Minimalist container library in C (part 2)
In my last blog post I talked about how we only have two basic container types in our foundation library: arrays (“stretchy buffers”) and hashes. Today I’ll elaborate a bit on how we create more complicated types from these basic building blocks.
Sometimes you don’t need a dynamic container
Before I get started on that though, I want to quickly note that in many cases you don’t even need a dynamic container. If you know the maximum number of items you are ever going to store, you can just use a regular fixed size C array:
enum {MAX_ITEMS = 64};
uint32_t num_items;
item_t items[MAX_ITEMS];
A caveat here: you should be careful with what you assume when you size these arrays. MAX_MONITORS = 8 may seem reasonable, but some people are crazy.
{kind=link}
On the other hand, there is no reason to go to the other extreme either and require everything to be infinite. A menu bar with four billion items is not going to be usable in practice. To figure out when you can use a fixed size array consider this:
-
When you define the API, you can set its boundary conditions. For example, it is perfectly reasonable to say that your API only supports window titles of 512 characters or less, that your log window will only remember the last 1024 messages, etc, etc.
-
Just make sure that your code behaves nice at the boundary conditions. I.e., if someone passes in a longer title, you should truncate it rather than overrun the buffer.
When you don’t define the API you don’t have that luxury. I.e. if the OS supports infinite filenames, your application needs to do it too.
The nice thing about fixed sized arrays is that you can allocate them on the stack or store them in another array without any need for pointer indirection, which makes the code simpler and is nice on the cache. For example:
enum {MAX_PLAYER_NAME_LENGTH = 32};
enum {MAX_PLAYERS = 16};
struct player_t {
char name[MAX_PLAYER_NAME_LENGTH];
uint32_t score;
};
struct players_t {
struct player_t players[MAX_PLAYERS];
uint32_t num_players;
};
In C++ land you sometimes see fixed size arrays represented by a template class FixedArray<T>. In my opinion, that’s a totally unnecessary overabstraction, since operations on a fixed size array can be written as simple one-liners:
// Push back: items.push_back(x)
items[num_items++] = x;
// Pop back: items.pop_back()
--num_items;
// Swap erase: std::swap(items.begin() + idx, items.back()); items.pop_back();
items[idx] = items[--num_items];
Some people don’t like code like this. They will say that any code that uses postfix and prefix operators is “full of tricks” and “unreadable”. Needless to say, I don’t agree.
The first time you see these operations they may seem tricky and you might need to take a second to figure out what they do, but once you get used to them you will start to immediately recognize them as common idioms. It’s nice to be able to write them tersely as a one-liner. It is also nice to have the code right there and not have to go look up a macro or function definition in a different file to figure out what’s going on.
While I’m talking about idioms — here’s the idiom for writing an iterator-style for loop in C:
for (item_t *it = items; it != items + num_items; ++it)
// Do something with it
Note how this is shorter than the C++ counterpart:
std::vector<item_t>::iterator end = items.end();
for (std::vector<item_t>::iterator it = items.begin(); it != end; ++it)
// Do something with it
The “modern C++” variant is shorter, but consider how many concepts you need to know to understand it: iterators, auto, references:
for (auto &it : items)
// Do something with it
Quick: should that be auto, auto & or auto &&?
In addition to fixed size arrays, fixed size hash tables can also sometimes be useful. Sometimes you have a fixed number of items to look up and don’t need the hash table to grow beyond that. Here’s a little 30-line implementation:
static const uint64_t HASH_UNUSED = 0xffffffffffffffffULL;
typedef struct hash32_static_t
{
uint64_t *keys;
uint32_t *values;
uint32_t n;
} tm_chash32_static_t;
static inline void hash32_static_clear(hash32_static_t *h)
{
memset(h->keys, 0xff, sizeof(*h->keys) * h->n);
}
static inline void hash32_static_set(hash32_static_t *h, uint64_t key, uint32_t value)
{
uint32_t i = key % h->n;
while (h->keys[i] != key && h->keys[i] != HASH_UNUSED)
i = (i + 1) % h->n;
h->keys[i] = key;
h->values[i] = value;
}
static inline uint32_t hash32_static_get(const hash32_static_t *h, uint64_t key)
{
uint32_t i = key % h->n;
while (h->keys[i] != key && h->keys[i] != HASH_UNUSED)
i = (i + 1) % h->n;
return h->keys[i] == HASH_UNUSED ? 0 : h->values[i];
}
Strings
The Machinery doesn’t have a data type for strings. I wrote a blog post about this a long time ago. To sum it up, I find std::string to be highly overrated:
-
You should almost never use strings in your runtime (prefer hashes).
-
The strings you use should almost always be static. Thus, they can be represented by a
const char *and do not need a string class. -
For the few cases where you need dynamic (growing/shrinking strings),
std::stringis rarely a good choice. (Appending lots of strings is an O(n^2) operation.)
So how do we deal with dynamic strings? My experience is that most of the time when you do some dynamic string operation, you only need the result temporarily. For example, you might write something like:
std::string path = dir + "/" + file;
open_file(path);
In Our Machinery we handle this with a printf function that uses our temporary allocator system:
char *p = tm_temp_allocator_api.printf(ta, "%s/%s", dir, file);
open_file(p);
This call allocates memory for the string using a temporary allocator, prints the formatted string to that memory and returns it. Unless you allocate a lot of memory, the temporary allocator can get its memory from the stack, which means it doesn’t even touch the heap. Also, I personally prefer using printf() over appending std::strings with operator+.
The other common use case for dynamic strings is when you build up a long string by adding multiple pieces to it. In C++ you might use a std::ostringstream for this, if you happen to like the <iostream> interface, which I don’t. So instead we use — you guessed it — printf!
For this case, we have a separate printf() function that appends the printed text to a stretchy buffer. Here is how it’s implemented, based on the stretchy buffer macros discussed in the last post:
static void array_vprintf(char **a, const char *format, va_list args)
{
va_list args2;
va_copy(args2, args);
int32_t n = vsnprintf(NULL, 0, format, args2);
va_end(args2);
uint32_t an = tm_carray_size(*a);
array_ensure(*a, an + n + 1);
vsnprintf(*a + an, n + 1, format, args);
array_resize(*a, an + n);
}
static void array_printf(char **a, const char *format, ...)
{
va_list args;
va_start(args, format);
array_vprintf(a, allocator,format, args);
va_end(args);
}
// And the usage:
char *a = 0;
array_printf(&a, "Some text: %d\n", 3);
array_printf(&a, "More text: %d\n", 4);
Note the rarely used va_copy() to duplicate the va_list so that we can call vsnprintf() twice — once to get the size of printed string so we can allocate memory for it, and a second time to generate the output. Also note the trick of allocating memory for the NUL byte at the end of the string, but not including that in the size of the array. That way, the array is always terminated by a “virtual” zero and we can use all the normal C string operations on it.
Arrays of arrays
std::vector<T> properly calls constructors and destructors as objects are added and removed. This means that we can use it to represent things such as an array of arrays: std::vector< std::vector<int> >.
Our stretchy buffer implementation treats it’s elements as raw memory blocks, and doesn’t call constructors or destructors, so if you naively try to make an array of arrays it doesn’t work.
What we do instead is store array pointers and then manually allocate/deallocate them as necessary. For example, we might have a setup like this:
struct item_t
{
/* stretchy buffer */ int32_t *ints;
...
};
/* stretchy buffer */ item_t *items;
Now, before we free the stretchy buffer of items, we must loop over the elements and make sure we free all the ints buffers:
for (item_t *i = items; i != array_end(items); ++i)
array_free(i->ints);
array_free(items);
Part of the argument for destructors in C++ is that this kind of programming is dangerous. It is easy to forget to delete the i->ints object and create a memory leak.
However, in The Machinery we track all memory allocations and at the shutdown of the program we verify that all allocations have been freed. If memory is leaked somewhere we print an error message with the file and the line number where the leak happened, allowing it to be promptly fixed.
This means that this programming practice is much less dangerous. Indeed, since I started using allocation tracking (several years ago), bugs like this have never been a problem. If you don’t yet track and verify your memory allocations, I strongly suggest that you do so.
If you still prefer the C++ way, there are ways of implementing something similar in C with macros that call constructor and destructor functions for your classes. For example, have a look at this library: http://troydhanson.github.io/uthash/utarray.html
Personally, I prefer the more straightforward approach of treating everything as raw bytes and doing some explicit allocation/deallocation when necessary. It is a bit of extra typing, but it is easier to see what goes on and where memory is being copied when you have nested containers, something that can be tricky with something like map<string, vector< vector<int> > >.
Arrays of strings
An array of strings is just a special case of an array of arrays (if you see the strings as arrays of characters), so we could use the same strategy as we did for arrays of arrays.
However, as mentioned above, strings are mostly immutable, so what we are usually interested in is an array of immutable strings — not an array we want to push_back() bytes onto each individual string.
A vector<T> or a stretchy buffer will usually overallocate the memory by 50 % to ensure that push_back() has an amortized constant cost. If the strings are immutable, we can get rid of this overhead and also the pointer chasing and allocator churn that comes from allocating each string as an individual heap object by just packing all the strings into a single big memory block and then use an array to hold pointers into this memory block:
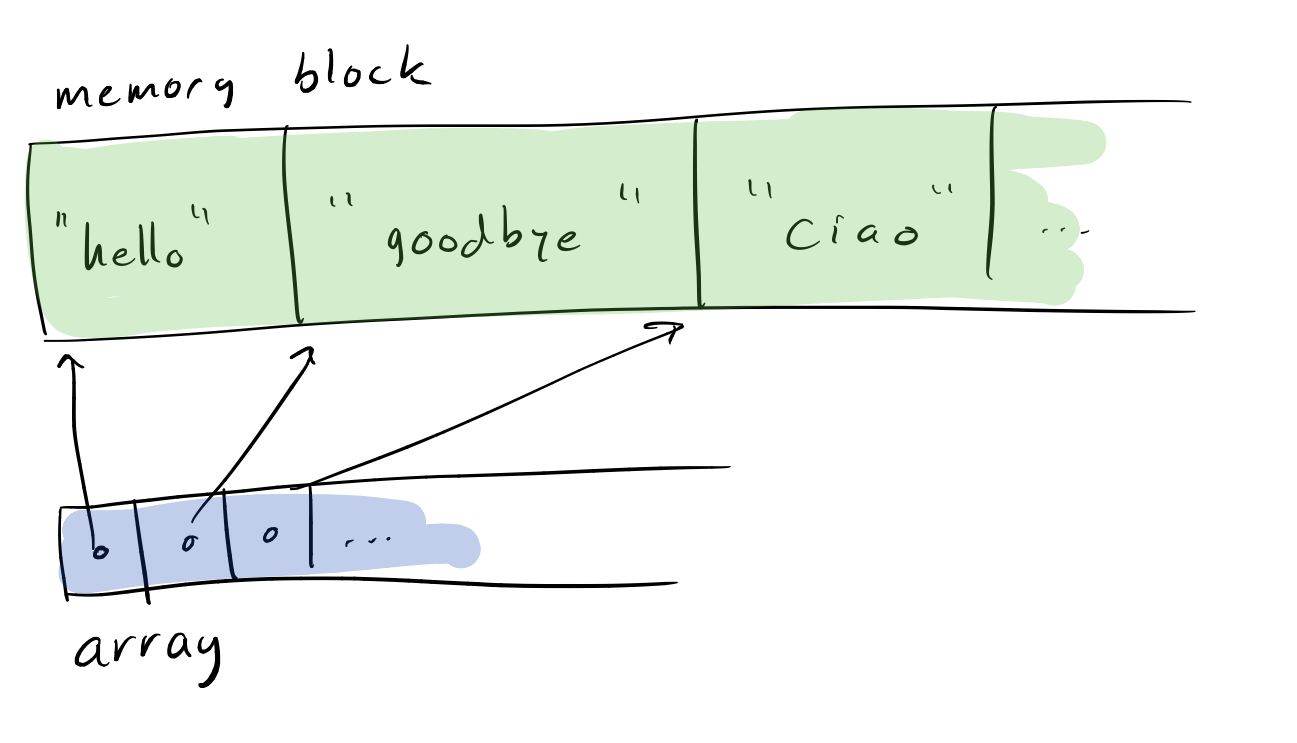
Array of strings using a single memory block for string data.
Here’s some some sample C code for pushing a string to a structure like this:
struct array_of_strings {
char *block;
uint64_t block_used;
char **strings;
};
void push(struct array_of_strings *a, char *s)
{
uint64_t n = strlen(s) + 1;
array_push(a->strings, a->block + a->block_used);
memcpy(a->block + block_used, s, n);
a->block_used += n;
}
Of course, for this to work, you need to somehow size the memory block so that it has room for all the string data. You could use the virtual memory trick and create the memory block as a near-infinite virtual alloction. Another approach is to use multiple blocks (again allocated directly from the VM) and just allocate another one when the last one is full. You can chain the blocks together with pointers so that you can easily find them all when it’s time to release the memory. Finally, you could just use a stretchy buffer of char for the memory block. In this case though, you probably want the array to store offsets into that block instead of direct pointers, since the pointers will change when the block is reallocated.
Strings don’t have to be totally immutable with this approach. You can update a string by pushing the new content to the end of the buffer and update the char * in the index. This will create some garbage in the array (so will removing a string), but unless the strings are mutating like crazy this is probably still a good approach.
There are various ways of dealing with the garbage. You could try to reuse it for new strings, which essentially amounts to creating a little local memory allocator for your string buffer. Or, a simpler approach, you could just keep track of how much garbage you have and simply copy everything to a new buffer once you have “too much”. This is essentially a copying garbage collection. It is really easy to make incremental too, if you need it.
But most of the time, I find there is no need to get too fancy, because I seldom have a need for storing strings that change a lot.
If you combine this with a hashtable for string lookup you can use it as a way of “interning” strings. This is a useful way of storing for example a JSON document. Here, the strings typically don’t mutate and we also see the same string repeated hundreds of times in the same document, so a std::string representation is really wasteful. With interning, you only need to store repeated strings a single time in the string buffer.
Lists and trees
Instead of having special data structures for lists and trees I like to store them in arrays. Indices into the array replace node pointers. This means we avoid making lots of small allocations, and all the nodes are together in memory which is good for the cache.
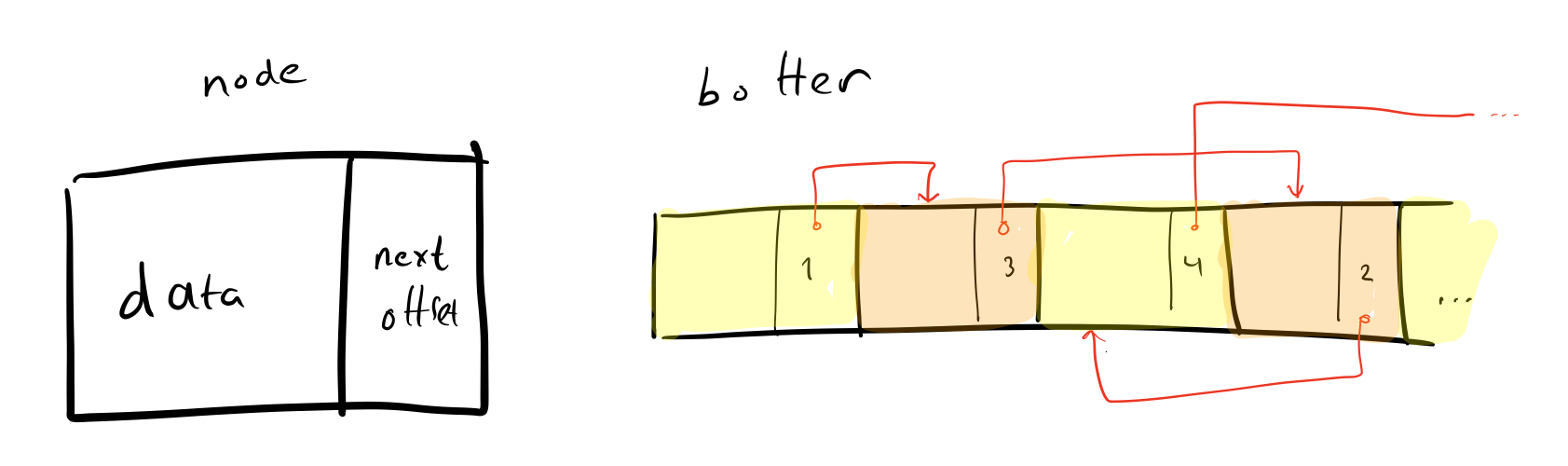
Singly linked list stored in an array.
With this approach, a doubly linked list might be:
struct node_t
{
uint32_t prev;
uint32_t next;
item_t data;
};
node_t *list
Here, list is a stretchy buffer with all the nodes.
Given this, you could easily write generic macros to do common list operations such as push_back(), push_front(), etc. But I usually just write them out as functions specific for a particular list type instead. It’s just a few lines of code and makes it easier to see what is going on.
A general tip when it comes to dealing with lists is to link them up in a circle and have a dummy node that represents the head of the list. Like this:
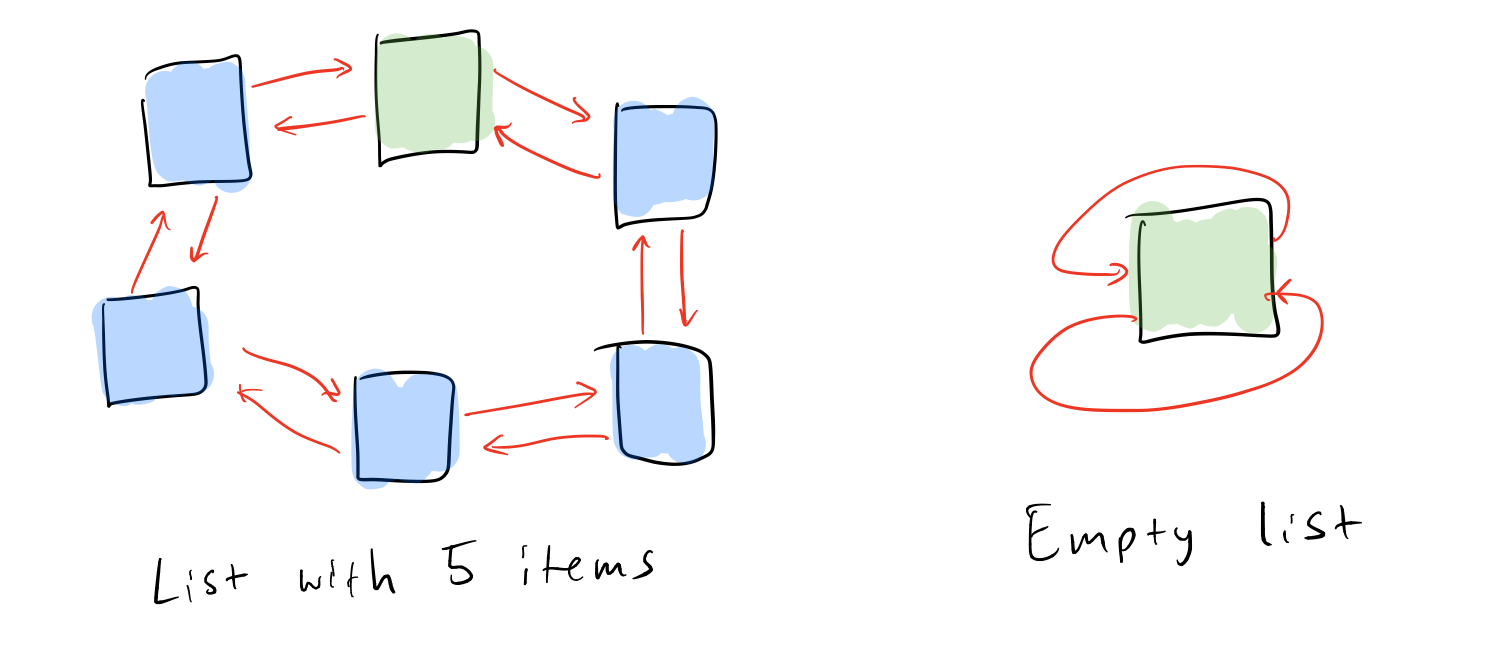
Linking linked lists in a circle.
The nice thing about this is that all the list pointers are always connected, so you never have to deal with special cases of NULL pointers. This makes the algorithms a lot simpler. Also, the list_t structure becomes simpler, because you don’t need explicit pointers to the start and end of the list. We put the dummy node first, so nodes points to it. The first element of the list is then nodes->next and the last element is nodes->prev, unless the list is empty, in which case nodes->next == nodes->prev == 0, i.e. the prev and next pointers of the dummy node point back to the node itself.
Here are some sample list operations:
// Initializing the list (creating the dummy node)
array_resize(list, 1);
list->next = list->prev = 0;
// Allocating a new node
array_resize(array_size(list) + 1);
uint32_t n = array_size(list) - 1;
// Adding it to the front of the list
list[n].next = list->next;
list[n].prev = list;
list[list[n].next].prev = n;
list[list[n].prev].next = n;
// Removing it
list[list[n].next].prev = list[n].prev;
list[list[n].prev].next = list[n].next;
When we remove an element from a list we will leave a “hole” in the node array. However, since all the list elements are of the same size, we can reuse that for another element later. We just need to somehow keep track of these free elements for reuse. Luckily we already have a way of doing that — a list! We can store another list in the same buffer, all we need is another dummy element.
Since list[0] holds the dummy element for the list, let’s just use list[1] as the dummy element for this other list — the list of free elements. Whenever we remove something from list[0], we just put it on list[1]. And before allocating a new element, we check list[1] to see if it has an element we can reuse instead.
Since I feel like typing a lot of sample code in this post, here’s some sample code for that:
// Initializing the list (creating the two dummy nodes)
array_resize(list, 2);
enum {FREE = 1};
list->next = list->prev = 0;
list[FREE]->next = list[FREE]->prev = FREE;
// Allocating a new node
uint32_t n = 0;
if (list[FREE]->next != FREE) {
n = list[FREE]->next;
list[list[n].next].prev = list[n].prev;
list[list[n].prev].next = list[n].next;
} else {
array_resize(array_size(list) + 1);
n = array_size(list) - 1;
}
For a doubly linked list you could also reclaim the memory immediately by moving the last element of the list into the “hole” and updating the prev and next pointers of its neighbors. Note though, that this requires that you have no external data structures “pointing” to the list element, because in that case, they too would have to be updated.
Trees can be handled the same way as lists. We put the nodes in an array and use offsets as pointers. But to be honest, there are not many situations where I would use a tree structure. In fact, I don’t think The Machinery source code contains a single tree.
Specialized data structures
In the cases where a generic array or hash doesn’t work I use a specialized data structure for that specific problem. That’s either because:
-
I have a need that the generic container doesn’t fulfill.
-
I know something about how the data is used, that the generic container can’t assume and by taking advantage of that I can get a significant performance improvement over the generic container (an array of immutable strings is one example of that).
For example, I may want an array not to deallocate its data when it is resized, so that readers on another thread can continue to access it. This is not something that the generic array implementation can (or should) do.
Another example: for an array that I know is going to be pretty large — instead of allocating a single contiguous buffer, I might allocate “blocks” of array elements directly from the VM. This way, the array can grow without the need to reallocate and copy the entire thing, something which can be pretty expensive and cause a hitch when the array grows over several MB.
A third example: for things like logs and profiler data I don’t want them to grow and shrink uncontrollably, churning the memory system. Nor do I want the application to stall waiting for them to be “flushed”. So I just allocate a fixed size block and use it as a ring buffer.
For an example of a (highly specialized) data structure see my post about multi-threading The Truth.
When it comes to specialized data structures like this I don’t try to create a “generic” solution — e.g. a reusable BlockBasedArray<T, BLOCK_SIZE>. I think that would kind of defeat the purpose. The whole point of a specialized data structure is to take advantage of the specific needs of that piece of code. And being specific and generic at the same time doesn’t make a whole lot of sense.
Instead, I make a custom data structure in the system that needs it, matching its specific requirements. I realize that making custom data structures like this can seem daunting of error prone if you are not used to it. (I remember finding it hard to juggle the pointers of a double linked list when I first started programming.) But with experience it becomes easier and easier, and after a while you will think nothing of it. I make use of arrays and hashes where it makes sense and try to keep the code as simple as possible. As you can see from the examples above, a lot of data structures can be implemented in 20–30 lines, when you only need a few specific operations.
Some final thoughts
For a long time, the lack of generic container support was the main thing (in addition to RAII maybe, though I find defer nicer) that prevented me from moving from “simple, no bullshit C++” to “plain old C”. Even after starting to work on The Machinery with C as the main interface language, I would still keep some implementations files in C++ just to get access to the generic containers.
Now, almost a year in, I don’t feel that way anymore. The “stretchy buffers” feel as natural to me as vector<T>. In fact, their simplicity actually makes me prefer them. (If I could just get natvis working, I would be golden.) I like our simple hash tables way better than std::unordered_map<Key, T, Hash, KeyEqual, Allocator>. And at this point, we’ve rewritten almost all the files that were originally C++ into plain C (just one left). It is nice to have everything in the same language and C is so many magnitudes simpler than C++. It’s definitely the right language for us, though maybe not for everybody.