Minimalist container library in C (part 1)
At Our Machinery, we’re strong believers in minimalism — we’re always trying to make things simpler and smaller. The more code you have in a project, the more you have to worry about. There is more to understand, optimize, debug, refactor, port, modernize, document, etc, etc. More code, more problems!
We also try to minimize the use of external libraries. This is perhaps more controversial. There are a lot of people that will tell you to not “reinvent the wheel”. And in some developer communities (looking at you, node.js) programmers will think nothing of adding a package dependency to pull in a three-line function.
Why are we reluctant to add external dependencies? Two reasons.
First, as developers of something that is more in the platform/engine/middleware space I think our perspective is different than that of an application developer. When you are developing an application — all you really need to care about is to make it work. If it is responsive enough and passes your tests, you are good to go. If you can drop in a big library to quickly add a new feature, that’s a fast win.
In our case, our end users are developers. We can’t predict in what ways they will use our code, nor would we want to limit them in any way. This means that they might run into performance problems or bugs that we have never thought about. So “it just works” is not good enough. Instead it must behave reasonably in a wide variety of different scenarios. Not only can’t we fully predict what the users will do — we also can’t fully predict what they will care about: is it application size, performance, compile time, running on an esoteric platform, etc? Making that kind of guarantee about a third-party library is tricky.
Second, even though an external library doesn’t add any code to our repository, it still adds code to the product. The code is still there, just in binary form — which makes things worse, because that makes it harder to know what is going on in that code.
The whole purpose of keeping the codebase small is to make it easy to change, which is the ultimate quality measure of any software endeavor. And the main problem with external libraries is that they are hard to change. First you have to understand the external codebase, which can be daunting. Then you either have to fork — which means you now own the maintenance burden of keeping the library running — or deal with the politics of pushing the changes upstream.
Of course, this doesn’t mean an absolute no to external libraries. We like small single-file source libraries with a well-defined purpose. We dislike big sprawling libraries with huge ambitions.
Container types
Today, I want to focus on a specific aspect of minimalism — our container types. By container types I mean common data structures such as queues, lists, stacks, arrays, etc. I.e. types used to collect and index objects in various ways.
As a fundamental building block, container types tend to have a big influence on the rest of the code. They can set the tone for the whole project. Also, changing your container types requires rewriting large parts of your code — in a large project it might be nearly impossible.
In earlier projects I’ve noticed that we had a lot of specialized collection types in our foundation library that were only used once or twice in our (pretty big) codebase. And even in those few cases, the benefits of using a special container were small — we could replace it with a more commonly used one and get rid of some code.
At Our Machinery, in the spirit of minimalism, we’ve taken this further and our foundation library only defines two container types:
- Arrays (or “stretchy buffers”)
- Hash tables
No lists, no trees, no strings, no queues, no sets, etc.
We found that arrays and hash tables are the only thing we only absolutely need. Arrays for general storage and hash tables for fast lookups. I’ll discuss how we handle strings and lists in a future blog post.
One important thing to note is that we use C, not C++ as our main programming language. This means that we can’t have generic container types, such as vector<T>.
I’m not a big fan of C++ templates in general. They bloat header files with implementation details. They often dramatically increase build times and code size. The error messages are incomprehensible. The abstractions are often not “zero-cost” (even if advertised to be). They encourage over-abstraction monsters like vector<T, allocation_policy, storage_policy, threading_policy, ...>. And template meta-programming requires really complicated code for seemingly simple things, such as a compile-time if-statement.
But they sure are nice for generic collection types, such as vector<T>!
The options for implementing container types without generics support are certainly lackluster:
- We could implement separate collection types for everything we want to store:
char_array,int_array,float_array, etc… ugh! - We could use a big
unionas a variant type and store an array of that… ugh! - We could do what
qsort()andbsearch()does and obliterate all type information, forcing the user to castvoid *to the right types… ugh!
Fortunately, we don’t just have C, we also have the magic (ahem) of the preprocessor!
Arrays (“stretchy buffers”)
Our array implementation is based on the “stretchy buffer” technique, popularized by Sean Barrett.
The basic idea behind the technique is to represent an array by a regular C pointer to the elements:
my_type_t *a = NULL;
A NULL pointer represents an empty array. If the array is not empty a will point to the elements of the array. However, and here’s the trick, just before the elements, we place a little header struct with the data that std::vector would normally keep track of:
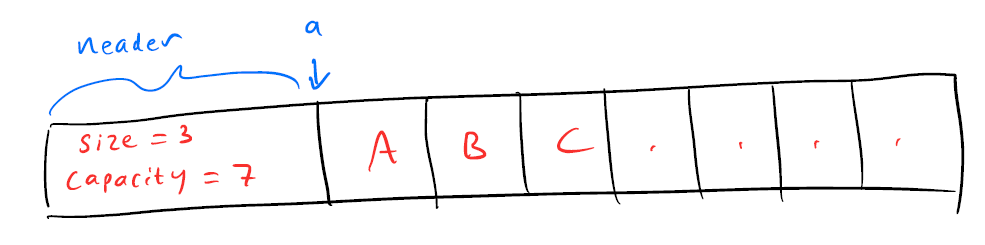
Memory layout of a stretchy buffer.
When we grow the array, we allocate data for both the header and the elements and then we update the pointer to point where the elements start.
struct array_header_t
{
uint32_t size;
uint32_t capacity;
};
Since the header is always located right before the array data in memory, we can get to it by just subtracting the size of the header from the data pointer. For example, here is a macro that gets the header from the pointer:
#define array_header(a) \
((array_header_t *)((char *)(a) - sizeof(array_header_t)))
Using this we can easily write a macro to get the size of the array:
#define array_size(a) ((a) ? array_header(a)->size : 0)
Note that we need to take some extra care to deal with the case where a == NULL.
Adding elements to the array will look something like this (parentheses removed for readability):
#define array_push(a, item) \
array_full(a) ? a = array_grow(a, sizeof(*a)) : 0, \
a[array_header(a)->size++] = item
Here array_full() is a macro that tests if size == capacity and void * array_grow(void *, uint32_t) is a regular C function that allocates new memory for the array. Note that it needs to be passed the size of the elements, since it has no type information. We use the comma operator to get multiple expressions in a single statement, and also take advantage of the fact that assignments are expressions in C. See the stretchy buffer implementation for more details.
The nice thing about this approach is that we get variables with the right type (my_type_t *a) without any need for generics. It is also really nice that a NULL pointer is a valid (empty) array. This means that default initialization x = {0} is enough to initialize a struct with arrays in it.
A drawback is that we need to use preprocessor macros instead of functions, which makes it a bit harder to debug and see what is going on. However, this is a necessity in C, since we don’t have generic functions.
Another drawback is that the stretchy buffer pointers are indistinguishable from regular pointers. I.e. we cannot tell if char *x points to a stretchy buffer or not. For now, I’ve taken to mark the buffer pointers with a comment, like this:
/* array */ char *x;
But it doesn’t feel like the best solution. It would be nice to find some way of doing this that also worked with debugger visualization, so we could see the size of the array in the watch window.
Hashes
In STL a hash table is implemented by std::unordered_map<K, T>. To make something similar in C, we could try to follow the stretchy buffer approach and define our hash table as:
key_t *keys;
value_t *values;
A header stored either in front of the keys or the values could store the size and capacity as well as pointers to any additional data we might need and we could define the appropriate macros we need to use these data structures, just as we did for the array.
However, I don’t think this is the best approach. In fact, we can simplify things a lot further.
In the most common use cases, the keys will be strings. This means that the key list is a variable length list of objects that are themselves of variable length. This is a pretty complicated setup that no matter how we do it will result in lots of heap allocation and pointer chasing.
And it is all for nothing, because typically (in the most common use cases) we never need to retrieve the keys themselves from the hash table — we are only ever interested in using the keys to lookup values.
We can get rid of all this by hashing the keys before we put them in the hash table. I.e. we just apply a hash function hash(key) → k and then use k instead of key as the key to the hash table.
The only caveat here is that we must hash they key into a large enough key space to be (statistically) sure that we don’t have any collisions, because if hash(key_1) = hash(key_2) we won’t be able to store both key_1 and key_2 in the hash table. Our hash tables tend to be reasonably sized, so a 64 bit hash is enough, but you could go to 128 bit if needed.
We can apply the same trick to the values. There is no need for the values to be stored in the hash table itself (in fact, that can be kind of expensive if the values are large — since hash tables have holes). We already have a perfectly good way of storing a collection of objects of an arbitrary type — the array! So instead of putting the values in the hash table, we can just store them in an array and put their indices in the hash table.
Note that if you need to delete keys from the hash table, you probably want to keep a freelist for the array to mark empty slots that can be reused. Alternatively, you could move the last element to the deleted slot to keep the array packed, but then you need to update its index in the hash table, so you need to keep track of its key.
We have now gotten rid of both the key type and the value type which means we don’t need generics or preprocessor tricks to implement our hash table, instead we can just define it as:
struct hash_t
{
uint32_t num_buckets;
uint64_t *keys;
uint64_t *values;
};
And then we define functions to operation on this, such as:
uint64_t hash_lookup(const struct hash_t *hash, uint64_t k, uint64_t default_value);
Note that if the keys or values are smaller than 64 bits we can take a shortcut and store them directly in the hash table, we don’t need the hash function or the extra array.
(We actually have two versions of the hash table in our code, to save some memory: hash64_t which uses 64-bit values as above and hash32_t which uses 32-bit values.)
Adding a value to the hash table looks something like this:
hash_t info_lookup;
/* array */ info_t *info;
array_push(info, my_info);
hash_add(&info_lookup, hash_string("my name"), array_size(info) - 1);
Note that since the hash structure just contains an array of uint64_t it can be searched and copied really quickly.
Follow-up
In the next post I will show how these two simple container types can be used to build more complicated data structures.