Data Structures Part 2: Indices
In my last post, I concluded that the best way to store most things is to use a large unsorted array. I sneakily avoided mentioning that there is one thing that large unsorted arrays are exceptionally bad at – finding things! But maybe emphasizing that it was a large, unsorted array gave you a hint?
In this post, I’ll try to remedy that.
Finding things
“Finding things” is pretty vague, but it might mean things like:
-
Find all the sounds that are playing from a certain sound source (so that we can move the sounds when the sound source moves).
-
Find all the sounds that are playing a certain sound resource (so that we can stop them before unloading the resource).
-
Find all effects that are being applied to a certain playing sound (so that we can cancel the effects when the sound stops playing).
-
Etc.
In traditional object-oriented design, we typically do this by keeping explicit lists. I.e., a sound
source may have an std::vector of all the sounds playing from it. A playing sound may have an
std::vector of all the effects being applied to it, etc, etc.
This can work, but it spreads the data out in lots and lots of small arrays. As I wrote in the previous post, I prefer to have a few large arrays that hold all the data in the system.
Let’s look at a concrete example that we’ll use throughout the rest of this article.
Suppose we want a system that implements the observer pattern for entities. The system lets an entity “subscribe” to events from one or more other entities. When an entity is modified, all the subscribers are notified. We call the subscribers “observers” and we call the entities they are watching “observeds”.
Again, the traditional object-oriented approach would be to let the observed entity have a list of all the entities that are observing it. When the entity is changed it goes through this list to notify them. In addition to creating lots of small arrays, this also has another problem – when an object dies, how does it get removed from the lists of all the objects it is observing? Maybe we can use weak references, so we don’t have to remove it, but that will still waste memory. Or maybe all the observing objects also need a list, a list of all the objects they are observing. It’s starting to get messy.
What would the data-oriented approach be? Well, we want everything in a big array, so why not simply make a big array of “observations”, where each observation connects an observed entity to its observer entity:
typedef struct {
entity_t *observed;
entity_t *observer;
} observation_t;
uint32_t num_observations;
observation_t *observations;
I’ve shown the data as an array here, just because it is simplest, but we could use any of the
methods described in the previous post for storing bulk data. I assume too that whatever method we
use for storing entities gives us permanent pointers, so we can use an entity_t * to permanently
refer to an entity. If that is not the case, we would have to use something else that would give us
a permanent reference instead, such as an index or an ID.
An entity might appear several times in the observations array if it is watching multiple
entities, or being watched by multiple entities. Note that this way of organizing the data is a lot
more similar to a relational database than to
a traditional object-oriented model.
Assuming this data layout, what are the kind of “searches” we will need to do? Two typical situations are:
-
Entity A has changed, notify all its observers:
SELECT * WHERE (observed == A) -
Entity B has been deleted, remove it from the system:
SELECT * WHERE (observed == B OR observer == B)
The most straightforward way of resolving queries like these would be with a brute force loop:
for (observation_t *o = observations; o != observations + num_observations; ++o) {
if (o->observed == a) {
// notify(...)
}
}
The cost here is O(n) in the number of observations. This might be alright for very small datasets, but we want to find something better.
To improve the performance, we can add additional data structures that let us find things and resolve queries faster. Since this already looks a lot like a database, we will borrow from that terminology and call these accelerating data structures indices.
Indices
A database index is usually a list of references to database records, sorted by one of the fields.
This can be used to answer range queries (salary > 50 AND salary < 100) or find items using binary
search (which is O(log n)).
In game development, we usually don’t need to perform range queries. Typically, we’re only looking
for items with a specific value. For example, we may look for all observations with observed == A.
This is nice because it means we can use hash tables instead of sorted arrays as our lookup structure
and accelerate the performance from O(log n) → O(1).
(As an exception, range queries on positions are often useful, e.g., “find all enemies within 50 m of the player”. I’ll talk a little bit later about how those can be implemented.)
So basically, what we want from our acceleration index, is that given an entity A it should
quickly give us a list of all the observations where observed == A. I.e., something like this:
- A → (o1, o2, o3, …)
Before we get into this, let’s start with a simpler case. Let’s assume, just for the sake of simplicity, that, for the property we’re interested in, all the objects have unique values, so our query will at most return a single item:
- A → o1
We will go back in a little bit and look at the more complex case, once we’ve sorted this out.
If we only need a single value, all we need is a lookup table from one object to another. We can do this with a regular hash table. It could look something like this:
chash32_t observation_by_observed;
observation_t *find_by_observed(entity_t *e)
{
const uint64_t key = (uint64_t)e;
const uint32_t idx = chash32_get(&observation_by_observed, key, UINT32_MAX);
return idx == UINT32_MAX ? 0 : observations + idx;
}
Here, observation_by_observed is our index. It stores a lookup from an entity
(represented by a pointer) to the observation that has that entity in its observed field
(represented by an index into the observations array).
It’s a little bit arbitrary that we’re referencing entities by pointers and observations by indices in this example, we could just as easily do it the other way around – assuming we are using the bulk data strategy laid out in the previous post, where both object pointers and indices are permanent.
Note that the way I’m using hash tables is a bit unusual. Typically, in C++, you would define a
hash table as a template hash<K,V> and the hash table would call an overloaded hash() function
on the key objects K to compute numerical keys.
In my approach, the hash table does not use templates, but instead just performs a lookup from
uint64_t → uint32_t. If we need to hash the key, we do that before we perform the lookup.
And instead of storing our values directly in the hash table, we just store indices into an array of
values. Since we like to store or our bulk data in big arrays anyway, this works out perfectly. I’ve
written a bit more about this approach
before.
Note that in the entity case, we don’t need to hash the key, we can just cast the pointer (or index)
directly to an uint64_t. This gives us a unique uint64_t value that we can use as our hash
table key.
If the property we want to use for our lookup key doesn’t fit in an uint64_t, we have to hash it.
Say we want to look up players by name, for example. It could look something like this:
struct {
char *name;
// ...
} player_t;
uint32_t num_players;
player_t *players;
chash32_t player_by_name;
player_t *find_by_name(const char *name)
{
const uint64_t key = murmurhash_cstring(name);
const uint32_t idx = chash32_get(&player_by_name, key, UINT32_MAX);
return idx == UINT32_MAX ? 0 : players + idx;
}
For indices to be useful, they must be kept up to date. This means that whenever items are added to, removed from, or modified in the array, the index must be updated accordingly so that it still reflects the contents of the array. The index is thus a tradeoff – we spend a little more time when modifying the array so that we can spend less time when searching the array. Usually, this pays off, because it only adds a small constant O(1) cost to modifications and it greatly accelerates the searches O(n) → O(1).
Updating the index could look something like this:
void add_observation(const observation_t *o)
{
// Commit VM memory if needed, see previous post...
const uint32_t idx = num_observations++;
observations[idx] = *o;
const uint64_t key = (uint64_t)o->observed;
chash32_add(&observation_by_observed, key, idx);
}
void remove_observation(const observation_t *o)
{
const uint64_t key = (uint64_t)o->observed;
chash32_remove(&observation_by_observed, key);
// Add o to free list, see previous post...
}
If you are using the method I recommended in the previous post to store your bulk data arrays, indices are permanent, so they’re safe to use as both keys and values in the hash table.
If you are using the “tightly packed” approach instead, the indices are not permanent, so you must be very careful with how you use them. In this case, I would recommend storing IDs instead, and using the ID → index lookup table to resolve the ID to an actual object index, after the hash table lookup.
You could still store indices in your hash table in this case, but you would have to make sure that whenever you move items to pack the bulk data array, you update their indices in the hash table to reflect the move. This would save you the ID → index indirection step when searching, but I’m not sure it’s worth the extra complexity. Working with indices that can be invalidated at any point if an object is deleted can be very error-prone.
Finding multiple items
Alright, now that we have solved the problem of finding single items, let’s go back to the slightly more complicated case, where we need a map from a key to a set of values:
- A → (o1, o2, o3, …)
On the face of it, this doesn’t seem that different. Can’t we just do what we did before, but let the hash table map to a set of values instead of to a single value?
If we were using STL, maybe we could use something like std::map<entity_t *, std::vector<uint32_t> >? With my chash32_t, maybe the hashtable could map to an index into an
array of arrays? Each array would store references to all the observations for one particular key
A. Let’s try it:
chash32_t observations_by_observed;
std::vector< std::vector<uint32_t> > observations_by_observed_arr;
const std::vector<uint32_t> &find_by_observed(entity_t *e)
{
static std::vector<uint32_t> empty;
const uint64_t key = (uint64_t)e;
const uint32_t idx = chash32_get(&observations_by_observed, key, UINT32_MAX);
return idx == UINT32_MAX ? empty : observations_by_observed_arr[idx] ;
}
I don’t know about you, but this looks pretty bad to me. I program exclusively in C these days,
so I don’t use STL any more, but even back when I did, I was never a fan of nested STL containers,
such as std::map<entity_t *, std::vector<uint32_t> or std::vector< std::vector<uint32_t> >.
My main problem with STL is that it is kind of a leaky
abstraction. STL makes it hard to see what
is going on beneath the surface, i.e., how the data is stored and accessed (if you’ve tried
debugging STL containers you know what I’m talking about). On the other hand, you kind of have to
know what’s going on beneath the surface, or you will undoubtedly mess up and write some really
inefficient code (such as erasing elements in the middle of an std::vector).
Nested STL containers exacerbate this problem. When you have a vector inside a map inside a vector, it is even harder to know what’s going on.
Another issue with this approach is that we again get lots and lots of tiny arrays. As I said before, I prefer having data stored in a few large bulk data arrays rather than spread out all over the place in thousands of tiny arrays. It is nicer to the allocator, friendlier to the cache, reduces fragmentation and lets you get big chunks of memory straight from the VM. But the main advantage is that it is easier to reason about. It makes it a lot easier get a handle on how much memory you are using, how you can optimize it, how access patterns affect the performance, what SIMD could do to improve things, etc, etc.
I’ll revisit this topic in my next post and see if we can find better ways of storing lots of small arrays, but for now, let’s try to find a better way to represent our one-to-many index.
Another approach would be to use an std::unordered_multimap<K,V>. This is a hash-based STL
container that allows lookups from a key to a set of values, which seems to be just what the doctor
ordered. Note that std::multimap is not what we want – it’s search-based, not hash-based, so
lookups are O(log n). In fact, you should probably almost always be using one of the
std::unordered_* data structures instead of a regular map, set, multimap or multiset.
std::unordered_multimap is fast at looking up and inserting objects, but deleting objects
can be expensive. In our observer example, our lookup table would look something like this:
std::unordered_multimap<entity_t *, observation_t *> observation_by_observed;
Now, suppose we want to delete a particular observation_t *. To do that, we also want to delete
its entry in the observation_by_observed table. But, std::unordered_multimap doesn’t have any
way of looking up entries based on their values, we can only look up entries based on their
keys. To remove an observation_t *o, we first have to look up o->observed. However, this
will return all the values with that key, so we then have to search that list for the particular
observation_t *o we want to remove:
auto its = observation_by_observed.equal_range(o->observed);
for (auto it = its.first; it != its.second; ++it) {
if (it->second == o) {
observation_by_observed.erase(it);
break;
}
}
This search is O(m), where m is the number of entries in the bucket with the key o->observed.
That may not seem too bad, but there are situations where it can blow up. Suppose that we have
n enemies in the game that are all observing the player (so o->observed is identical for all
of them). In this case, removing a single enemy is O(n), so removing all of them is O(n²).
Ugh! In game development, your primary performance goal is basically to never ever hit O(n²).
O(n²) is bad, m’kay!
So no array of arrays, no std::unordered_multimap – do we have anything left in our bag of
tricks?
Remember in the last post how we used a free list to link together the “holes” in the array for reuse, and how we could add items to and remove items from this list in O(1).
We can use the same basic technique to keep track of the set of items matching a certain key. All we
have to do is to link the items in a set together using next pointers, just as we did for the free
list. If we know one member of the set, we can now find all the other members just by walking the
next pointers.
How can we find one member of the set? Well, we already found a good solution for that in the last
section of this post, our A → o1 hash table map. So if we just combine these two ideas, we get
the complete solution. We use the hash table to find the first item in the set and then walk the
next pointers to get all the other ones.
Note that to implement deletion of an arbitrary observation_t * efficiently, we also need prev
pointers, because when we remove an item, we need to update the next pointer of the item before it
in the set. And we can only do that efficiently if we have a prev pointer to get to that item. We
didn’t need this for our free list, because with the free list, we never remove items in the middle,
we’re always just removing the first item in the list, so there is no previous item to consider.
Here’s the data layout and the code for finding the set of items for a specific key:
typedef struct {
entity_t *observed;
entity_t *observer;
uint32_t prev;
uint32_t next;
} observation_t;
uint32_t num_observations;
observation_t *observations;
chash32_t first_observation_by_observed;
observation_t **find_observations_by_observed(entity_t *observed,
temp_allocator_i *ta)
{
observeration_t **res = 0;
const uint64_t key = (uint64_t)observed;
const uint32_t first_idx = chash32_get(&first_observation_by_observed, key,
UINT32_MAX);
if (first_idx == UINT32_MAX)
return res;
uint32_t idx = first_idx;
do {
observation_t *o = observations + idx;
carray_temp_push(res, o, ta);
idx = o->next;
} while (idx != first_idx);
return res;
}
Here I use an array allocated using temporary or “scratch” memory to return the items. Another
possible approach would be to just return the first item and let the caller follow the next
pointers.
Just as I did with the free list, I store the items in a cyclical list, where the last item points back to the first. I link this better than linear lists because it makes the code more uniform with fewer special cases:
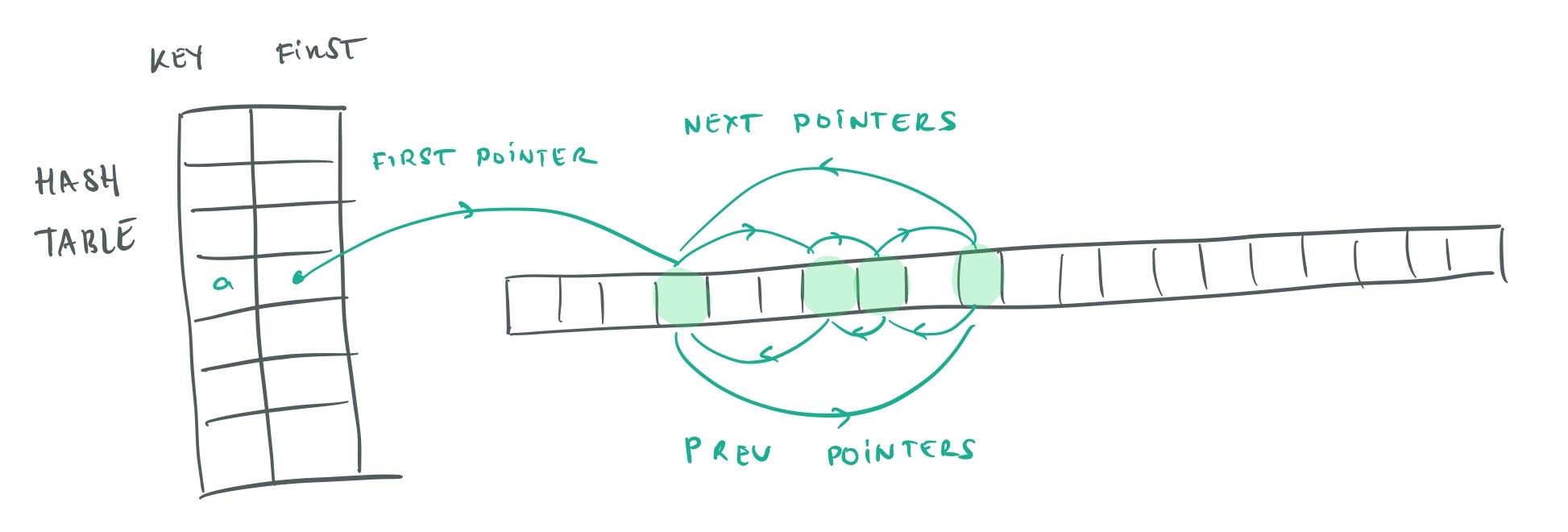
Index data structure.
This sample code shows how adding and removing objects can work:
void add_observation(const observation_t *o)
{
// Commit memory as needed...
const uint32_t idx = num_observations++;
observations[idx] = *o;
const uint64_t key = (uint64_t)o->observer;
const uint32_t first = chash32_get(&first_observation_by_observer, key,
UINT32_MAX);
if (first != UINT32_MAX) {
const uint32_t second = observations[first].next;
observations[idx].prev = first;
observations[idx].next = second;
observations[first].next = idx;
observations[second].prev = idx;
} else {
observations[idx].prev = idx;
observations[idx].next = idx;
chash32_add(&first_observation_by_observer, key, idx);
}
}
void delete_observation(const observation_t *o)
{
const uint32_t idx = o - observations;
const uint32_t prev = o->prev;
const uint32_t next = o->next;
observations[prev].next = next;
observations[next].prev = prev;
const uint64_t key = (uint64_t)o->observer;
const uint32_t first = chash32_get(&first_observation_by_observer, key);
if (first == idx) {
if (next != idx)
chash32_update(&first_observation_by_observer, key, next);
else
chash32_remove(&first_observation_by_observer, key, idx);
}
// Add item to free list (see previous post)...
}
With this approach, all the basic operations are O(1) – adding, removing and finding the first element of a set. Finding all the elements of a set is O(m), where m is the size of the set, but that is ok. Presumably, we are finding the elements in order to do something with them, which will be O(m) anyway.
In terms of memory, we’re adding two extra uint32_t to each item to hold the prev and next
pointers, which is not too bad.
Cache behavior
A drawback of using linked lists for storage can be that they have bad cache performance since the
elements in the list can be spread out in memory. This can happen in this case too. The items in the
double-linked list created by the prev and next pointers can be anywhere in the array, causing
us to jump erratically through memory as we follow them:
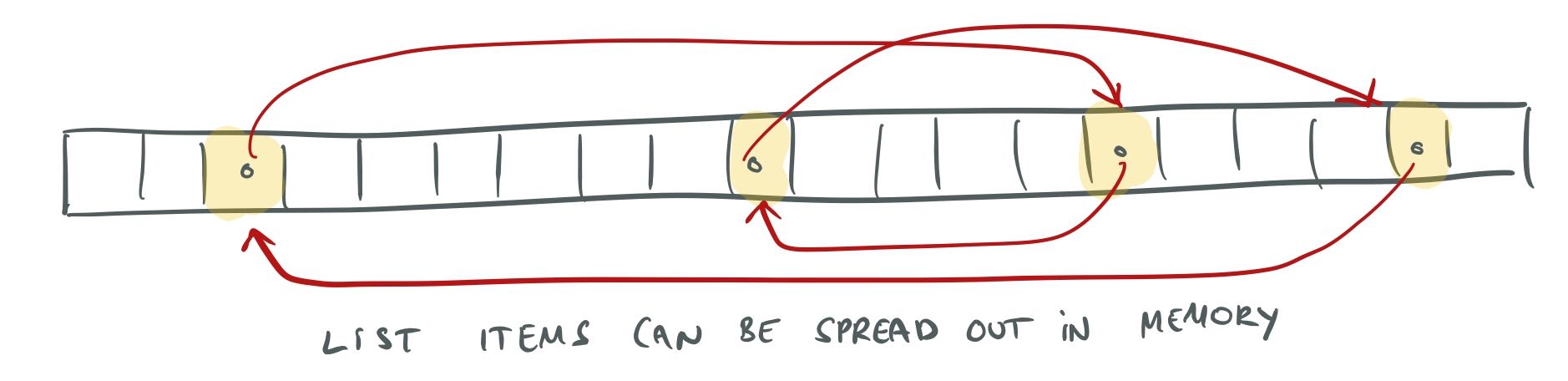
Items in a set can be spread out in memory.
But again, assuming that we are finding the items in order to do something with them, this is the access pattern we will have, no matter what kind of search index we use because this is where the items are in memory.
The only way to get a different access pattern is to move the items in memory. For example, we could sort the items by the lookup key, so that all the items with the same lookup key ended up together in memory:

Clustered index.
In database terminology, this is called a clustered index. Note that a database cannot have more than one clustered index, because we cannot physically sort the records in more than one way.
If we wanted to, we could implement something similar to clustered indexing to get better cache behavior. For example, we could incrementally sort the array – a little bit every frame. However, note that this would mean that items would move around in memory and we would no longer have permanent indices or permanent object pointers. Generally, I don’t think it’s worth doing, having stable indices and pointers is more important than improving the cache behavior of queries.
Multiple indices
Nothing with this approach restricts us to using just a single index. We can simply add as many indices as we need, for all the queries we want to accelerate.
Here’s what our observer pattern example might look like if we add indices for both observeds and observers:
typedef struct {
entity_t *observed;
entity_t *observer;
uint32_t prev_by_observed;
uint32_t next_by_observed;
uint32_t prev_by_observer;
uint32_t next_by_observer;
} observation_t;
uint32_t num_observations;
observation_t *observations;
chash32_t first_observation_by_observed;
chash32_t first_observation_by_observer;
Note that we need multiple prev and next pointers in this case because the set an object will
be a part of based on its observer field is different than the set it will be a part of based on
its observed field.
If you need a lot of indices, this can get kind of messy. If you want to, you can rearrange the index data into separate structs:
typedef struct {
entity_t *observed;
entity_t *observer;
} observation_t;
typedef struct {
uint32_t prev;
uint32_t next;
} pointers_t;
typedef struct {
pointers_t *pointers;
chash32_t first;
} index_t;
int32_t num_observations;
observation_t *observations;
index_t observations_by_observed;
index_t observations_by_observer;
Here pointers is a separately allocated array with num_observations entries. Each observation
in the observations array has a corresponding entry in the pointers arrays.
With this data layout, you can add as many indices as you need, without disturbing the original data structure. Whenever you have a query that you want to accelerate, you can just add an index for it.
Fuzzy hashing
I mentioned earlier that one of the few cases where range lookups are useful is in position queries, such as “find all pickups within 5 m from (x, y)". But even in this case, a sorted array is usually not a good solution, since we need to search across multiple dimensions. Say, that you’ve sorted your data along the x-coordinate. This lets you quickly find all objects with x in the range (x-5, x+5). However, only a tiny fraction of those objects will have y in the range (y-5, y+5), and if the objects are sorted on the x-coordinate, you pretty much have to go through all of them to find the ones with the right y-coordinate.
There are lots of ways to accelerate spatial queries. Christer Ericson’s Real-Time Collision Detection is a good overview. In this post, I just want to mention one method related to what we’re already talking about.
It turns out we actually can use a hash table to answer spatial queries. All we have to do is to suitably quantize the data. For example, to find all pickups within 5 m of a certain point P all we have to do is to divide the world into a 10 m grid. We can then use the (integer) grid coordinates as a hash key. All objects in the same grid cell will end up in the same hash bucket:
const uint64_t ix = (uint64_t)(p.x / 10.0f + (float)INT64_MAX);
const uint64_t iy = (uint64_t)(p.y / 10.0f + (float)INT64_MAX);
const uint64_t key = mix(ix, iy);
Here mix(a, b) is a suitable mixing function for mixing the bits of a and b. Note
that you don’t want to use something too simple like a ^ b, because that would put the grid cells
(0,0) and (1,1) in the same hash bucket. Something like this should be decent, I think, haven’t
thought too much about it:
static inline uint64_t mix(uint64_t a, uint64_t b)
{
a *= 0xc6a4a7935bd1e995ULL;
a ^= a >> 47ULL ;
a *= 0xc6a4a7935bd1e995ULL;
return a ^ b;
}
This technique of quantizing continuous data, so we can hash it, is sometimes called “fuzzy hashing”. Weirdly, I actually worked on “fuzzy hashing” during my short stint in cryptography, before I got into game development.
With fuzzy hashing giving us a suitable hash key, we can now use all the techniques from before to create a database index for positions too.
Note that when searching this data structure, it is not enough to search a single hash bucket, because if the position P we’re querying for is closer to the grid edge than 5 m, then there may be objects in neighboring cells that are closer to P than 5 m.

Fuzzy hashing.
This approach suffers a bit from the curse of dimensionality. If we want to find an approximate match in n dimensions, we have to search 2^n cells. For 2D and 3D, which are our most common cases, it is still manageable though.
One thing you might ask yourself is: how big should the grid cells be? If you want to search for things within a 5 m range, but also for things within a 50 m range, won’t you need two indices with two different grid cell sizes? Because if you want to search with a 50 m range on a 10 m grid, you will have to search 36 cells.
Maybe. But I kind of think that is the wrong way of looking at it. You should pick the cell size based on the density of the objects, so that you expect to have some low number of objects, say 16 or so, in each group of 2^n cells.
If your search size is much smaller than this cell size, the grid is too coarse, but it doesn’t really matter. Things are still fast because you still only need to look at ~16 objects.
What if your search size is a lot larger than the cell size? Then you have to look at a lot of cells. Say your search size is 10 times larger than the normal search size, so you will have to examine 10² = 100 cells. That seems bad.
But, remember that each cell has ~16 objects. So in this case you would expect to find ~1600 objects. And that is regardless of the cell size – it is only determined by the size of your search and the density of the objects. Going through those 1600 objects will be pretty slow, no matter if they are all in one big grid cell or 100 small grid cells. So the grid cell size doesn’t matter as much as you might think.
Conclusion
In the previous post I described an efficient way of storing the bulk data of a system. In this post I showed how you can add search indices to this data to be able to quickly find all elements with certain properties. Combined, these two techniques fill the data storage needs of most systems.
There is one thing I haven’t looked at yet. What if our data records contain a dynamically sized field, such as a string? In this case we can no longer represent the data as a fixed sized POD struct, we have to come up with something else. I’ll look at this in the next post.