Multi-Threading The Truth
For the last week I’ve been working on making a big engine system thread-safe. I found that there is relative little information out there on how to multi-thread actual, real-world systems (if you need something faster than a single global lock). Most of the articles I found focused on simple data types, such as linked lists. So I thought it would be interesting to share my experiences.
The Truth is our toungue-in-cheek name for a centralized system that stores the application data. It is based around IDs, objects, types and properties. An object in the system is identified by a uint64_t ID. Each object has a set of properties (bools, ints, floats, strings, …) based on its type. Using the API looks something like this:
uint64_t asset_id = the_truth->create_object_of_type(tt, asset_type);
the_truth->set_string(tt, asset_id, ASSET_NAME_PROPERTY, "foo");
The Truth is the place where other systems read and write their data. They can of course use internal buffers too, for better performance, but if they want to share data with the outside world, it goes through The Truth.
In addition to basic data storage, The Truth has other features too, such as sub-objects (objects owned by other objects), references (between objects), prototypes (or “prefabs” — objects acting as templates for other objects) and change notifications.
Goals of the design
Since The Truth is a low-level system that we expect to shuffle a lot of data through, it is important that the design is performant. Having a single lock for the entire Truth certainly won’t cut it. We need to have many threads accessing the Truth simultaneously. At the same time, we don’t want to have to obtain a lock for every single piece of data that we get from the Truth either, because that could be costly too.
So we’re looking for something like this:
-
Read/get operations should not require any waiting/locking.
-
Write/set operations may require waiting/locking, but they should only lock the actual object that is being touched. Threads should be able to write to different objects without contention.
One problem is immediately obvious here: If get() doesn’t use any locks, how can we make sure that the data we are reading is not being trashed by a simultaneous set() operation?
Luckily, we are rescued by the concept of atomicity. On modern hardware, writes and reads of aligned 64-bit values are atomic. I.e., other threads will always see either the old 64-bit value or the new 64-bit value, never 32 bits from one and 32 bits from the other. So as long as we are only writing 64-bit values, get() and set() can run simultaneously on the same object without creating problems.
Unfortunately, we also have larger objects that we want to store, such as strings or sets. Luckily, we can handle those with pointers. Instead of writing a string piece by piece, which could result in a garbled up value, we can just write a new char * into the object. This is a 64-bit value which can be written atomically.
In fact, we can take this one step further. Instead of writing individual values we can just create a whole new copy of the object, change some values and then atomically replace the old copy with the new one in a lookup table:
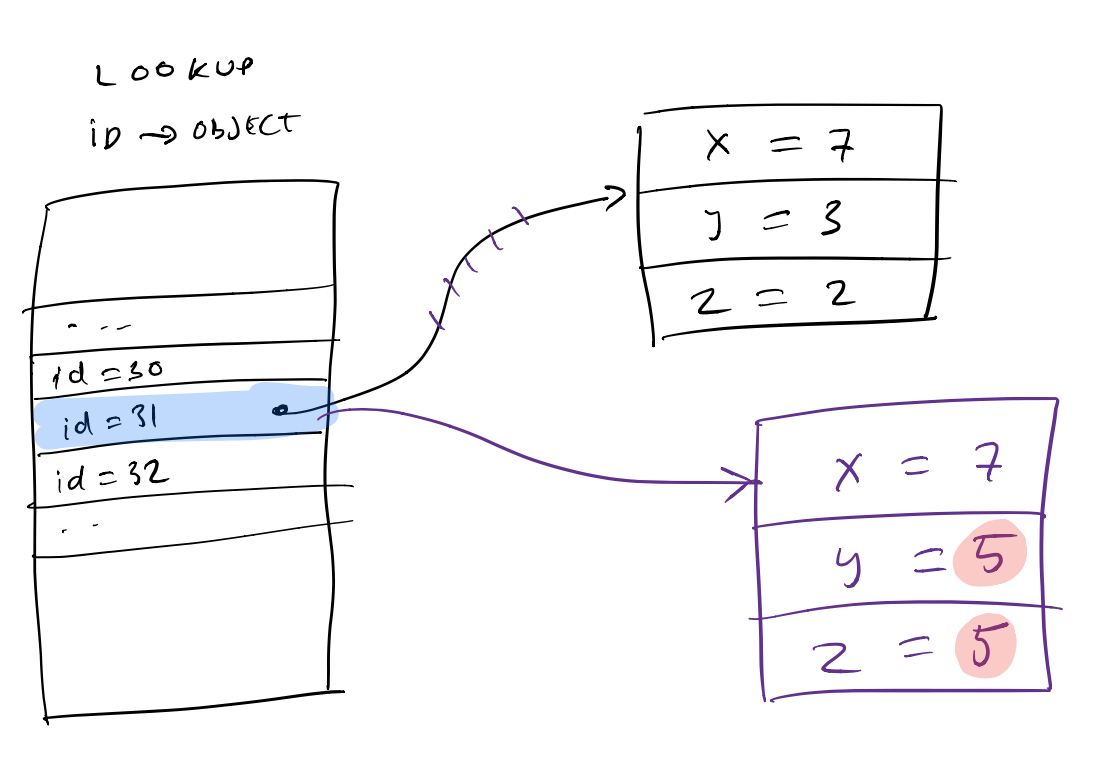
Object lookup table.
We could have this copying and replacing be implicit and completely hidden behind the get/set function interface, but that has two drawbacks:
-
The reader could see objects in a “half-written” state. I.e. even though each individual property would be either fully written or not, the properties themselves could come from different versions of the object. I.e. a reader could see
y = 5andz = 2, an object which never existed. -
If a writer wants to set multiple properties (which usually is the case) we would have to copy the object multiple times behind the scenes, which is inefficient.
So instead, we make the interface explicit. We require a read() or write() operation to get a pointer to the object, and a commit() operation to finalize the writes:
const object_o *reader = the_truth->read(tt, id);
float x = the_truth->get_float(tt, reader, POSITION_X_PROPERTY);
float y = the_truth->get_float(tt, reader, POSITION_Y_PROPERTY);
float z = the_truth->get_float(tt, reader, POSITION_Z_PROPERTY);
object_o *writer = the_truth->write(tt, id);
the_truth->set_float(tt, writer, POSITION_Y_PROPERTY, 5.0f);
the_truth->set_float(tt, writer, POSITION_Z_PROPERTY, 5.0f);
the_truth->commit(tt, writer);
Note that with this change, the reader’s pointer will either point to the new or the old object, so the reader will either see (7, 3, 2) or (7, 5, 5), never (7, 5, 2).
Also note that what we are doing here is pretty similar to how version control works — we are creating a new version of the object. This is also why I choose the name commit().
Also also note that we can’t delete the old object when we commit(), because there might still be readers that are using that old object (more on that later).
Some notes on consistency
With this design we are saved from reading half-written values. We are also saved from reading half-written objects. But we still can have other consistency problems.
The simplest one is a write conflict. What if two writers start writing the same object simultaneously? They will both get a copy of the old object, change some values and then commit. Whoever commits last will overwrite the other writer’s values.
A more complicated consistency problem can occur when multiple objects depend on one another. For example, a writer might do this:
- Remove the reference from object A to object B.
- Delete object B.
A reader could read object A before step 1 and discover the reference to B, then after step 2 attempt to access B. This would fail, since B is now deleted.
A classic example of the same problem in the database world is moving money between accounts. With withdrawing the money from one account and adding it to the other as separate operations a reader could see money appearing out of thin air.
Interestingly, we can solve both these problems without forcing the reader to lock.
To solve the write conflict, we can use the compare-and-swap (CAS) instruction which is available on all modern CPUs and also through the atomics library in C11 and C++11. Compare-and-swap atomically writes a 64-bit value only if the value there matches our expectation. Otherwise, it leaves the old value alone. It also tells us whether the write succeeded or not.
We can change commit() so that instead of just writing the new pointer, it does a CAS with the pointer we initially used to obtain our write-copy of the object. This means that the commit() will only succeed if the object hasn’t changed since we obtained it. In our example above, the second writer’s commit() would fail, and the object would keep the values set by the first writer.
To solve consistency problems involving more than one object, such as the money transfer, we need some kind of transaction mechanism. In other words, we need to be able to commit the changes to multiple objects simultaneously and have the reader see all these changes at once. This might seem tricky, initially, because we can only write one atomic value at a time. But we can repeat the trick we did before, when we need to write a bigger value, we just write a pointer to that value instead.
In this case, the pointer we can replace is the pointer to the entire lookup table. By replacing the lookup table, we can replace as many individual objects in it as we like:
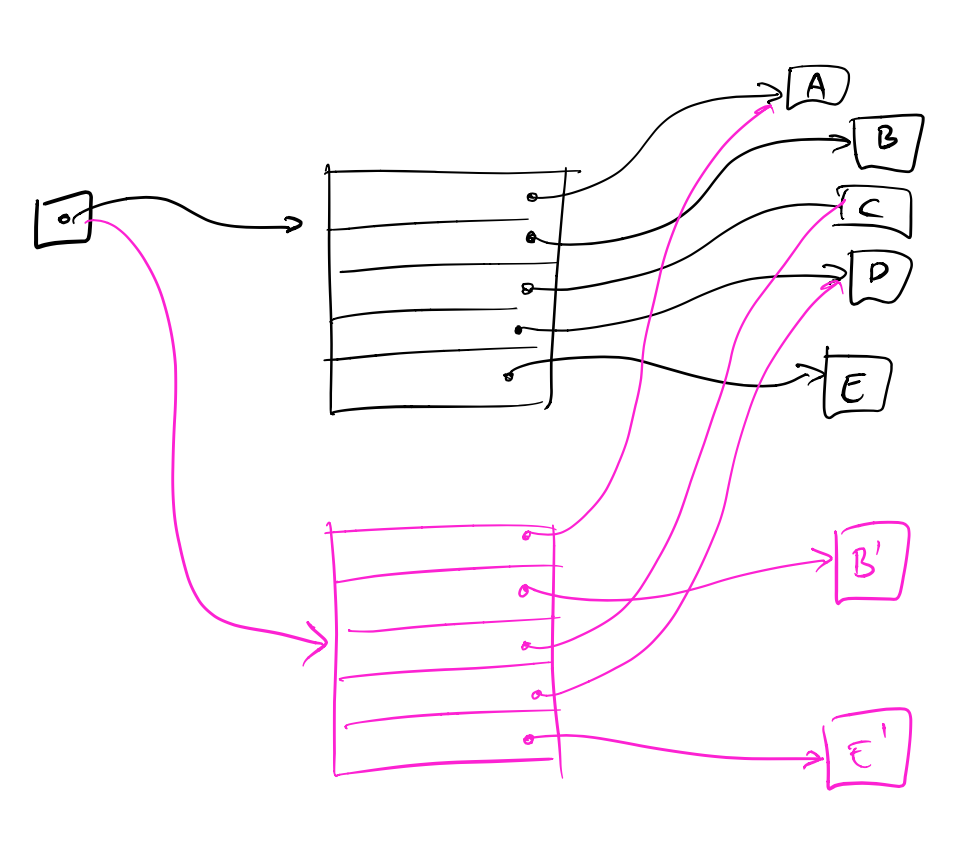
Replacing the lookup table.
A reader will either have a pointer to the old or the new lookup table. Thus, the reader will either see (A, B, C, D, E) or (A, B’, C, D, E’) and both sets of objects are consistent.
We can combine this with the CAS technique too, and only replace the root pointer if it hasn’t changed. This allows us to make a change to an arbitrary number of objects as a single transaction that will either succeed or fail. Pretty similar to the transaction model you would get in a relational database.
Another interesting thing: If you know how git works on the inside with tree objects and blobs, you can see that this approach is actually very similar to git’s.
The drawback of this approach is that every transaction requires changing the root pointer. (It requires copying the lookup table too, but we can reduce the cost of that by having hierarchical tables, similar to git.) Thus, there will be a lot of contention for the root pointer and that contention will cause a lot of commits to fail. (There is probably some way of being a bit smarter about this to let some of the commits that touch disjoint set of objects through, but I haven’t dug deeper into this.)
In the end, we have to consider what kind of consistency model works for us and if we are willing to pay for it. After all, if performance is not a big deal, we can just use a regular database.
In our case, we are not dealing with critical financial data. It’s not a big deal if a reader sees some object from one write and some objects from another write. So we don’t need the full transaction model.
Doing the CAS on commit() is not costly, but having to deal with commits failing can be costly. Every piece of code that writes data to the Truth would need a little loop that attempted to rewrite the data on a failed commit. Preventing simultaneous writes to the same object is probably better dealt with at a higher level anyway. For example, if both an animation system and a physics system wants to write object positions, the right way to solve it isn’t with locks on the position data. Instead, we need to figure out on a higher level how animation and physics work together to control an object’s position.
For this reason we’ve decided to keep the simple version of commit() . You can only commit one object at a time and the last write wins. We might add a separate try_commit() too, that does CAS and can fail, for code that needs that kind of synchronization.
The devil in the details
So far, this seems pretty good. We have a (weak) consistency model. We have a mechanism for implementing it that doesn’t require any locks or waits in the reader. In fact, we don’t have any locks or waits in the writer either, just an atomic write operation. Seems almost too good to be true.
In fact, it is too good to be true. We sketched out the implementation, but we conveniently skipped over all the details. That doesn’t matter that much in single-threaded code, but in multi-threaded code, the details matter. So let’s dig in!
Garbage collection
When an object is replaced or deleted by a commit(), we can’t immediately delete the old copy, since some readers might still be reading it. So when can we delete it?
One option would be to reference count the readers. When the number of readers goes to zero, we can safely delete the object. This requires an end_read() operation, similar to the commit(), that decreases the reference count when we are done reading the object.
const object_o *reader = the_truth->read(tt, id);
float x = the_truth->get_float(tt, reader, POSITION_X_PROPERTY);
float y = the_truth->get_float(tt, reader, POSITION_Y_PROPERTY);
float z = the_truth->get_float(tt, reader, POSITION_Z_PROPERTY);
the_truth->end_read(tt, reader);
Having to write end_read() is inconvenient for the user of the API, but this solution has more serious problems. Consider how read() would be implemented. Something like:
const object_o *read(const the_truth *tt, uint64_t id)
{
const object_o *obj = tt->object_table[id];
++obj->refcount;
return obj;
}
First of all, we can’t use ++obj->refcount because ++ is not an atomic operation. On the CPU it is translated to:
obj->refcount = obj->refcount + 1;
And with two threads running this simultaneously they could both read a refcount of 7, increase it by 1 and then both write 8, even though the result really should have been 9.
No big sweat, there is actually a function in the C11 atomics library that does this atomically:
atomic_fetch_add(&obj->refcount, 1);
But this still doesn’t work, because we have two separate steps for looking up the object and increasing its reference count. Another thread could enter between those two steps, see the refcount at 0 and free the object. Boom, we crash.
To make this work we have to make sure that the lookup of the pointer and the bump of the refcount happen as a single atomic operation. But I don’t know how to do that without introducing some kind of lock, which we don’t want in our reader code.
See, devil in the details.
So what can we do instead?
Well readers typically don’t need to hold on to objects for very long. They just read a few values and then they’re done. So if we just wait a little while before deleting objects, we should be fine.
Of course we need to define more precisely what “wait a little while” means in order to make this work. Luckily, the kind of applications we are interested in have a cyclic behavior. They regularly return to a “root state”. For a game, or other real time application, that would be the main update or frame tick loop. Similarly, for a desktop application, it’s when we return to the main message processing loop.
When we get back to the root state, all read() operations should have finished which means we can finally “garbage collect” all the objects that we wanted to delete, but wasn’t sure if we could. This gives us safe deletion without locks or explicit end_read() operations. (We have an implicit end_read() operation at the end of the frame.)
Of course, this can cause trouble if we have long-running background threads that also need to access the system. My current take on this is that these threads need to call special functions lock_read(), unlock_read() to read objects. These functions either increase an object reference counter or register hazard pointers that the GC checks. Using locks, we can ensure that the reference counting is atomic with respect to the GC. Since this is a special case of reading data we’re ok with the performance penalty of taking a lock.
Just to dive even further into details, what do we mean by “queueing an object for garbage collection”? We need to put the object’s pointer into a list or queue or something. And this will require some form of synchronization — either a lock or a lockfree wait loop. This is ok though, because this only happens during write operations (that’s the only time when we commit and create garbage) and we’re ok with taking locks during writes. But it shows that the simple picture we had initially were no locks or waits would be necessary, even in the writers, was false. We should also be wary, because if we only have a single lock for the garbage queue, every commit operation will need to obtain this lock and we will see a lot of contention.
The lookup table
Another thing we glossed over was how the lookup table should work. We assumed it was a big table of pointers indexed by some bits of the object ID (we use the rest of the bits to store things like object type). But how would we actually implement that table? vector<object_o *>? No, that doesn’t work, because the vector will regularly reallocate its backing memory and copy all the data to a new location. If a reader was accessing the vector in the middle of such an operation it could read trash data.
A raw array would work: object_o *objects[MAX_OBJECTS]. The writers can atomically write new pointers into the array without disrupting the readers. But now we have to define MAX_OBJECTS which is annoying. Set it too low, and we run out of objects. Set it too high, and we’re wasting memory. For a one-off application like a game, that works pretty well, we can just find a value that is right for our game — the highest value we’ve ever seen plus a comfortable safety margin — we don’t need any dynamic allocation and there will be no memory wasted. But for a more general engine it’s not a nice solution.
But, we can use the idea of hierarchies to our advantage again, and make something like this:
struct object_block_t {
object_o *objects[1024];
};
struct object_super_block_t {
object_block_t *blocks[1024];
};
struct the_truth {
object_super_block_t *super_blocks[1024];
...
};
The Truth holds a fixed array of 1024 “super blocks”. Each “super block”, when it’s allocated, holds 1024 block pointers, and each block, when it’s allocated, holds 1024 object pointers. A writer can atomically replace null pointers in these arrays with actually allocated blocks and super blocks without disturbing the readers. We never waste more than 24 K of memory (for one allocated block of each type) and can support up to one billion objects. To look up the pointer for an object we would do:
struct id_t {
unsigned int super_block : 10;
unsigned int block : 10;
unsigned int index : 10;
...
};
object_o *o = the_truth.super_blocks[id.super_block][id.block][id.index];
Of course you could tweak the number of hierarchy levels and the number of objects in each level to get a different balance of wasted memory, maximum number of objects and number of indirections needed for lookup.
Another approach to the same problem would be to use a vector<object_o *> like approach, but implement garbage collection. I.e. you would keep an array of object pointers, and when the array got full you would reallocate it and copy the data (just as the standard vector implementation does). But you wouldn’t free the old data array. You would put it on the queue to be garbage collected, just as we do with old objects. Thus, readers using the old array would be fine.
This approach works too, but it has the drawback that as the array gets large, the copying operation will become more and more expensive. You could ameliorate that by combining it with the hierarchical approach. I.e. let the array contain block pointers.
Allocating memory and IDs
Another thing we’ve glossed over is memory and ID allocation. When we allocate a new object we need to make an ID for it. This ID can’t collide with IDs created by other threads or we’ll be in trouble. Similarly, if we need to allocate a new block or a new super block we need to make sure that no other thread is allocating that memory at the same time.
We can achieve this by putting locks around these operations. Again, this is ok, because these operations only happen when we are writing objects. But we should be a bit careful, because if multiple threads are writing with high frequency, there could be high contention for these locks. For example, a global ID lock would have to be obtained by every thread that needs to create new objects.
A way of avoiding this is to allocate specific blocks for specific threads. For example, we could say that the thread with index t can only use super blocks where i % N == t. Here i is the index of the super block and N the total number of threads. Since the threads use different super blocks, they never compete for IDs or block allocation. We trade more internal fragmentation in the blocks for avoiding contention.
This approach works well when the number of threads is low. Our system tries not to oversubscribe the number of threads and use one thread/core. So it could work. But core numbers are always going up, never going down, so it’s a bad future to bet on.
We should also note that even if we fix these issues, the allocation of memory itself goes through an allocator that enforces serialization. So unless we switch to a multi-threaded allocator we may just replace contention for our data structures with contention for the memory allocator.
For now I think we will start with a simple locking scheme and investigate more advanced solutions (per-thread ID and memory pools) as needed.
Synchronizing mechanisms
Before wrapping up, I wanted to say something about different methods for synchronizing and their advantages and disadvantages as I see them. The mechanisms you most typically run into are:
- Windows critical sections (lightweight mutexes on other platform — a spinlock with fallback to an OS event)
- Custom spinlock based on CAS
- Lockfree solution
A common misunderstanding is that the main difference between these three solutions is performance and that the advantage of lockfree algorithms is that they are faster. But if you look at the cycle counts in the case of no contention they are all pretty similar. In fact, they are all pretty fast.
Regarding contention, since we are interested in high-performance code, I will assume that all the locks are fine-grained and that they are only held to perform a couple of simple operations. If that is not the case, you should optimize your code by making the locks more fine grained, not by changing the locking mechanism.
In this case, the mechanisms’ behaviors under contention is also similar. All of them will spin a few cycles, until the other thread is done with its manipulation, and then proceed. In the case of lockfree — it is not really a lock of course, but one of the threads’ CAS will fail, causing it to spin in a similar manner.
In my mind, the main difference is what happens if a context switch happens and a thread is swapped out while holding a lock. This is a big deal, because it may be milliseconds until the OS swaps the thread back in again. And milliseconds are an eon in CPU time.
This is what happens in each case:
With critical sections, our thread will go to sleep waiting for the swapped out thread. This is good, because it frees our core for use by the swapped out thread. Also, the OS is made aware that we are waiting for a thread, which it can use to bump the priority of that thread. I.e., we still have to wait for the swapped out thread, but most likely that thread will be swapped in faster.
With a spinlock, our CPU will churn waiting for the busy thread. This consumes power and creates heat. But worse, there is no way for the OS to know that we are waiting, so our core doesn’t get freed and the priority of the swapped out thread doesn’t get raised. I.e., we have to wait for the swapped out thread and the wait will likely be longer.
With a lockfree algorithm, we don’t have to wait for the swapped out thread. Our CAS will succeed since the other thread is sleeping and can’t modify the address we are looking at. This is in fact the definition of lockfree. Lockfree doesn’t mean we never stall — if there is contention we may be stuck in a loop trying to set a value, potentially for a long time. But it means one thread can’t block the progress of all other threads — someone will progress.
So in this case the lockfree approach is clearly better. But one thing we must ask ourselves is: Does it really matter?
First, how likely is the situation to occur? If we don’t oversubscribe our threads and locks are only held for short times, maybe it doesn’t happen that often? I have no good numbers for this and it would require a thorough investigation.
Second, how bad is it? A common multithreaded programming model is to create a number of jobs, go wide to execute them, and then go single-threaded again to collect the results. In this case, the lockfree approach doesn’t buy us that much, because even though the other threads don’t have to wait for the stalled one and can continue to process jobs, in the end we can’t proceed until the stalled thread has finished. (You can try to design around that, make the other threads do the job of the stalled thread so the application can move on. The tricky part of that, the very very tricky part of that, is that when the stalled thread starts to run again and the application has moved on to some other unknown state, all the things that that thread tries to touch are likely to break — memory has been freed, etc. In fact, I don’t know any general job system that successfully does this.)
So in the end, since we have to wait for the stalled thread to finish anyway, we still get the millisecond delay, even with the lockfree solution. (It might be fewer milliseconds, though.) It is only in very specific situations that the lockfree approach will actually prevent the stall.
In addition, lockfree algorithms are notoriously hard to program. And to make something lockfree, all of it must be lockfree. If the memory allocator still locks, it doesn’t matter if the rest of the system is lockfree.
In summary:
- Lockfree algorithms are really really hard.
- To get the lockfree behavior, every part of the system must be lockfree.
- And usually you still end up stalling, just at a higher level.
For these reasons I recommend avoiding lockfree solutions except in a few very special cases. This means our best contender is good old Windows critical sections.
One situation where we can run into problems with critical sections is if we want to create a really fine-grained locking system. Say that we wanted to have an individual lock for each object, so we would need millions of locks. This has two problems. First of all, a critical section is 40 bytes, so we would be using a lot of memory. Second, a critical section will lazily allocate an OS event if there is contention. This event is never freed. So with a lot of critical sections our OS event count would slowly increase as those critical sections randomly run into contention. This would consume even more memory (an OS event is 128 bytes I think) and put us at risk for running out of system handles. Interestingly — if we’re close to running out of handles, the OS will actually switch to a different algorithm that doesn’t allocate individual events for critical sections. As far as I understand, in recent versions of Windows, this algorithm has similar performance and the allocation of individual events is mostly done for backwards compatibility. But I don’t know all the details of this. I’m also not sure how things work in the Linux world.
If you need a cheaper way of creating millions of locks, some of the options are:
-
Use a spin lock and accept the risk of churn and swap-out.
-
Have a fixed sized pool of critical sections and access them with a hash of the object ID. You could keep say 8192 critical sections in an array, hash the object ID to the range 0—8191 and use the corresponding critical section as a lock. As long as you have a lot more critical sections than threads, the risk of artificial contention (two IDs hashing to the same value) is low.
-
Use a synchronization mechanism that doesn’t require a lot of memory or OS objects. Windows actually has several of these, although they are not as well known as critical sections. Slim Reader/Writer Locks are only the size of a pointer and use no OS objects. In fact, you should probably replace all your uses of critical sections with exclusive SRW locks. There is also WaitOnAddress which allows you to wait on any memory location. In the Linux world a futex can be used for similar functionality.
Wrap-Up
Multi-threading an advanced data structure gets real gnarly real fast. Even though I tried to go into implementation details in this article there’s still a lot I left out — how to build the garbage queues, for instance. And I haven’t said anything about the more advanced features of The Truth — prototypes, references, sub-objects and change notifications. They all need multi-threaded implementations too. But this article is getting too long already. If there is interest, maybe I’ll revisit those topics in a future post.