DLL Hot Reloading in Theory and Practice
I have before about how our plugin system enables in-place hot-reloading of plugin DLLs. Here is a little screen capture of it in action, using hot reloading to change the color and style of UI items:
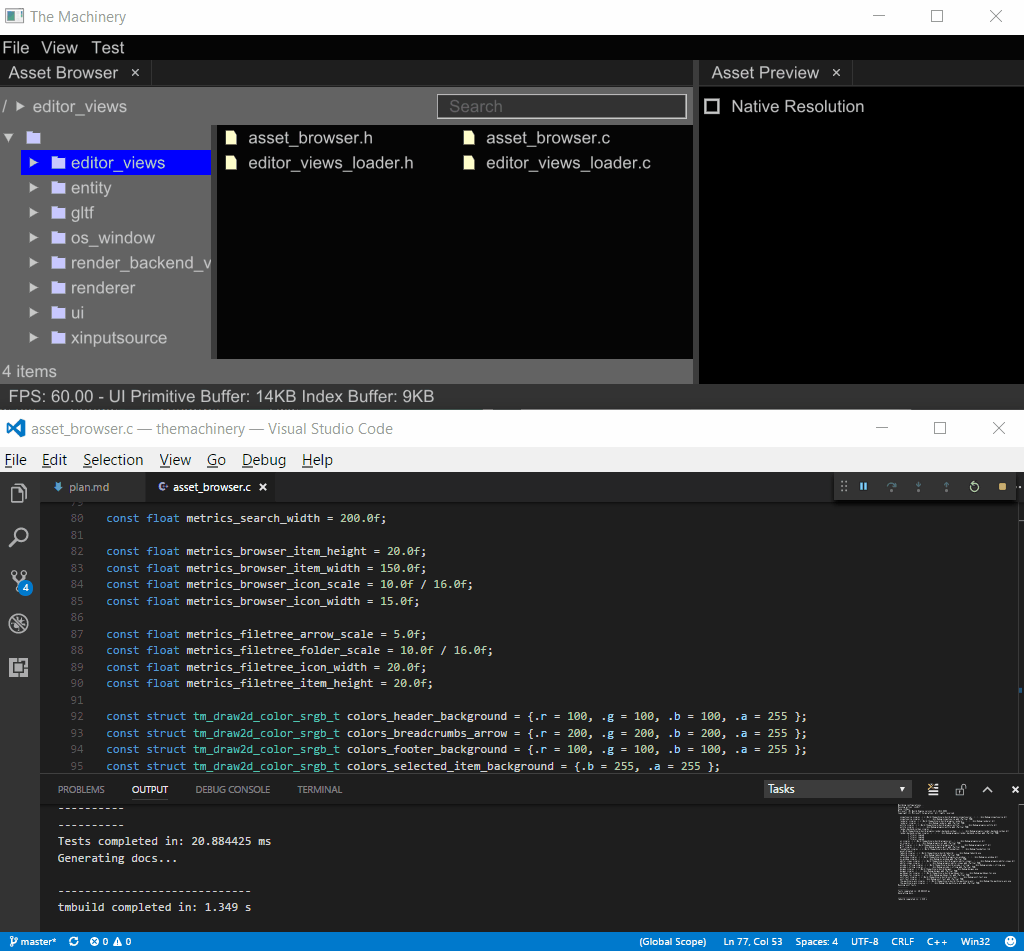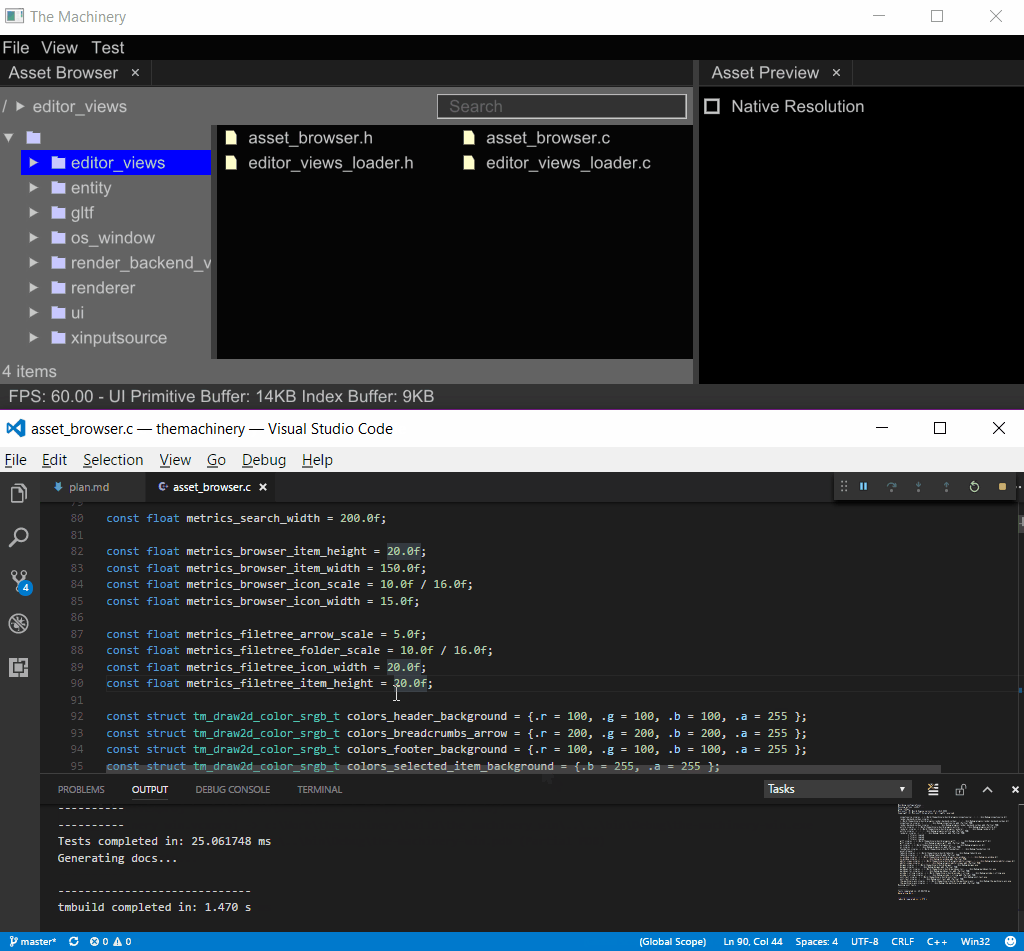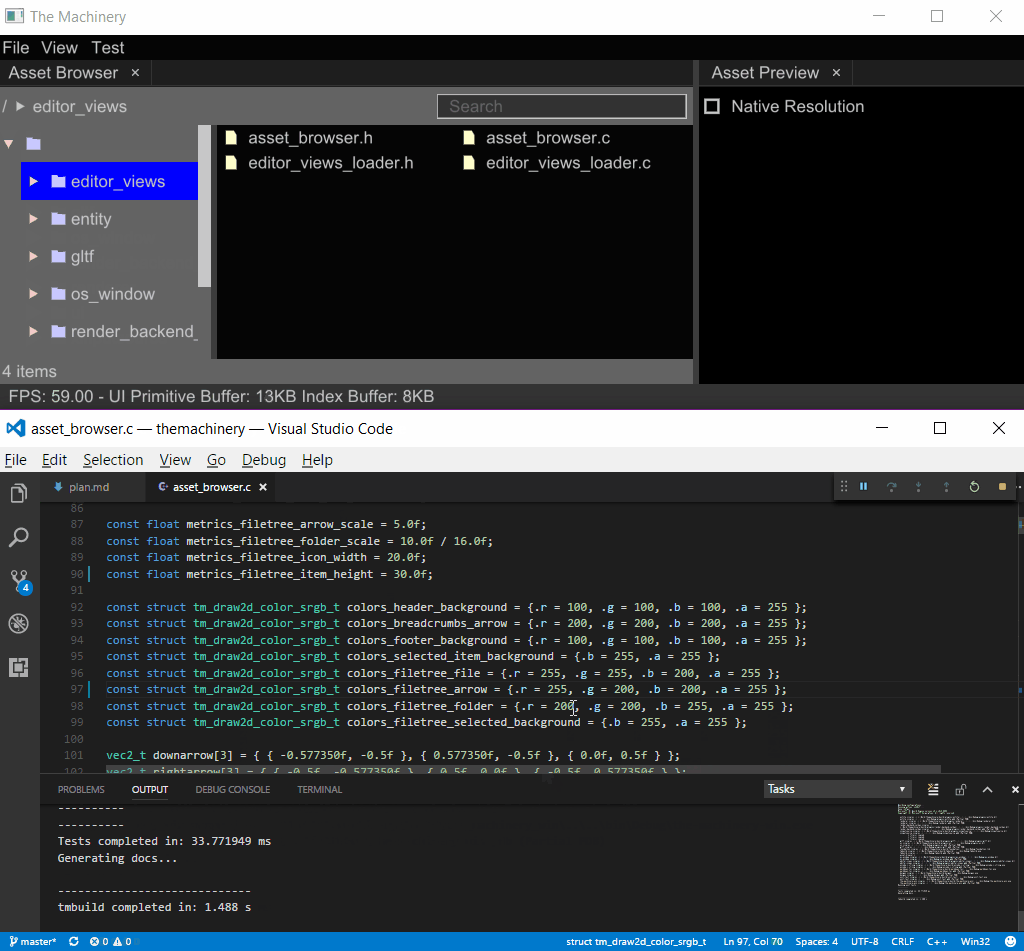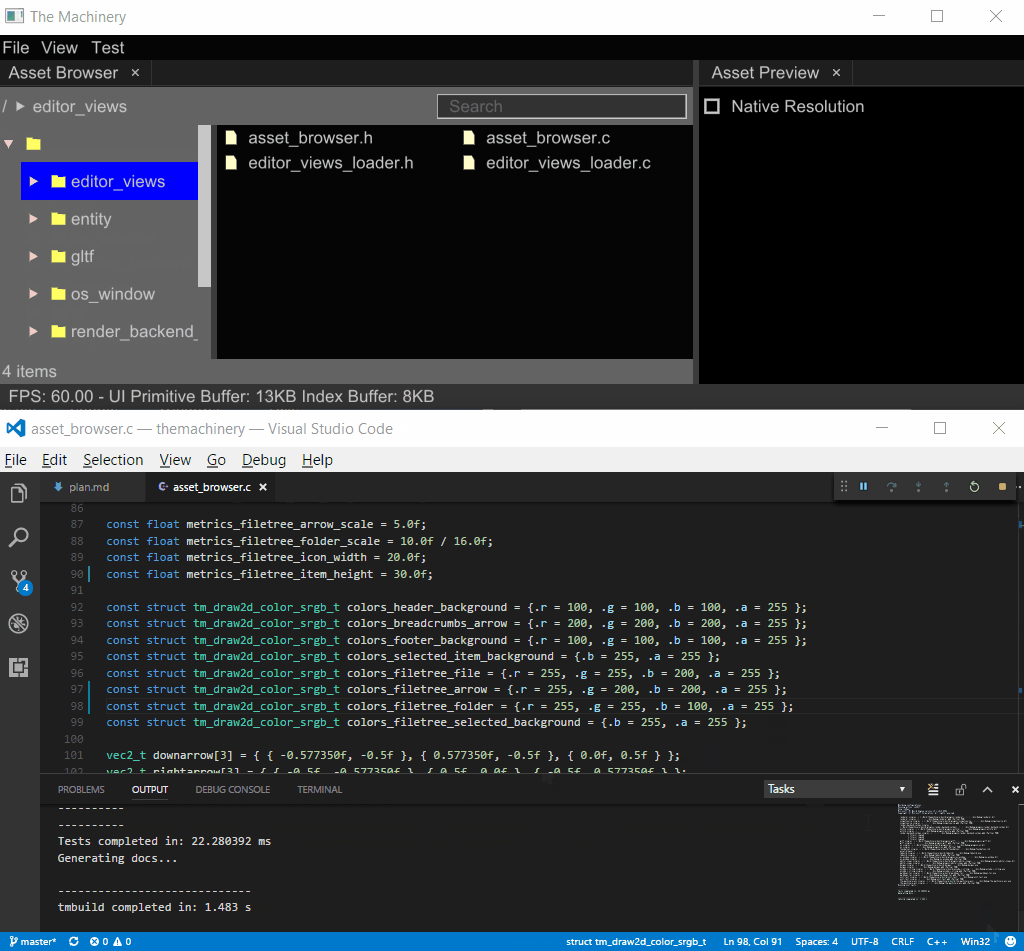
DLL Hot Reloading
To see the effects of my code changes, I simply press Ctrl-Shift-B in Visual Studio Code to build the project. This rebuilds the DLL, The Machinery sees the new DLL and hot reloads it into the application.
But hot-reloading goes way beyond simple tweaks like this. While working on the asset browser I was able to add whole new features, all using hot reloading. For example, for the file tree, I started by adding a splitter between the file tree and the main pane — hot reloaded to see that working. Then drew some dummy folders into that pane — hot reloaded again. Drew the whole file tree expanded — hot reloaded again. Added the UI code for expanding and closing folders — hot reloaded again. Of course, during the process, there were various minor and not-so minor bugs, that I also fixed with hot reloading.
Working like this is a real eye-opener. You get the power and performance of a statically compiled, highly optimized language, together with the dynamic and interactive workflows of a scripting language. If you haven’t tried it already you should really give it a go.
I think there are great benefits to having a hot-reload environment as your main workflow. And it makes me wonder a bit why there aren’t more people doing it. In theory, hot reloading is not that complicated. Just look at the documentation for LoadLibrary and GetProcAddress for how to load a DLL (or a new version of an old DLL) and get the function pointers from it.
In practice, it can be trickier. For this post I wanted to look at some of the things that make people shy away from hot reloading and how we address them at Our Machinery. Our solutions might not work for everybody, but hopefully our ideas can inspire others to make DLL hot reloading a more common development practice.
Some of the things that stop people from using DLL reloading are:
-
Complicated Architectures. DLL reloading is pretty straightforward in a straight C executable — just get the new function pointers and replace the old ones in some shared table. In a more complicated C++ setup with classes and inheritance, things are not as simple. Function pointers are hidden in vtables. Some functions may be inlined, which means you can’t really replace them. (But you could of course recompile the DLL that inlined them and reload that DLL too.) Hot reload is still doable in this scenario, but more complicated.
-
Long Build Times. If the build time for an incremental build is long, hot reloading won’t give you that feeling of immediately interacting with the executable that you get from a scripting language. This immediacy is one of the main reasons why we want hot reloading.
-
Bad Tooling. The Visual Studio Debugger is pretty painful to use with hot reloading. Probably because not enough people use hot reloading to make it worthwhile to make the workflows better. So this is kind of a chicken and egg problem. More people need to start using hot reloading to make the Visual Studio team see the importance of supporting hot reloading. Which is one of the reasons why I’m writing this article.
-
State Transfer. When a DLL is hot reloaded, any data that is “owned” by the DLL, including global variables, needs to be transferred from the old DLL instance to the new one. This is extra code that needs to be written just to support hot reloading. The amount of work depends on how you implement it.
-
Instability. Hot reloading exercises some code paths that are not used in the “regular” running of the application (for example state transfer). So there will be bugs during hot-reloading that are not seen during “regular” runs. If the whole development team uses hot-reloading, these bugs will be discovered and fixed quickly. But if only a small part of the team uses hot-reloading there is a risk that they will constantly run into bugs created by the rest of the team (because they are not testing the hot-reload path).
Let’s look at how we tackle each of these issues.
Complicated architectures
We are kind of drastic here and use C interfaces for all of our code. (The implementation can use C++, but the headers are all pure C.)
Our APIs are structs with function pointers. We put all the function pointers for an API in a struct to get a “namespace” and to make it easier to switch out the whole API on DLL reload:
struct tm_some_api {
void (*an_api_function)(...);
...
};
In addition to APIs (global functions, essentially), we also support “objects”. An object is a struct with function pointers (methods) and an opaque pointer to the instance data for the object. This instance data is passed to the methods when we call them. (It is essentially this in C++.)
struct tm_some_object_i {
struct tm_some_object_o *instance;
void (*a_method)(struct tm_some_object_o *instance, ...);
...
};
Patching the APIs for a DLL reload is easy. All the APIs are stored in a global lookup table. To patch an API we just replace all the function pointers in the API with the function pointers from the new DLL.
For objects we can do the same thing. The only tricky thing is that since the method pointers are stored in the objects themselves we need a list of all objects, so that we can go through them all and update the function pointers. So our plugins have to keep track of all the objects as they are created and destroyed, so we can go through them later, which is a bit painful.
It might make sense to switch to a more vtable-like approach. I.e. instead of keeping the function pointers in the objects themselves, we put them in a shared table (much as we do with the API). The objects themselves would point to this table, as well as the instance data. In other words, it would look something like this:
struct tm_some_object_vtable {
void (*a_method)(struct tm_some_object_o *instance, ...);
...
};
struct tm_some_object_i {
struct tm_some_object_o *instance;
struct tm_some_object_vtable *vtable;
};
Now, to reload the functions from the new DLL, we can just replace the function pointers in the shared vtable, and we don’t need to keep track of all object instances. We can even add new methods if we leave some empty slots at the end of the table. This is nicer, but it leads to slightly more complicated code for calling methods on the object:
// Without vtable:
obj->a_method(obj->instance, ...);
// With vtable:
obj->vtable->a_method(obj->instance, ...);
Might still be worth it… I need to think about this some more.
If you are using C++, and you are not using complicated things like multiple inheritance, etc, this approach might work for you too, since this vtable setup is essentially what C++ is doing. However you will need to write some OS/system specific code to access the vtable, since it is not exposed in C++. Also, I think you might run into trouble, because the vtable would be allocated in the memory space of the DLL, which is freed when you unload it. You may have to do some hackery in the constructor to patch your objects to use a globally allocated vtable that you can pointer-patch on reload. I haven’t really investigated this path, since it is not the road we took, so someone else is probably better qualified to write about how to solve these issues.
Another approach you could do with C++ is to hold all objects through handles instead of straight pointers. Then during reload you could serialize the object in the old DLL and deserialize it in the new one — essentially creating a new object and then update the handle to point to the new object. I will talk more about serialization later.
Long build times
We use a physical design where header files are not allowed to include other header files. This keeps build times down, both for total rebuilds and incremental builds. We also minimize the use of C++ templates which tend to have a big effect on build times.
Bad tooling
The main problem with Visual Studio is the file locks that you run into while debugging. These locks prevent DLLs from being rebuilt and consequently from being reloaded. The plugin.dll file is locked as the program is running and the plugin.pdb file is locked during debugging. Both of these problems can be dealt with, but unfortunately, as I discovered recently, this is not enough. The Visual Studio Debugger will also sometimes lock another file called vc141.pdb and this blocks rebuilding too. I don’t know exactly why this file is getting used and I haven’t been able to find any information about it. I don’t think the renaming tricks that we use for the regular DLLs and PDBs will work for this file, since it is not created by us. So far I haven’t been able to fix this and get reloads to work while the debugger is running.
Side note: @zeuxcg suggested to me to use the /Z7 flag. In theory, this should embed all the debugging data inside the executables and DLLs. So no PDB files should be created and PDB locking should not be a problem. Indeed, when I used the /Z7 flag no PDB files were created. But instead, Visual Studio created a 4 MB file called NONE and locked that instead. So back to square zero.
Another issue with reloading with the debugger is that even when it does work, any breakpoints set will not be set in the new instance of the DLL, so it is still painful to work with. Especially when trying to use the hot reload workflow to fix bugs. Of course the REALLY annoying thing is to try to fix bugs in the hot reload code itself — such as state transfer bugs.
For now, I’ve resigned to use detach/attach to work with the debugger while hot reloading DLLs. I’ll attach to look at something in the debugger, then detach to rebuild the DLL and hot reload it. Not ideal, but seems to be the best I can do for now.
State transfer
State transfer can be done with complete serialization — i.e., serialize all the objects from the old DLL and deserialize them in the new one. This is arguably “the right way to do it”, since in theory it will work for any kind of change — even changing the memory layout of objects.
If you already have a reflection system, then maybe you can do serialization almost for free (provided all your internal objects are also a part of the reflection system) and then this could be the right path to take. Note though that you also need a handle system for accessing objects, since when you deserialize them their memory location will be different.
In our case, we don’t use reflection and implementing serialization of everything would be a lot of work. We also use direct pointers to objects and data, which means they cannot be relocated. But fortunately, it is not that often that we actually change the memory layout and size of objects, so we’re ok with hot reload breaking for those cases.
Instead of full serialization, we do something a lot simpler. Objects are just left in memory as-is. They were allocated by the old DLL, but will be freed by the new DLL. Since both DLLs use the same allocator, this works without problems.
Global static data for the plugin (which includes the list of all active objects — remember, we need the list to patch the method pointers) are stored in a single struct:
struct state_t {
int32_t some_data;
...
};
static struct state_t state;
A pointer to this data is stored in the plugin API.
When we reload the plugin, we simply memcpy() the data from the old state to the new state:
void transfer_state(struct tm_some_api *new_api, struct tm_some_api *old_api)
{
struct state_t *old_state = old_api->state;
struct state_t *new_state = new_api->state;
memcpy(new_state, old_state, sizeof(struct state_t));
}
Note that this works well even if the state contains pointers to heap allocated objects. Those objects will continue to live in the heap, and we will eventually free them when the new DLL shuts down.
Contrast this with a serialization solution. Full serialization would require us to serialize, not only the object itself, but also all the other objects that it references, the objects that those objects reference, etc.
Note that in order to do the state transfer this way we need to have both the old DLL and the new DLL loaded in memory simultaneously so that we can copy data between them. Thus, we need to do DLL reload in this order:
- Load new DLL
- Copy data from old DLL to new DLL
- Unload old DLL
Instability
We are not a big team at Our Machinery and all of us are committed to hot reloading, so stability of that path is not a big concern for us. If that is not the case for you, maybe you can add hot reloading to your test suite, to make sure the path gets exercised.
Conclusion
I hope I’ve encouraged you to give DLL hot reloading a try, if not in your main application, maybe in some small side project. It can really be a game changer and we need a lot of people pushing for it to make it truly awesome.