Prototypes in The Machinery
Most game engines have some way of creating reusable entities — i.e., template entities that can be placed multiple times in different levels. Sometimes, these templates are called prefabs.
An important part of any template or prefab system is that if you make changes to a prefab, those changes are automatically reflected to all placed instances of that prefab. Prefab systems let you start building levels with placeholder entities and then later update the template with the real graphics.
Advanced prefab systems can support mixing and matching templates in various ways. For example, maybe you can create an “advanced enemy” template which is identical to the “basic enemy” template, except it is tinted red and has 50 % more hitpoints. Changes made to the basic enemy would automatically carry over to the advanced enemy and its instances. For example, if you changed the hit points of the basic enemy to 100, all the instances of the advanced enemy would get 150 hitpoints.
Or, you might be able to create a house template with windows and doors and then, in one placed house instance, swap the default wooden door for a brass one. If you later changed the windows of the template, this instance would get the new windows but keep its brass door.
In The Machinery, we call our templates prototypes and in this blog post, I’ll describe how our prototype system works and try to explain why we made the choices we did.
The trouble with templates
Designing a template system can be difficult because it requires you to manage your data at a higher level of abstraction. The user needs a way to edit, not just the data itself, but also the rules for how that data relates to other data.
There are no fixed rules for how this should work. A template system can be anything you can dream up. The Slide Master concept in Powerpoint/Keynote and the reusable page layouts and text styles in InDesign are simple template systems, while the class or prototype hierarchy in object-oriented languages can be seen as an advanced template system.
When you design a template system for a game engine, you have a bit of a dilemma.
On the one hand, you want the template system to be as powerful as possible. “Powerful”, in this context, means that the users can express complicated data relationships and use that to automate as much of the workflow as possible.
On the other hand, you want a simple and easy-to-use UI.
There is an inherent conflict between these two goals. The more powerful the abstractions are, the harder it is to create a UI for them (other than a basic text editor).
Let’s see how this plays out in a few examples, and then we’ll look at the path we took in The Machinery.
1. Source code
The most powerful way of expressing data relationships is with code I.e. the “configuration file” is just a program, written in some general-purpose programming language, that you “run” in order to generate the data for the project.
Since the “configuration file” in this case is a program, written in a Turing-complete programming language, it can automate anything that is possible to automate.
Creating the “advanced enemy” template could look something like this (in pseudocode):
advanced_enemy = basic_enemy
advanced_enemy.hitpoints *= 1.5
advanced_enemy.meshes.torso.tint = rgb(255,0,0)
But the automation could go much further than this. We could write a function that placed lamp posts along a road. We could procedurally generate stairs based on the step width, step height, etc. Since it’s general purpose code, anything is possible.
As you can see, this approach is super powerful. The drawback is that since the data is code, only programmers will be able to edit it. And even for programmers, writing code is not the most natural way to edit visual things, such as meshes and levels.
For some applications, this can still make sense. For example, the Premake build system (which we use to build The Machinery) uses regular Lua programs as its configuration files. In this case, the lack of a UI is not a big deal, since only programmers are interested in build systems (in fact, even programmers are not that fond of them).
A way of making the data-is-code approach accessible to more users would be to use a visual scripting language, instead of a textual one, but this comes with its own set of compromises. To programmers, visual scripting tends to be more tedious than just writing code. To non-programmers, visual scripting is more complicated and less visual than a regular GUI. While it makes sense for advanced tasks, such as gameplay scripting or rendering, it’s typically not something they would want to use for the majority of their data, such as building levels.
Another drawback of this approach is that if your data is a program written in a general-purpose, Turing-complete language, you can run into things like the halting problem. I.e., you can’t reason about the data in any way without first running the code that generates it. This can be problematic if it takes long for the program to run. Or, if the program has a bug and never completes — now you have no data at all, just an empty scene, until the error is fixed.
But again, there are ways of making this approach work. For example, you could argue that Houdini is essentially a visual scripting language that you “run” in order to generate your scenes, just more high-level than your typical visual scripting language. Note that the immediate visual feedback that Houdini gives when you edit the graph is key to making it usable.
2. Markup language
The next step in expressive power below code is a “markup language”, such as CSS or HTML. Markup languages are parsed, not run, and can express complicated relationships, without being Turing-complete.
A markup language implementation of the example above might look something like this:
advanced_enemy : basic_enemy {
.hitpoints = calc(base.hitpoints * 1.5)
.meshes.torso.tint = (255, 0, 0)
}
I’m making up both the syntax and the object model here.
Markup languages come in many shapes with varying degrees of expressive power. For example, in the
code above, I’m assuming that (similar to CSS) the language can calculate expressions such as
base.hitpoints * 1.5. In a more basic language, this might not be possible, and we would instead
have to set the hitpoints as a hard number:
advanced_enemy : basic_enemy {
.hitpoints = 45,
.meshes.torso.tint = (255, 0, 0),
}
In this case, the hitpoints wouldn’t automatically scale if we change the hitpoints of the
basic_enemy — they would remain at 45 until we explicitly changed them to something else.
Markup languages have the advantage of being more limited and contained than full programming languages. This makes it easier to create some kind of UI/editor for them and since we don’t “run” the data, we don’t have to worry about “bugs” or infinite loops.
But beware, markup languages are often subject to feature creep — as time goes on, the developers add more and more useful “features” to the language until it approaches the complexity of a general-purpose programming language — just a shitty and haphazardly designed one. I’m looking at you CMAKE!
This is the code/data cycle that I’ve tweeted about before.
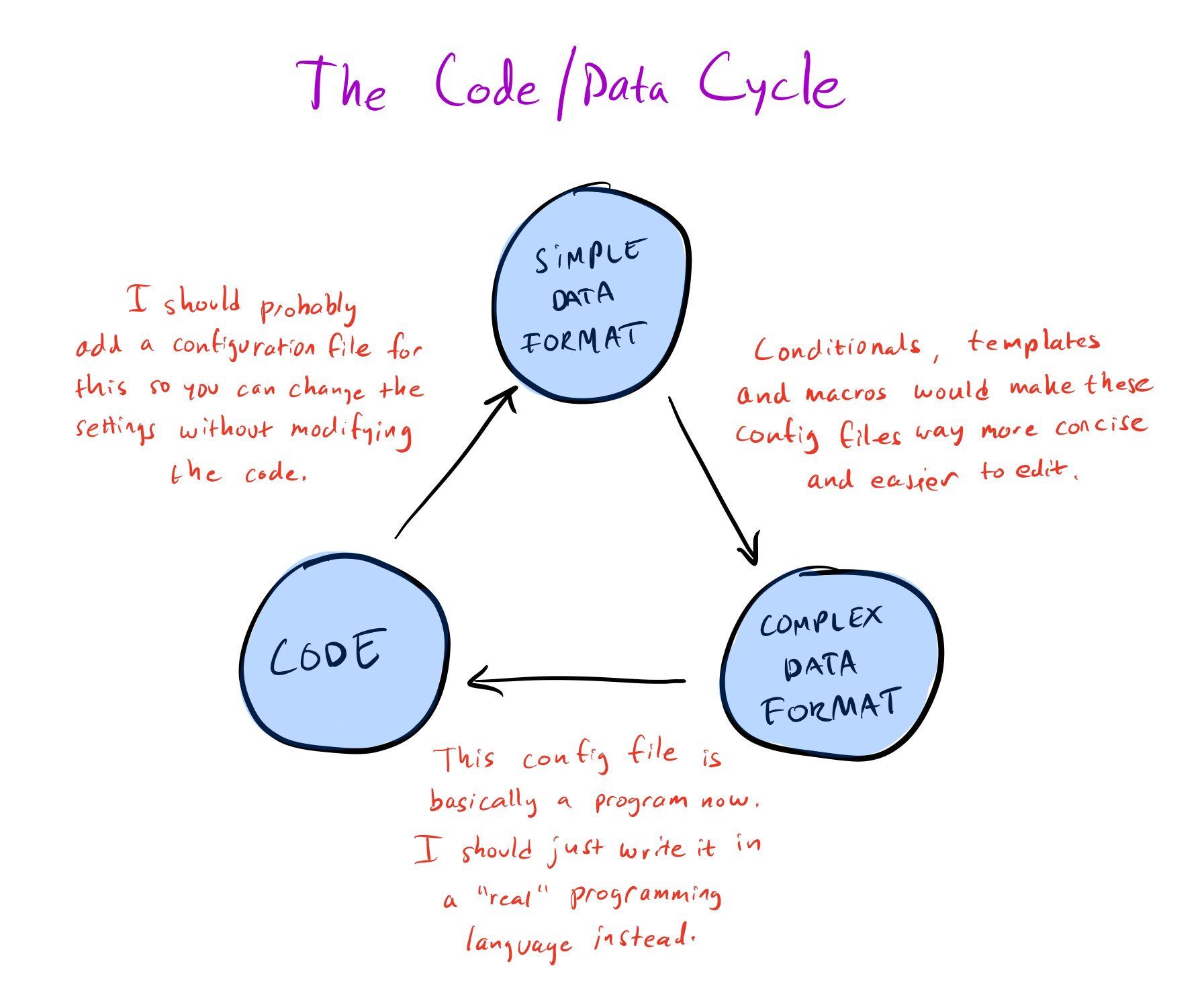
The Code/Data Cycle.
What kind of UI can we create for our markup language? Again it depends on the expressiveness. The more expressive the language is, the harder it is to create a sensible UI. Here’s an attempt:
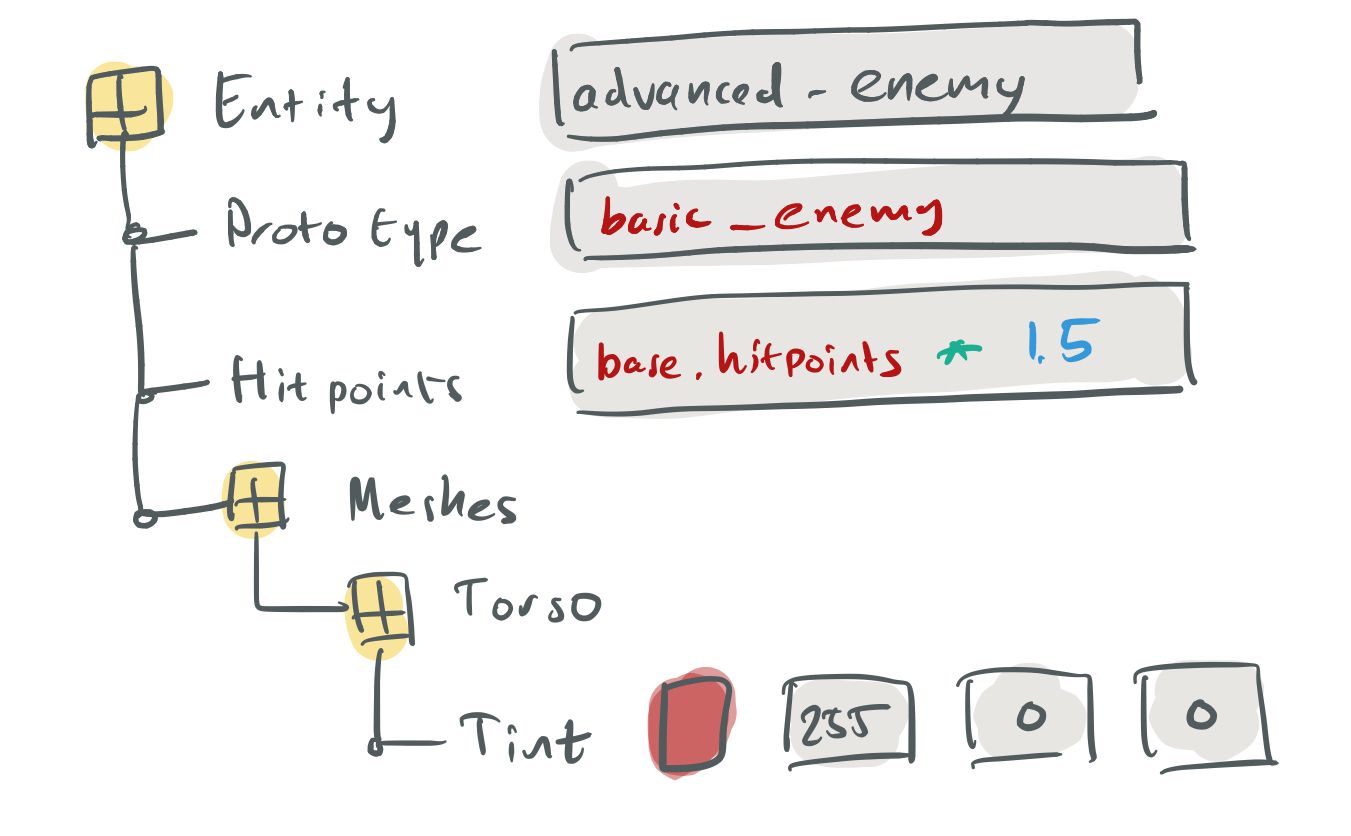
Possible UI for the declarative language.
Yay, we’ve made a UI… but actually, it is really just a glorified text editor. To use this UI, the
user still has to know that he needs to enter the magic incantation base.hitpoints * 1.5 in the
textbox. Not very user friendly and doesn’t seem like a nice way to work, even if autocomplete,
syntax highlighting, and drag-and-drop could lessen the burden somewhat.
If you want a markup language to work with a UI, I think you have to carefully design it with that in mind. Otherwise, the text editor will end up being the default (as happened with both HTML and CSS).
An example of the markup language approach is the Universal Scene Descriptor format (USD). USD allows resources to be reused and remixed in lots of powerful ways. But it is hard to imagine what a UI editor for it would look like — it’s predominantly a format geared for text-editors. Nothing inherently wrong with that — but it’s not what we wanted for The Machinery.
3. “User-friendly” UI
Finally, let us imagine what a user-friendly UI might look like:
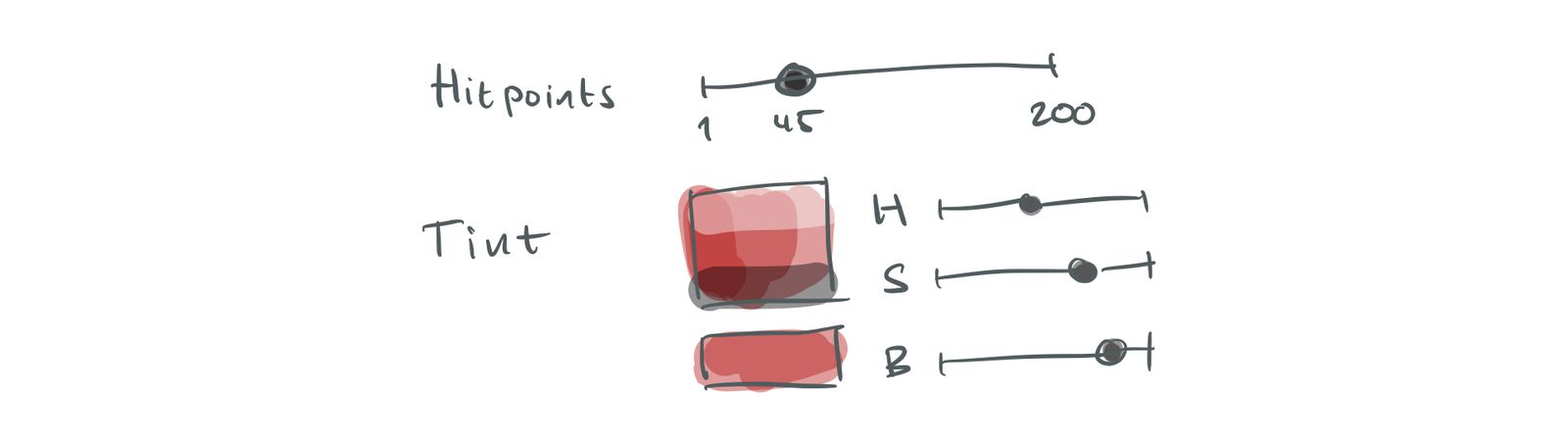
User-friendly UI.
There are no magic text incantations. The hitpoints are set with a regular slider. The tint color is set with a regular color picker (sorry for my limited ability to draw one).
We have the nice UI that we want, but no way of expressing something like “50 % more hitpoints”. Also, the relationship between the advanced enemy and the basic enemy is unclear. We can’t easily see how the one affects the other.
This approach doesn’t look like it gives us enough expressive power.
In my opinion, making templates work in a graphical UI, and not just a text editor, depends on finding a good “cut”: A more limited set of features — less than what code or a markup language could do, but still powerful enough to handle most of the users’ needs — that we can put together a sensible UI for.
Prototypes in The Machinery
We had three main goals with the prototype system in The Machinery:
-
The Prototype System should be a general feature of our Data Model. I.e., it should work for all the data managed in the application, not just entities.
-
When working with Prototypes and Instances, you should generally be using the same UI as when working with regular objects. I.e., you should not have to drop into a text editor, a visual scripting language, or any other complicated thing.
-
It should be as feature-rich as possible without compromising on the other goals.
Since our template system works on any object, we don’t use the word Prefab, instead, we call our templates Prototypes and the places where they are used Instances.
The Machinery Data Model
Our Data Model is based on Objects with Properties. Objects have property Keys that can be assigned Values. Each object has a Type and the type of the object determines which properties it has:

Object types and objects.
In addition to basic scalar property types (numbers, strings, booleans, binary blobs) we also support Subobjects, References, and Sets.
A Subobject is an object that is an object that is owned by another object. For example, the Transform Component object type has a Position subobject of type Vector3. The Position subobject has three float properties (X, Y, Z).
A Reference is a link to an object that is not owned by us. As an example, the Animation State Machine stores references to Animation Clips to play. These are references, not subobjects, because we might want to use the same animation clip in different places. An object can only have one owner, but there can be multiple references to the object.
In The Machinery, objects are referenced by their unique IDs, so a reference always points to a specific object. (Another option is to reference objects by name — this allows a reference to point to different objects depending on what “namespace” we are currently in. This looser binding has both advantages and disadvantages — more about that later.)
Sets allow us to build hierarchies of objects. For example, an Entity in The Machinery has a set of Child Entities, as well as a set of Components.
Note that we’ve made the conscious decision to only support unordered collection types (sets). The reason is that operations on sets (Add/Remove) are easy to merge whereas array operations (Reorder) are more complicated. If you want a user sorted set, you have to add an explicit Sort Order property.
At the top of the object hierarchy sits the Asset Root. This object represents the “file system” of the project. The Asset Root has a set of Asset subobjects — the individual resources that make up the project.
Implementation of the Prototype System
Prototypes are implemented with a Prototype reference and an Override bitmask. Any object in our data model can specify another object as its Prototype. The object will inherit all the properties of the Prototype unless a property is specifically overridden. The overridden bitmask keeps track of which properties have been overridden.
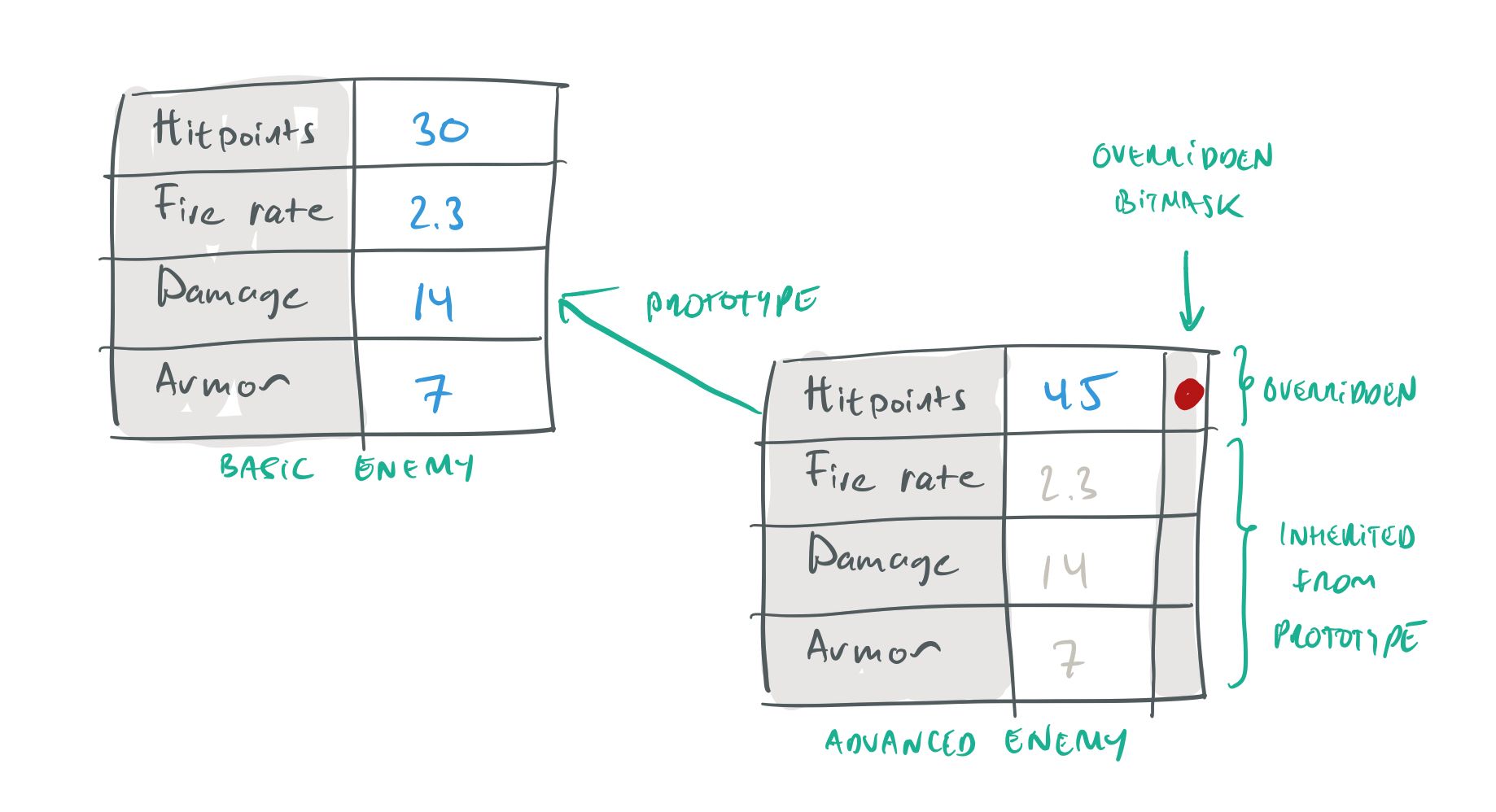
Prototypes, instances and override bitmasks.
Sets are treated a bit differently when it comes to overrides. Instead of overriding the entire set, the instance specifies a set of objects to add to and remove from the parent set. The set of the instance is the prototype set with those modifications applied.
When it comes to subobjects, the instance has a third option. Instead of Adding or Removing the subobject, the instance can choose to Instantiate the parent’s subobject. What this means is that the instance creates its own subobject that uses the parent’s subobject as its prototype. By doing this, the Instance can override, not only the properties of the Prototype, but also the properties of any of its subobjects, or its subobjects’ subobjects.
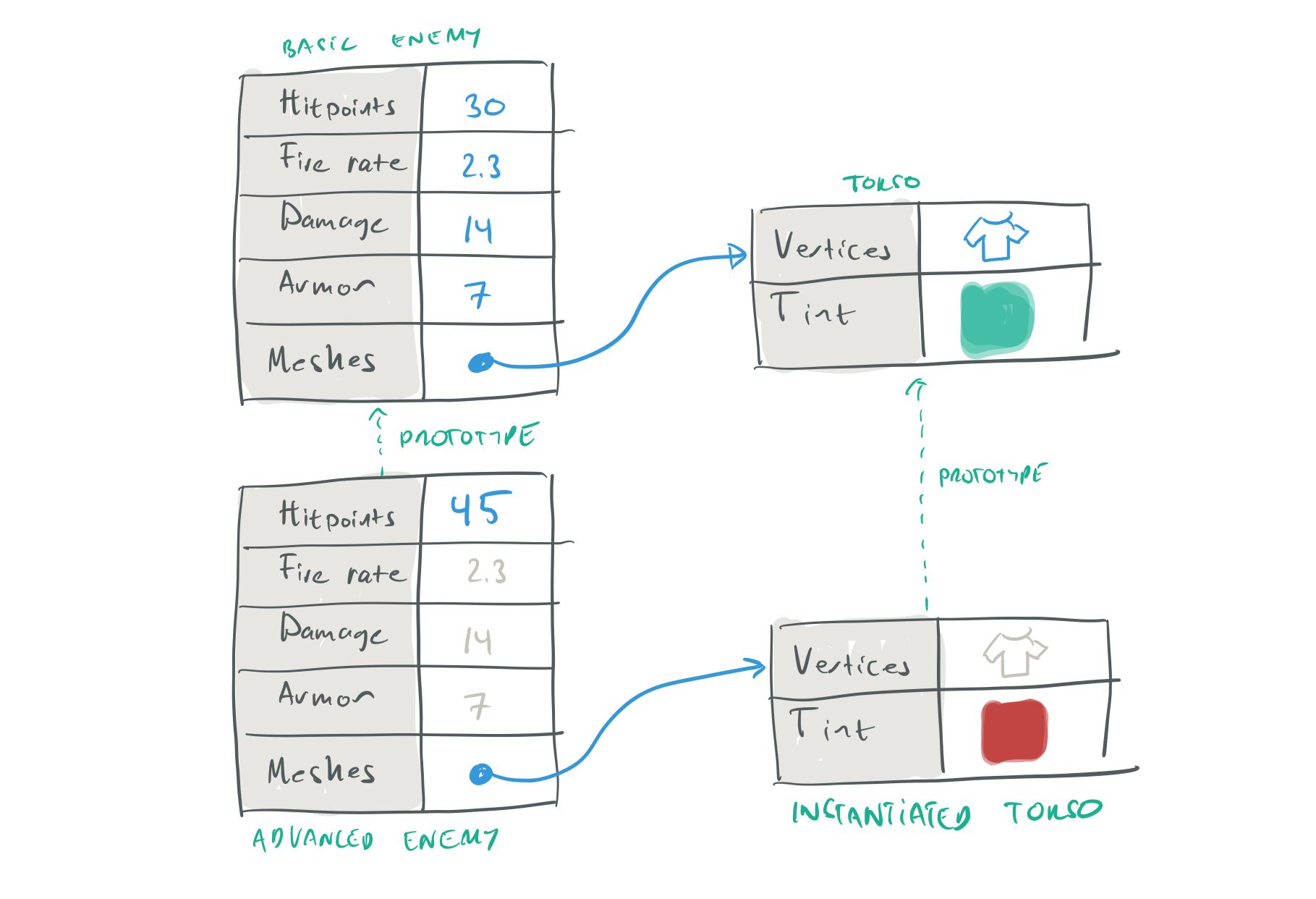
Instantiating a subobject to override its properties.
Prototypes can be chained. A prototype may have its own prototype object, and that object may in turn have another prototype. Properties are inherited through the entire chain of prototypes.
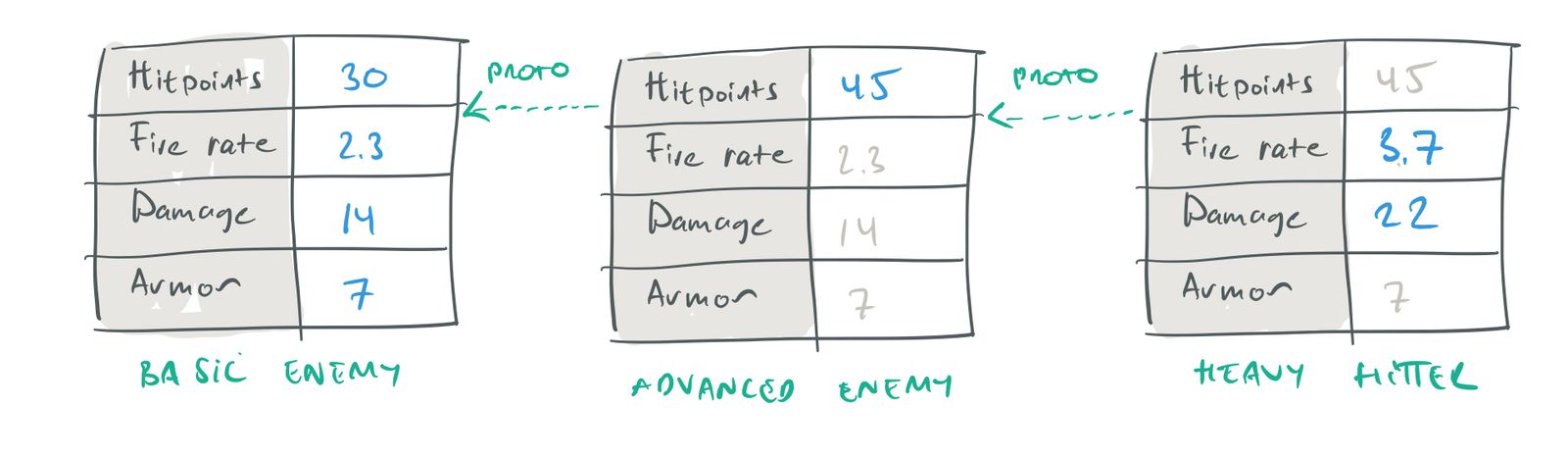
Chaining prototypes.
Note that prototypes are not “special objects” in any way. Any object can act as a prototype to any other object of the same type. Because of this, we don’t really make a distinction between “Entities” and “Prefabs” in The Machinery. Any entity can be used as a prefab.
Now that we know how prototypes are implemented, let’s see how they work in the UI.
Property editor
Our main UI for editing objects is the Property Editor. The Property Editor shows the properties of an object and lets the user edit them:
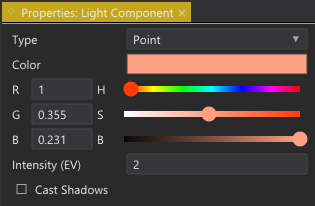
Property Editor.
The UI for the property editor is automatically generated, based on the properties of the Object Type. But note that it can still be completely customized, by providing callbacks for specific types or properties. For example, in the screenshot above, the color editor uses a custom UI.
This is what the UI for an object with a prototype looks like:
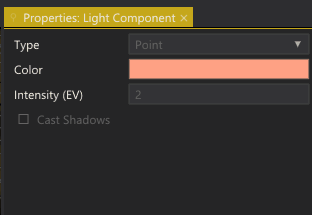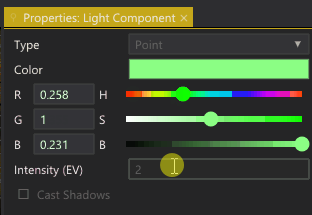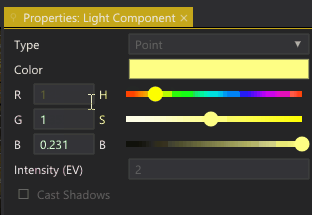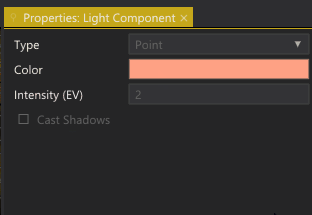
Editing the properties of an instance.
Properties that are inherited from the prototype are grayed out. If we edit those properties, they become white — indicating that they have been overridden in the instance. Right-clicking an overridden value brings up a context menu with two options:
-
Reset: Remove the overridden value and reset the property to the inherited value from the prototype.
-
Propagate to Prototype: Make the value we have set for this instance the default value of the prototype. I.e., all instances of the prototype will get this value (unless they have overridden the property).
Since the Property Editor UI is auto-generated, any object type in the application, even user-created types, automatically get the prototype workflow.
If you make a custom UI that draws its own control instead of using one of our standard controls, you have to do a little bit more work. You have to check if the inherited data is overridden or not and if it is, draw a grayed-out version of your control.
Note though, that even if you forget, or don’t bother to do this, your control will still work, you just won’t get any visual indication of whether the data is inherited or overridden.
Tree view
For hierarchical object structures, things become a little bit more complicated, because, in addition to overridden properties, we also have to handle Added, Removed, and Instantiated subobjects.
Hierarchical objects are typically edited in our Tree View, for example here is the Tree View for an entity:
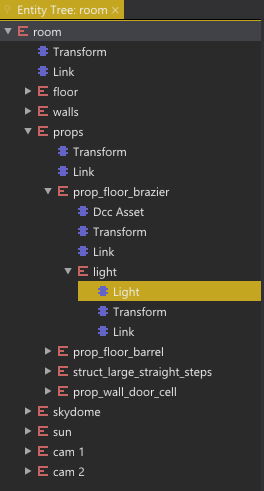
Tree View.
Just as with the Property View, the Tree View is a generic editor that can display any object as a tree, so once we have a good prototype workflow, it will work for any object.
(Side note: for historical reasons, we actually have two separate tree views, the Entity Tree View and the Generic Tree View — we might merge them at some point.)
We use colors to indicate the “prototype relationship” of an object in the Tree View:
| Color | Meaning |
|---|---|
| White | A locally added object. |
| Yellow | A locally added prototype instance. |
| Gray | A subobject inherited from the prototype. |
| Blue | A subobject that has been instantiated for local modifications. |
| Red | A subobject that has been removed from this instance. |
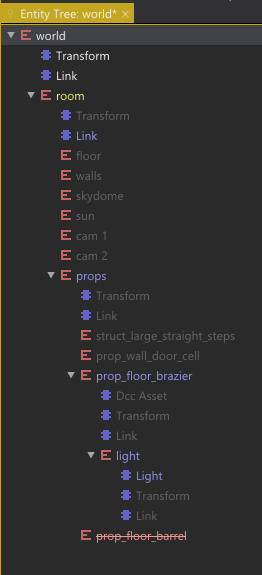
Tree View of an instanced prototype.
Again, a context menu can be used to perform operations on the inherited subobjects:
- Overriding (instantiating) a subobject to make local modifications.
- Removing an override (instantiation)
- Propagating changes from a subobject back to the prototype.
- Removing a subobject from this particular instance
One thing to note here is that the inherited subobjects (the grayed out ones) cannot be selected or expanded in the tree. To select one of those objects and edit its properties you have to first override/instantiate it.
The reason for this is somewhat complicated, but it is important to understand: Unless you have overridden an inherited subobject, it doesn’t have any separate identity in our Data Model. The only thing that exists is the subobject of the prototype (which our instance has inherited). But we don’t want to edit that object, because that would change the prototype. We just want to change the value of this instance.
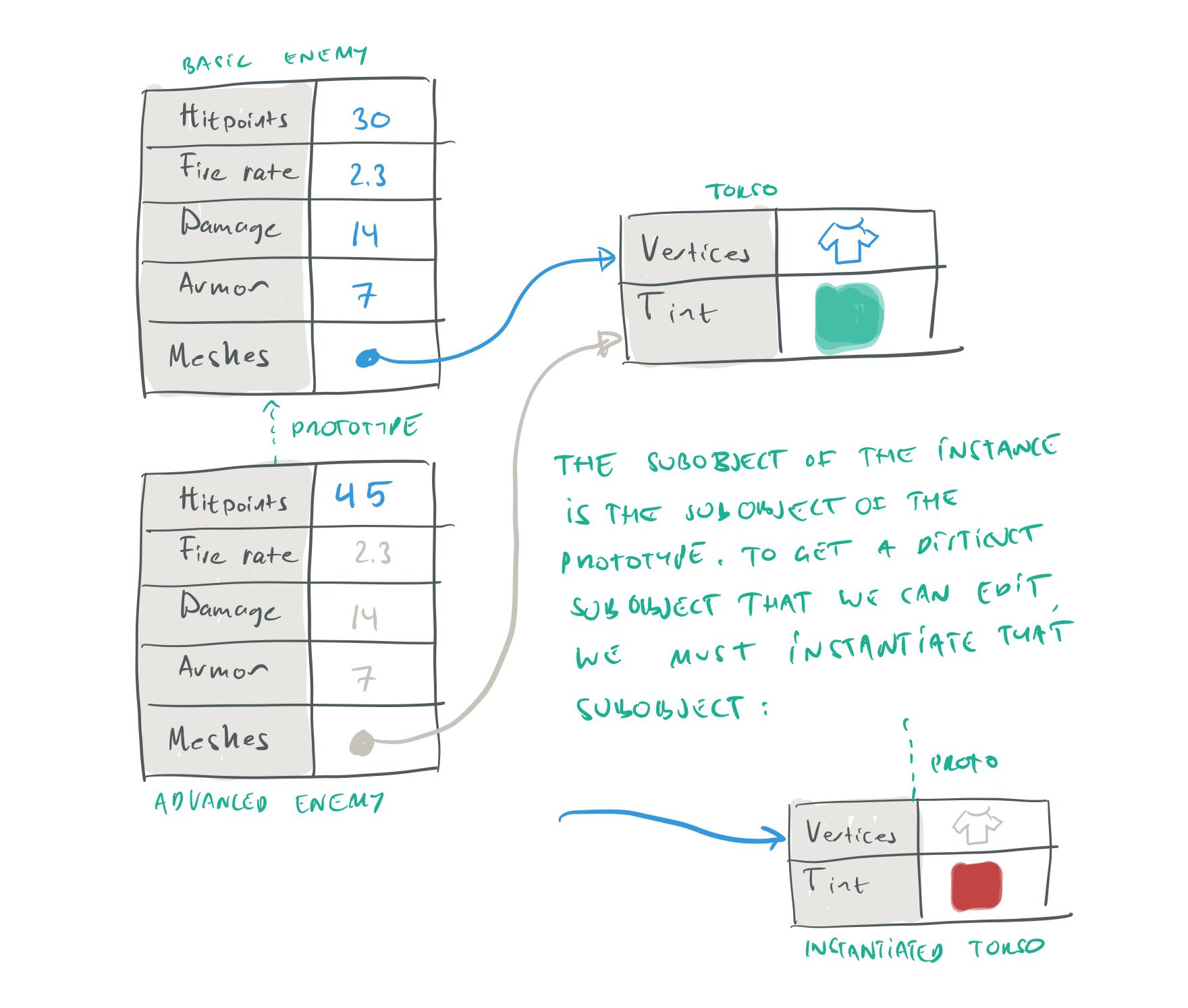
To modify the properties of an instance’s subobject, we must instantiate that subobject for that specific instance.
Since the subobject of the instance doesn’t exist until it has been Instantiated, there is nothing in the Data Model that we can select and edit. Thus, we must force the user to instantiate the subobject before editing it.
A consequence of this is that if you want to edit the property of some subobject deep in an instance’s hierarchy, you must first “drill down” and instantiate all the subobjects above it in the hierarchy. This “drilling down” can be a bit tedious as shown in this gif:
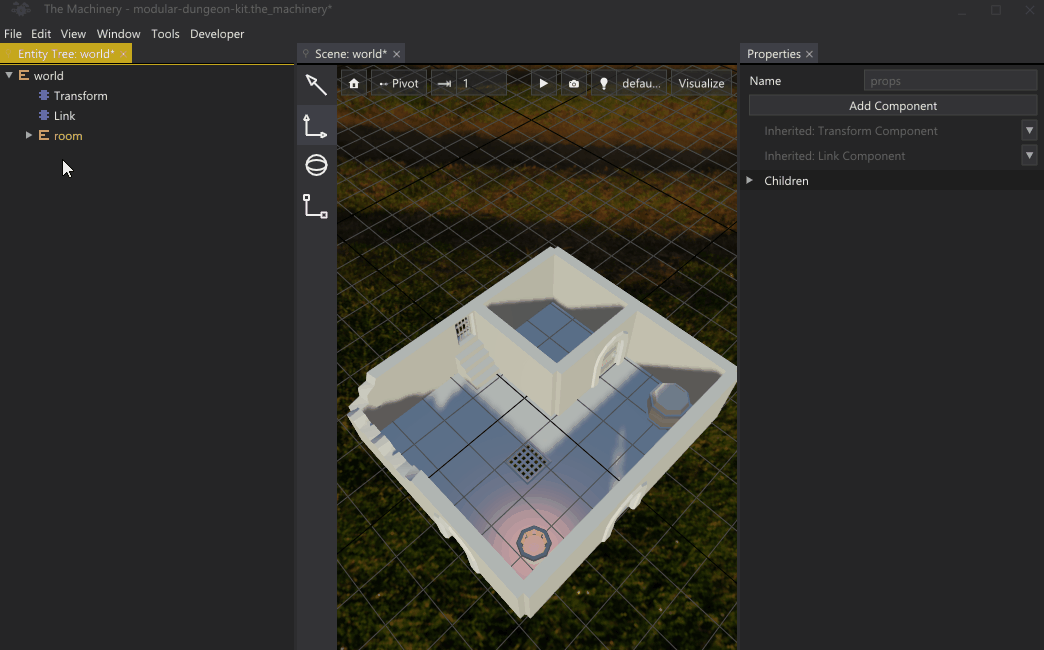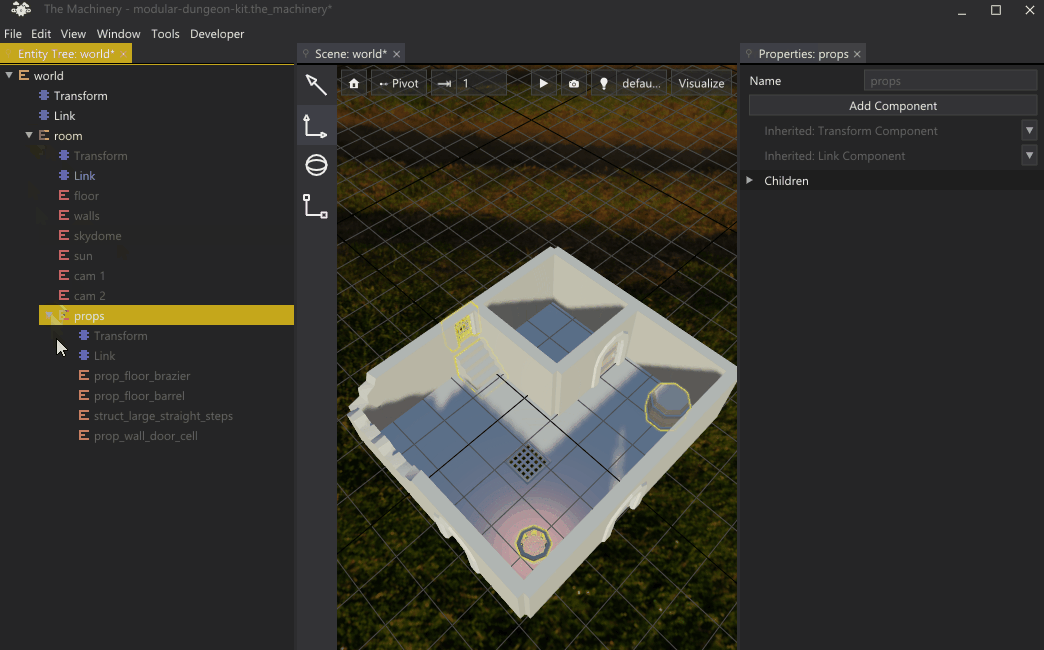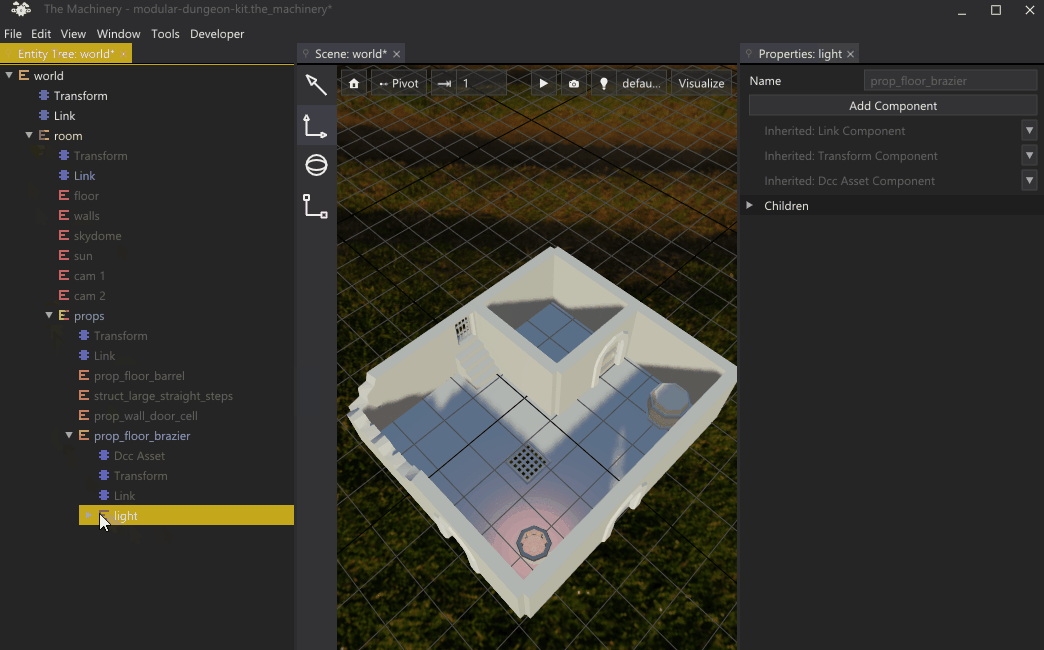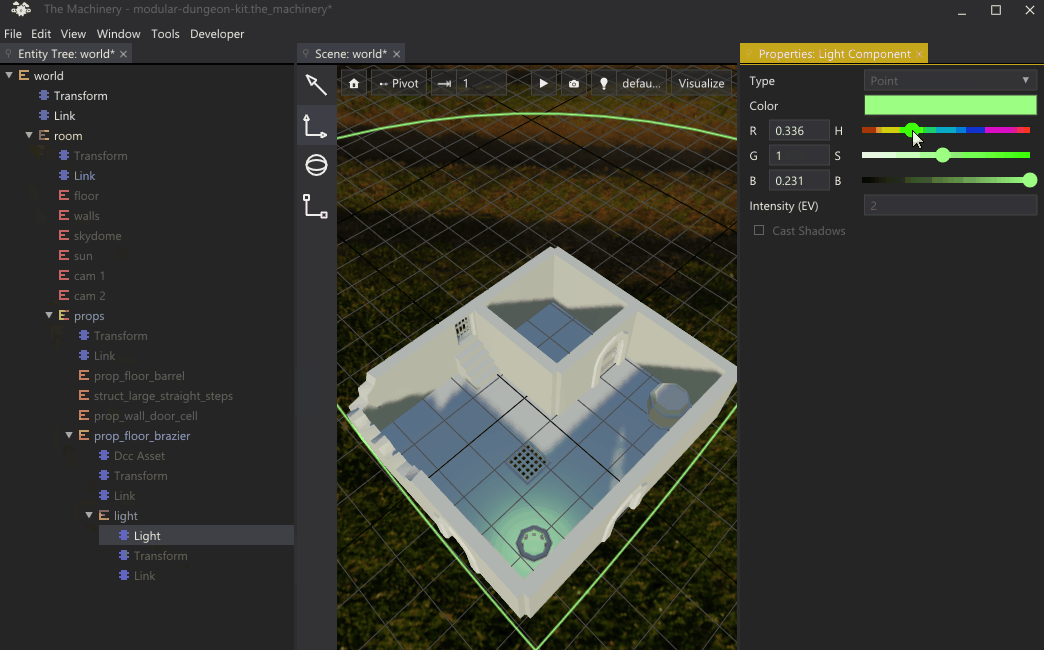
“Drilling down” to the object that we want to override.
Graph editor
Another one of our generic editor views is our Graph Editor. It is used both for visual scripting of entities and for setting up rendering jobs. We also have a, similar but distinct, State Graph Editor that is used by the Animation State Machine.
Prototypes in the graph editor work in a similar way as in the tree views. Nodes that are inherited from a prototype graph are shown grayed out and if you want to edit those nodes, you can right-click them to instantiate/override them.
When we resolve connections in the graph, we automatically take overrides into account, so if you have overridden a node in the graph, any connection to that node is redirected to your override node.
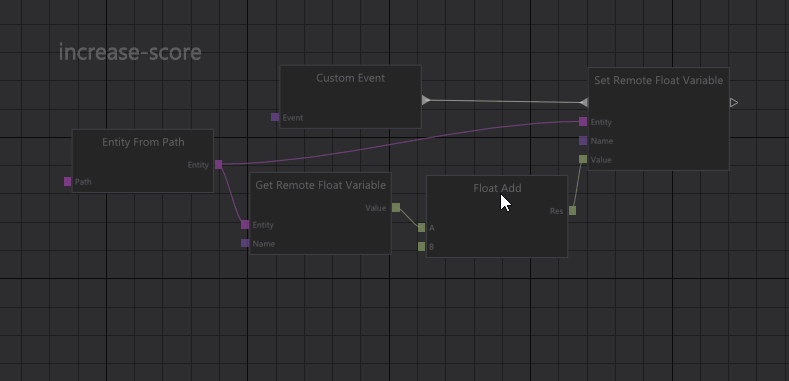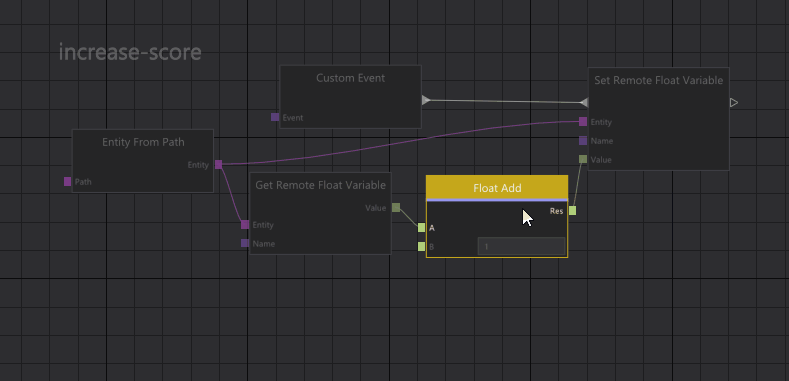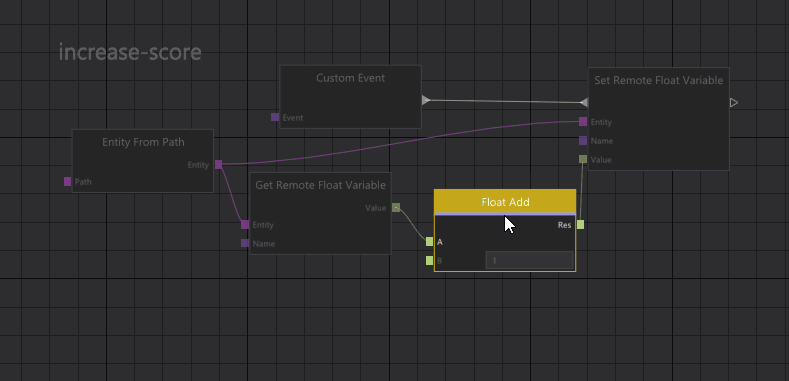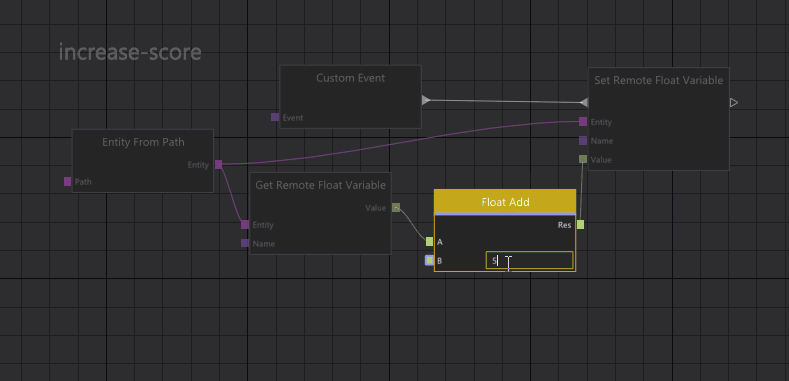
Graph prototypes.
Conclusions and future directions
I think it’s hard to fully grasp all the consequences of a complicated prototyping system like the one that we are using in The Machinery before you have actually implemented it and tried working with it. Now that we have logged some time with it, I think that it overall works really well.
We have a pretty powerful system — supporting arbitrary levels of fully hierarchical prototypes for any object type — that still has a pretty sensible and easy-to-use UI with no need to hand-edit text files.
You can do some pretty mind-bending things with this system, such as adding an entity as a child of itself. Note: to prevent infinite recursion in this case, we only spawn the child entities that are explicitly instantiated.
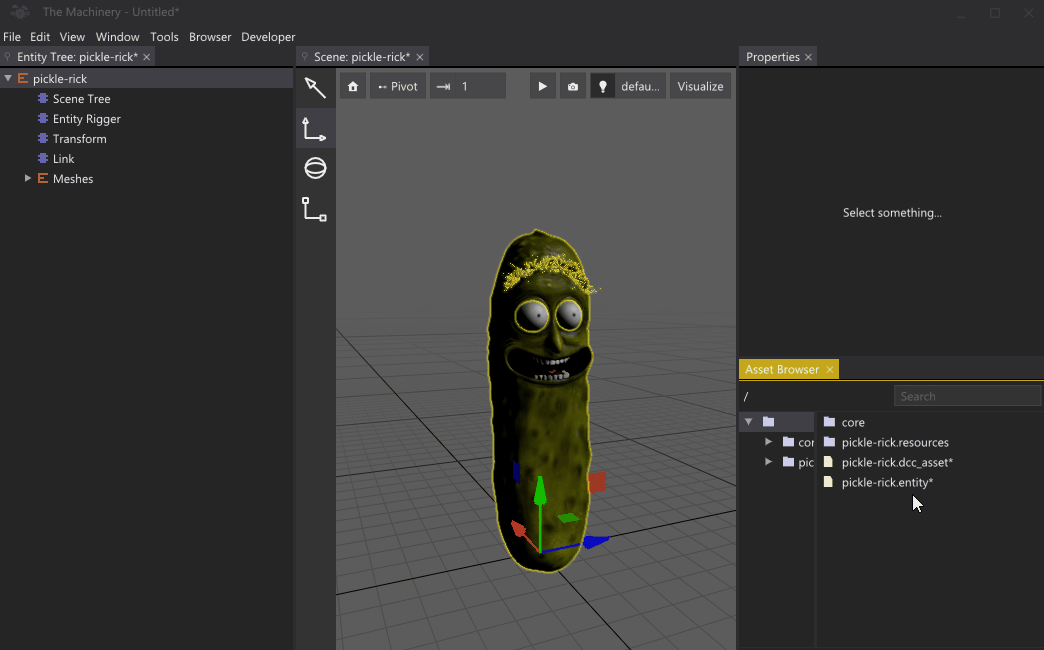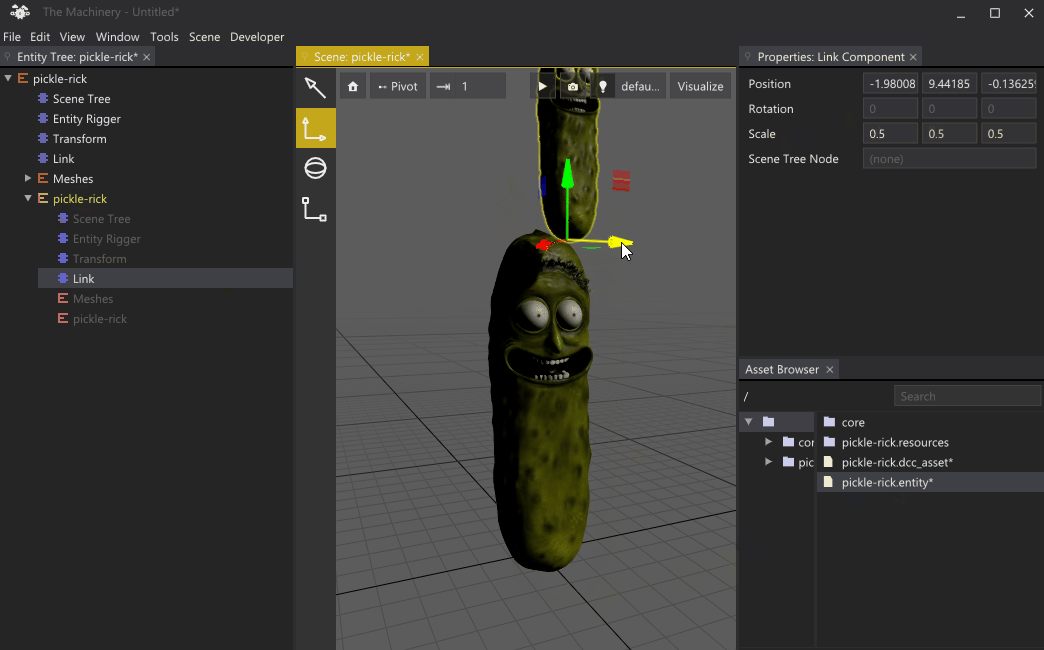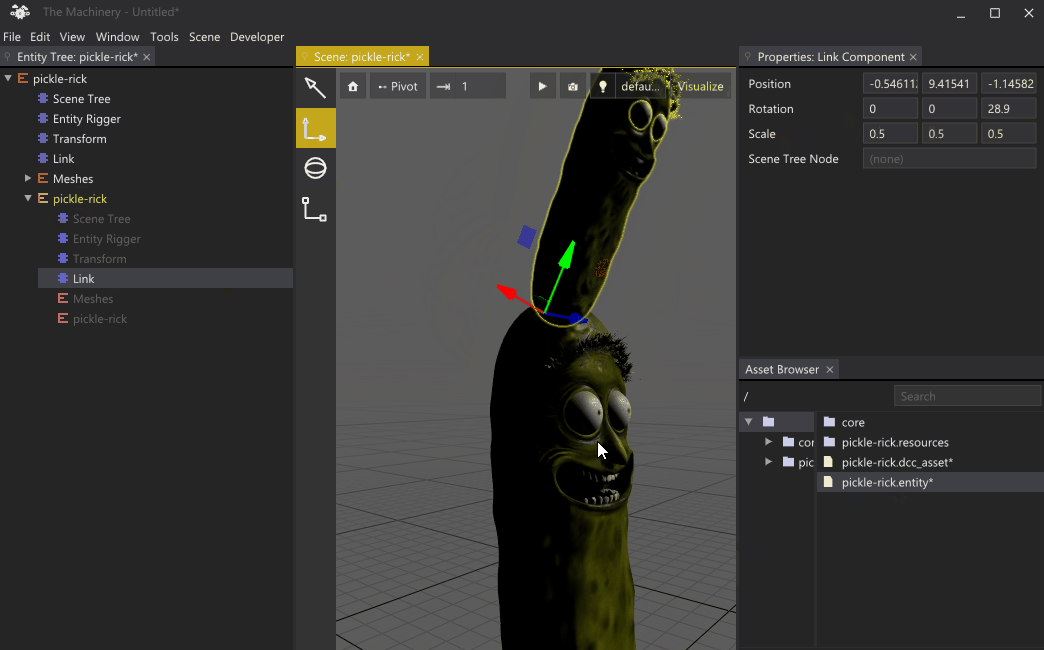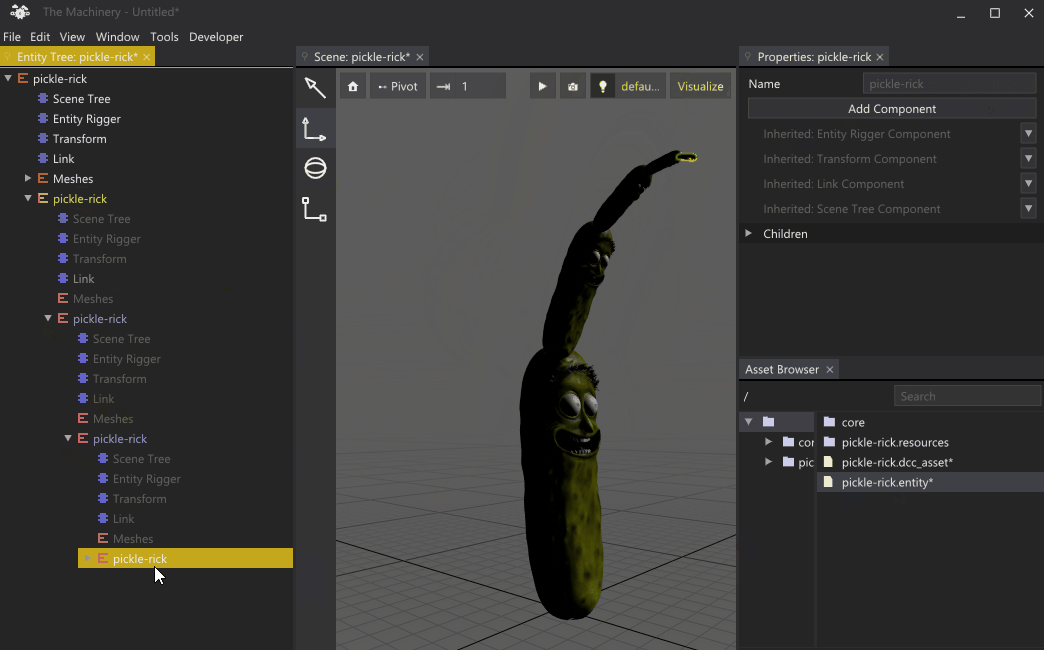
Recursive Pickle Rick (CC BY 4.0 model by Jade Law).
We don’t support complicated dependency expressions, such as hitpoints = prototype.hitpoints * 1.5, but I think it is worth sacrificing that to have a simpler UI. In our case, if you change the
hitpoints of the basic enemy and want the advanced enemy to still have 50 % more, you just have to
go in and edit that manually.
I think there is still some room for improvement though.
Getting rid of the need to “drill down”
I find it pretty annoying that you have to “drill down” when you want to override the property of a subobject deep in the hierarchy. This can be especially annoying when you don’t know exactly where in the hierarchy the subobject that you want to get at resides. You have to speculatively override objects to try to find it and then remove those overrides if you don’t need them.
I think there are two steps needed to fix this. First, inherited objects should be expandable in the tree. This should not have to be too much work, although it requires some refactoring of the tree code. This way, the user could easily drill down and find the object she was looking for. If she then overrides that object, we would override the whole “chain” of objects back to the prototype instance.
The second step would be to allow the user to actually select and edit the inherited objects in the tree without explicitly instancing them first. To do this we would have to put the Property Editor in some kind of special mode where as soon as the user edited any property on the object, we would “lazily” instantiate it. I’m not sure if this is worth doing, it sounds kind of complicated.
But who knows, sometimes when I see a problem like this where I don’t have a good solution, I just sort of let it sit in the back of my mind for a while. Then, one day, a solution pops up. If I can’t find an elegant solution right away, and it’s not super important, I’d rather wait than try to force the issue.
Edit prototype in-place
Another workflow thing that I think would be nice to have is some kind of edit-in-place functionality for the prototype. It’s a bit annoying right now that if you are working on a level that has, say, hundreds of lamp posts in it and you want to do some quick touch-up of the lamp post prototype, you have to context switch and open a new editor window with the prototype in it and then switch back to editing the level.
It would be kind of nice if you could just edit the lamppost prototype “in-place”. I.e., you would something like that, and it would put the actual prototype unit there instead of the instance. You select one of the lamp post instances in the level, right-click it and select Edit as Prototype or could then edit it in the context of the scene and have the changes immediately reflected to all the other lamp posts.
However, I’m not 100 % sure this is worth doing. Modal workflows can be tricky for users and I don’t see a super elegant way of implementing it. Maybe if we fix the “drill down” problem above, it’s easy enough to just edit the instance and then Propagate the changes to the prototype instead of having a separate “edit-prototype-in-place” workflow. I’m going to let this one sit in the back of my head too and see what pops out.
Reference-by-name
The final issue that I keep coming back to in my thoughts is the reference-by-ID vs reference-by-name problem, which I’ve written about before.
The “looser coupling” that you get with a reference-by-name scheme can sometimes be useful. For example, you can refer to whatever the “head” object of the character currently is rather than to a specific “head” object. So even if you “swap heads”, references will still work. Of course, the looser coupling has drawbacks too. You must make up names for everything, references can break more easily, and resolving reference paths can be expensive, so it’s not a clear win for either camp.
Either way, we’re pretty locked-in to using reference-by-ID as the default option in The Machinery now and it’s not likely to change.
The main way reference-by-ID trips us up is in combination with the prototype system. Suppose we have a prototype entity where some subobject refers to the head (by its ID). Now, if we create an instance of that prototype and override the head to replace it, the reference will break, because the new, overridden head will have a different ID and the reference will still point to the old ID (the head from the prototype). To fix this, we would have to find all the objects that referenced the head, override them too, and then repoint the references to the new head. Painful.
This created big problems when we first implemented prototypes for the Graph Editor. Whenever the user would override a node, the new, overridden node would get a different ID, which means all the connections to that node would break. Connections identify nodes by ID and since the new node had a new ID, the connections would no longer point to it.
However, we found a good fix for this. We made it so that when we resolve connections for the graph, we take overridden/instantiated nodes into account. If a connection refers to a node that has been overridden in the current graph, we automatically “redirect” it so that it points to the overridden node instead. With this fix, connections no longer break when nodes are instantiated. The connection still refers to the prototype’s node in the data model, but the way we interpret/resolve that reference in the instance has changed.
I’m now thinking that we could maybe use the same approach for all our references, and most of the problems we have with reference-by-ID would go away.
For example, if we want to replace the head from a prototype, we would override the “head” object in the instance and then modify it to give the character a new head. References in the instance would refer to the old head in the prototype, but when we resolved those references in the context of the instance, we would get the new head, since that new head overrides the old head for this instance.
This still requires a bit of thinking on my part to figure out exactly what it means to resolve a reference in a context and how to do it efficiently (the graph system enumerates all nodes and creates a lookup hash table, which isn’t practical for the general case). But it seems very promising to me. If it works out, it could give us the best of both worlds — solid references that can handle replaced objects.
End
I hope this post gave you some interesting thoughts and ideas on how to implement prototypes in your own system. I think this is still an open issue with lots of room for new ideas.