your buffers. It does require you to set a maximum size for your array, but the virtual address space is so big that you can usually set it to something ridiculously large without causing problems.
If you can’t use the virtual memory approach, which is better — fixed size or geometrically growing blocks? Using a fixed size will waste memory if your array is really small. For example, with a 16 K block size, you will use all those 16 K even if your array only has a single element. On the other hand, with geometric growth, you will waste memory if your array is really big since on average the last block you allocate will only be 50 % full. For a large array, that can be multiple megabytes.
Again, in game development, it is more important to optimize for the worst-case, so it doesn’t bother me much if the small arrays are wasteful, as long as the big arrays perform well. The total memory wasted will never be more than n × 16 K, where n is the number of distinct bulk data arrays in the project and I don’t expect us to have that many different arrays (only a few per system).
Fixed-size blocks have two other advantages. First, the calculation to find an element from its
index is simpler, it is just: blocks\[i / elements_per_block\][i % elements_per_block]. Second,
allocating memory directly from the virtual memory system is more efficient than going through a
heap allocator, since it avoids fragmentation.
In conclusion, if you are using the “with holes” approach for storing the data I think it is worth
also changing the allocation strategy from the std::vector approach, so that objects get permanent
pointers that never change. Reserving a large array of virtual memory is probably the best approach,
but if you are not able to do that, using a sequence of fixed-size blocks is the next best option.
Note that since this approach makes object pointers permanent, we can now use object pointers in addition to IDs to reference objects. An advantage of this is that we can access objects directly, without having to perform an index lookup. On the other hand, a pointer needs 64 bits of storage while an index can usually get by with 32 (4 billion objects is plenty).
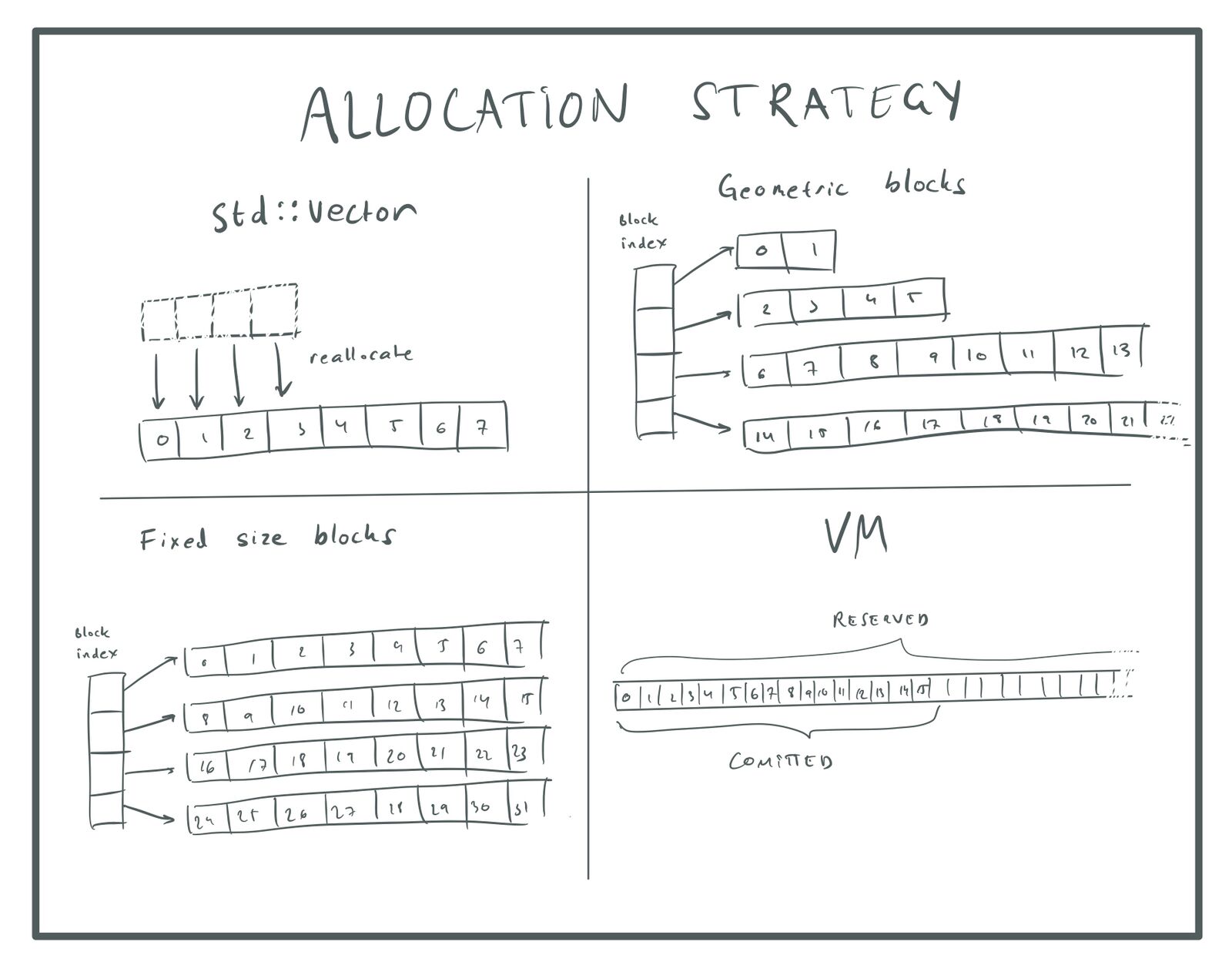
Allocation strategies.
Array of Structures vs Structure of Arrays
Another important design decision is choosing between an Array of Structures (AoS) or a Structure of Arrays (SoA) approach. The difference is best explained with an example. Suppose we have a simple particle system where particles have lifetime, position, velocity and color:
typedef struct {
float t;
vec3_t pos;
vec3_t vel;
vec3_t col;
} particle_t;
The normal way of storing this would be to put a number of these structs in an array. That’s why we refer to it as an “array of structures”. That is:
uint32_t num_particles;
particle_t *particles;
Of course, instead of a regular array, any of the storage strategies discussed above could be used.
In a Structure of Arrays (SoA) approach, we instead use a separate array for each field of the struct:
uint32_t num_particles;
typedef struct {
float *t;
vec3_t *pos;
vec3_t *vel;
vec3_t *col;
} particles;
In fact, we can go even further, since vec3_t is itself a struct:
uint32_t num_particles;
typedef struct {
float *t;
float *pos_x;
float *pos_y;
float *pos_z;
float *vel_x;
float *vel_y;
float *vel_z;
float *col_r;
float *col_g;
float *col_b;
} particles;
This looks a lot more complicated than our original AoS setup, so why would we ever do this? There are two arguments:
-
Some algorithms only work on a subset of the fields. For example a
tick()algorithm might only touch thetfield. Asimulate_physics()algorithm might only touch theposandvelfields. With an SoA layout, only the parts of the structs used need to be loaded into memory. If we are memory-bound (which we often are on modern processors), this can make a huge difference. For example, thetick()function will touch 1/10th as much memory and thus get a ×10 speedup. -
The SoA layout lets us load data directly into SIMD registers for processing. This can make a huge difference if we’re FPU bound. With AVX we can process up to eight floats at a time, giving us a ×8 speedup.
Does this mean that, with both these speedups, tick() will be ×80 faster? No. We only get the
first ×10 speedup if we’re completely memory-bound, and if we’re completely memory-bound, SIMD can’t
make us run faster.
The drawbacks of the SoA approach are:
-
The code becomes more complicated.
-
More pressure on the allocator, since we need to allocate 10 separate arrays, instead of a single one.
-
We can no longer refer to an individual particle with a
particle_t *pointer since the fields of the particle are now spread out in different places. We have to refer to particles by index. -
Accessing the fields of a particle from its index requires a lot more computation since we have to perform a separate index calculation for each field.
-
When processing a single particle we have to touch data in more places (each array), which might be harder on the cache. Whether it’s actually harder depends on the specifics of the memory architecture.
As an example of how things might go bad with the cache, consider again the particle struct above, and suppose that we have allocated all arrays using the VM (so they are aligned on 4K page boundaries). Because of this alignment, all of the 10 fields of a particle’s struct will map to the same cache block. If our cache is 8-way set associative this means that all the fields of the particle can’t be in the cache at the same time. Oops!
One way of fixing this is to group particles by the SIMD vector size. For example, we can do this:
uint32_t num_particles;
typedef struct {
float t[8];
float position_x[8];
float position_y[8];
float position_z[8];
float velocity_x[8];
float velocity_y[8];
float velocity_z[8];
float color_r[8];
float color_g[8];
float color_b[8];
} eight_particles_t;
eight_particles_t *particles;
With this layout, we can still process eight particles at a time with SIMD instructions, but the fields of a single particle are close-ish in memory and we don’t get the problem with cache line collisions that we had before. It is also nicer to the allocation system since we’re back to having a single allocation for the whole particle array.
The tick() algorithm, in this case, will touch 32 bytes, skip 288 bytes, touch 32 bytes, etc. This
means we won’t get the full ×10 speedup that we got from having a separate t array. For one, cache
lines are typically 64 bytes, and since we’re only using half of that we can’t be faster than ×5.
There might also be some cost associated with the skipping, even if we were processing full cache
lines, not 100 % sure.
You can fiddle with the group size to address this. For example, you could change the group size to
[16] so that a single float field will fill an entire cache line. Or, if you use the block
allocation method, you could just set the group size to whatever will fit into the block:
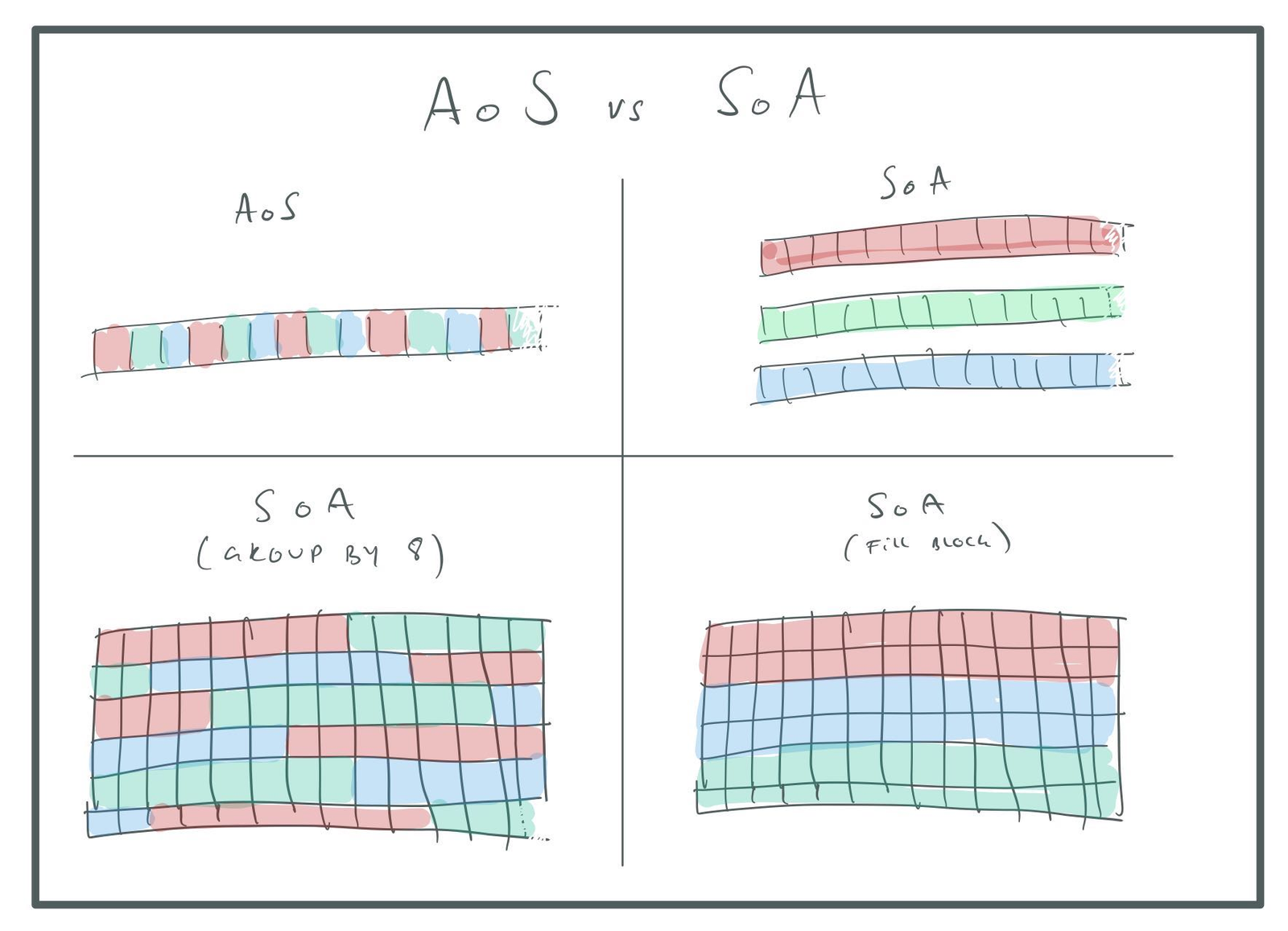
AoS vs SoA.
When it comes to the deletion strategy, SoA is not a great fit for the “with holes” approach, because if we’re using SIMD to process eight elements at the time, there is no way for us to skip the holes (unless all eight elements are “holes”).
Since the SIMD instructions will process the “holes” as well as the real data, we have to make sure
that the holes contain “safe” data. I.e., we don’t want the operations on the holes to trigger
floating-point
exceptions,
or create denormals that will hurt performance.
Also, we can’t store the free list next pointer using a union anymore, since the SIMD operations
would overwrite it. We have to use a proper struct field.
If we use the “tightly packed” approach, deletion will be a bit more expensive, because we have to move each field separately, instead of moving the whole struct at once. But since deletion should be a lot rarer than updates, this shouldn’t be a big concern.
My take on AoS vs SoA is that in most cases, the performance improvements are not worth the extra hassle of writing code in this more cumbersome way. I would use a regular AoS as the “default” storage format for systems and only switch to SoA for systems that need the speed of SIMD calculations, such as culling and particles. In these cases, I would probably also go with tightly packed arrays to get the maximum speed.
Another thing I might consider is to keep the data stored at AoS, but generate temporary SoA data for processing by some algorithm. I.e., I would do a single pass over the AoS data and write it out into a temporary SoA buffer, crunch that buffer and then write the results back as AoS (if needed). Since in this case, I know exactly what algorithm I’m going to run on the data, I can optimize the storage format for it.
Note that this approach works well with the “block storage” approach. You could process one 16 K block at a time, convert it into SoA, run your algorithm and write the results back. You only need a 16 K scratch buffer to hold the temporary data.
Conclusion
There are advantages and drawbacks to everything, but my default recommendation for storing bulk data for a new system would be:
An array of structures, with “holes” and permanent pointers, either allocated as one single large VM reservation (if possible) or as an array of fixed size blocks (of 16 K or whatever is a good fit for your data).
And for the cases where you need really fast number crunching over the data:
A structure of arrays of tightly packed objects, grouped 8 at a time for SIMD processing and allocated as one single large VM reservation, or as an array of fixed-size blocks.
Next time we’ll look at indexing this data.