Should entities support multiple instances of the same component?
The entity-component pattern has been around for a long time. By now I would say that it is widely considered to be the preferred way to write gameplay code. However, there is less consensus on how to actually implement an entity-component system and when you sit down to write it you face some interesting choices.
In this post I’ll look at these choices from the point of a single question:
Should entities support multiple instances of the same component?
and investigate how this choice influences the design of other parts of the system.
Side note: Strictly speaking, I shouldn’t really talk about entity-component systems. In the original formulation, Systems are a part of the Entity/Component pattern. so I should really say entity-component-system systems. But since that is a horrible mouthful, I’ll stick to the slightly incorrect nomenclature.
Entity-component recap
I’m sure a lot of you are already familiar with entity-component systems, but let’s do a quick recap to make sure we’re all on the same page.
The purpose of the entity-component system is to provide a model for simulating objects, that allows us to compose complex objects from simpler components in a flexible and performant way.
In particular, the entity architecture stands in contrast to traditional object-oriented modeling where objects are composed through inheritance. We want to avoid inheritance-based modeling, since it tends to lead to rigid, tightly-coupled structures.
I’ve included performance as part of the purpose, because if we want to use an entity system as our main simulation tool it needs to run efficiently.
The entity-component model is based on three concepts: Entities, Components and Systems.
An Entity is a distinct simulation object that lives in some kind of simulation Context or World.
A Component is a piece of data of a certain type that is asscoiated with an entity. What component types exist depend on what we want to simulate in our world. For example, a combat simulation may have components related to ammo, health, etc. A physics simulation may have components related to mass, electric charge, etc.
Note that I will somewhat sloppily use the word “component” to refer both to a type of component (i.e., health, mass, …) and to a specific instance of a component type that is owned by a specific entity (i.e., the health of a particular entity).
A System is some kind of simulation or update process that runs in our world. For example, a system could simulate forces on objects moving in an electrical field or how a person’s health is affected by poison.
Note: I sometimes find the word “system” to be a bit too vague and ambiguous, so I will alternately refer to these processes as Simulations.
In the traditional entity-component setup, a system runs on all entities that have a certain set of components and the system update reads and/or modifies the values of those components. For example, a physics system might run on entities with mass, position and velocity component.
One thing that I haven’t seen discussed a lot is that simulations sometimes need to store data that doesn’t fit in the components. For example, a physics simulation typically need to store some sort of broadphase representation in order to quickly find pairs of colliding objects. This is a hierarchical data structure that cannot be represented well by individual component pieces. We can achieve this by adding state to the simulations as well as callbacks for when components are added and removed, so that the state can be updated accordingly.
Another thing that is not often discussed is that some simulations need to consider interactions between objects. For examples — physics simulation needs to check object pairs for collisions. The simulation therefore needs to run as a single call, with access to all objects.
All the individual simulation updates, when taken together, create the full simulation that we want to achieve in the world. The nice thing about the enity-component formulation is that it lets us break this total simulation up into smaller isolated pieces that are easier to understand, write and debug.
Here is an illustration, showing some entities with components living in a context with two running simulations: Rendering and Physics:
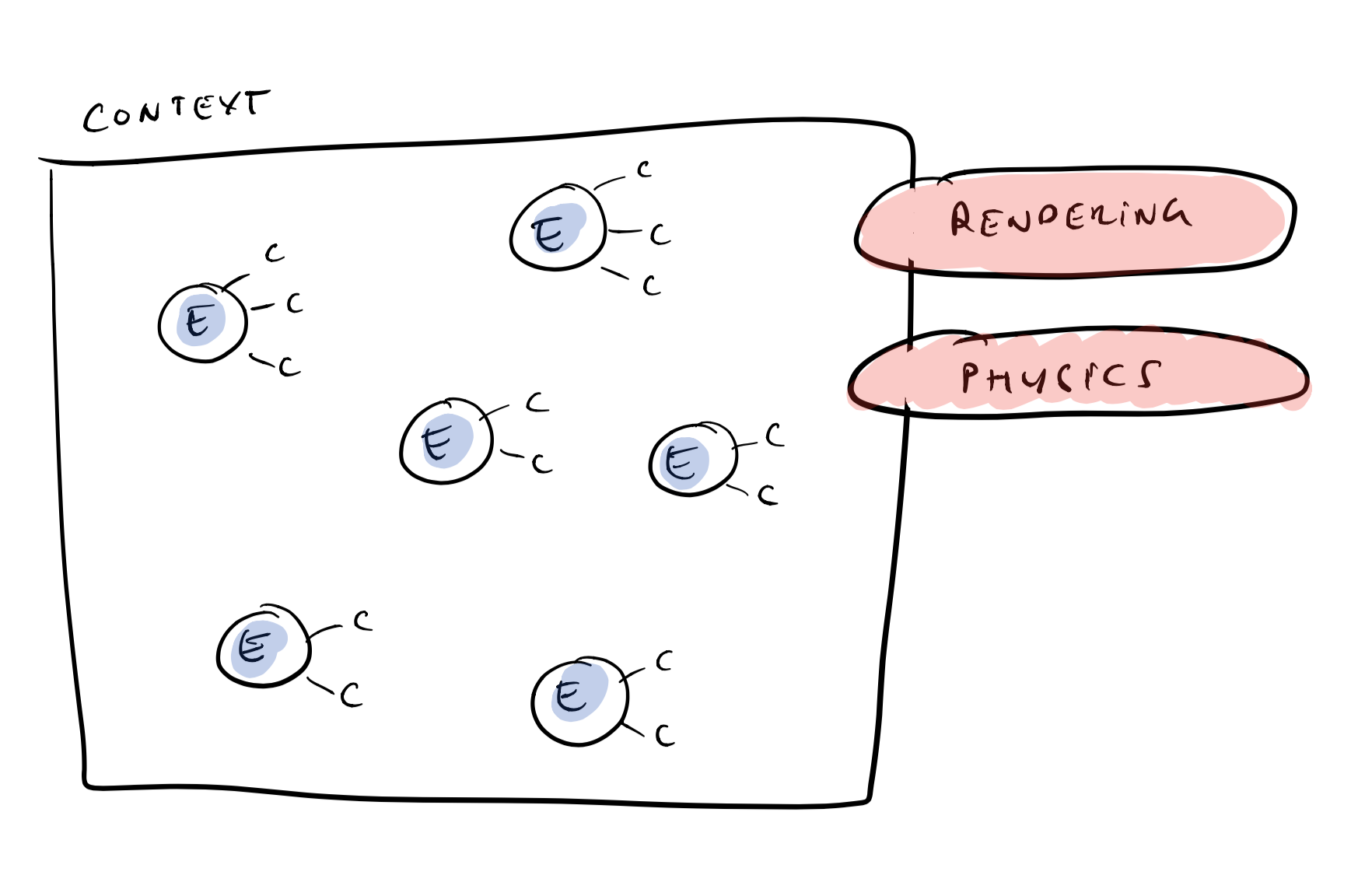
Entities, components and systems.
Regarding performance, the most important thing is that the simulations can run as fast as possible, since that is typically where we will be spending the most of our time. In addition, it should be reasonably fast to create, destroy and search for entities.
Multiple vs single components
With this in mind, let’s get back to the initial question — when we design an entity system should we allow for entities to have multiple components of the same type?
In the original formulation of the ECS model, an entity can only have a single component of each type. This makes sense for things like position and mass — we don’t expect an object to have two different positions or two different masses. But for other cases it seems too restrictive. Consider a light component for instance — it seems weird and artificial to limit an entity to only having a single light. The same could be argued for sound sources, meshes to render, collision shapes, etc.
Without support for multiple components if we want to represent an entity with multiple lights we have two choices. Either we have to create child entities to the original entity and put the lights on these child entities. Or, we have to change the light component to a lights component — i.e. a component that holds a list of lights rather than a single individual light. Both approaches seem more complicated.
But supporting multiple components comes with its own set of complications. When we only have single components, we can uniquely identify a component by entity and component type. With multiple components, this is no longer enough, because we can have multiple components of the same type. To disambiguate, we need to add something like an ID to specify which particular component we are talking about. So a component instance is now identified by (entity, component type, id).
This may seem like a small inconvenience, but it has far reaching consequences. For example, we can no longer talk about the position of an entity, since there might be multiple position components. We can only talk about the position of component with a certain ID. So an entity has no “true” position.
To an extent, we can fix this by forcing the position to be a singleton component — i.e. even though we allow some components to have multiple instances, some components can only have a single instance. But this further complicates the system — now we have two different kinds of components to deal with — singletons and non-singletons. Also, it might not even be what we want. What’s the point of supporting multiple light sources if they are all in the same position? Maybe we do want multiple position components and a way of associating a certain light component with a certain position component.
Implementing simulations that operate on multiple components also becomes tricky. For example, consider a simulation that operates on (mass, position, velocity). How should that work if an entity has say two mass components and three position components? We probably don’t want the simulation to run on all possible combinations of components, so we nee a way to specify how components can be combined for system updates.
One approach would be to store the position component ID in the light component, but note that in order to do that we need to create a tighter coupling between components and systems. I.e. we add the reference to the position component in the light component based on the knowledge that an update needs to run on the light that needs access to the position. When we design the light component we thus need to know all possible simulations that will run on this component and what other components they might need access to.
Thinking about it, I don’t think there is a way of matching and pairing components in a multiple component scenario without creating this tighter coupling. Consider the tricky case of pairing components when we have two mass and three position components.
To make multiple components work I think each system or simulation needs to have a tightly coupled associated component. This component can stores the data for that particular system update as well as references (with IDs) to other components that might be needed.
This solves our (2 x mass, 3 x position, velocity) problem. To disambiguate we create a physics component to go with the physics update. In this component we store references (IDs) to the different mass, position and velocity components used for this particular update. Now we can form any combination of these components we like by just adding corresponding physics components. If we want to simulate all possible combinations, we just add all six of them.
But note how this approach creates a much tighter bond between the simulation and its matching component then what we have in the original ECS formulation, where components are just free floating data that simulations can do whatever they like with.
This is not necessarily a huge drawback. This tighter coupling matches well how we normally write systems. We have a physics system that operates on physics actors (components). A particle system that operates on particle components. A rendering system that operates on renderables. Etc. Free form combinations of different pieces of data is not as common.
The interesting thing is to see how the choice between multiple and single components leads to a need to tightly couple component data to a system.
The tight coupling of a system and its component data in turn means two things:
- The system can freely choose how to store the component data.
- Accessing data from other components will necessarily be inefficient.
Since the system specific data is only accessed by that system, the system can choose whatever layout it wants. It can use array-of-structures, structure-of-arrays or even store part of the data on the GPU. Whatever is more efficient.
In contrast, with a looser coupling, the component data must be stored in a more generic format so that it can be efficiently accessed by any simulation that wants to use it. No single simulation can dictate how the data should be stored.
With the tight coupling, accessing data from another component necessarily requires an indirection step. Given the ID of another component we need to perform some kind of lookup to get to the data of that component.
In the loose case, since there can only be one instance of each component, we can make sure they are co-located and already matched up in memory. That way, no additional lookup is needed.
In practice, one way of making it work is like this: We define an entity type by the components the entity has. Since in the single component case there can only be one component of each type, we can identify the entity type with a bit mask. We store the data for all entities of a certain type together (in either array-of-structure or structure-of-arrays form).
When we want to perform a particular simulation, we loop over each entity type and check whether its bitmask matches the components needed for this particular simulation. If it does, we run the simulation, passing it pointers to the component data arrays. The entries in these arrays already correspond to components from the same entity and thus, no additional lookup is needed.
In theory, there could be a huge number of different entity types (two to the power of the number of components), which would make this method inefficient. In practice, we expect that only a small number of entity types will be used.
Conclusion
Summarizing, here is a table showing the consequences of going with a multiple or single component approach:
| Multiple components | Single components |
|---|---|
| Multiple things represented naturally. | List components or child entities needed. |
| ID needed to identify a specific component instance. | Entity and component type is enough. |
| No “true” position. | Less ambiguity. |
| May need special code to manage “singleton” components. | Simpler. Everything is a “singleton” component. |
| Simulation specific components needed. | Loose coupling between simulations and component data. Data is just data. Simulations are just functions. |
| A simulation can fully control how its component data is stored. | Component data needs to be stored in a “general” format that is quick to access from any simulation. |
| Accessing data from other components than the simulation component is slow. | Any component data can be accessed quickly. |
In Stingray, I used the multiple component approach. The ability of each system to be in full control of how its data was stored and being able to optimize that data for fastest possible access was appealing to me.
In The Machinery, I’ve instead chosen to go with the single component approach. I like it’s simpler, more decoupled approach and that you can access any component without a need for a lookup. Also, we can still use custom data layouts when needed, by just storing an index in the “public” component data and using that as a reference to an internal data structure whose layout we control.