The Machinery Shader System (part 3)
This will be the third and probably last part in my series covering the “shader system” in The Machinery that I’ve working on as a back-burner project over last three months. If you haven’t read part two, I suggest you do so before continuing as they provide context and build the foundation for what we’re going to talk about today, namely:
- Generation and compilation of shader variations (e.g. skinning on/off, light maps on/off, etc.).
- Runtime selection of which variation to use based on context.
- Management of grouping of constants and resources with different update frequency needs.
I’ve always been frustrated trying to find clean solutions for the above points, and while I can’t say I’m certain that what I have implemented to handle this in The Machinery won’t change, I do feel my new take on it has a lot of potential compared to my previous approaches.
Disclaimer: Typically I don’t write posts about stuff that I’m in the middle of developing as I’m usually too confused to see things clearly when my brain is too deeply buried in the code. Today I will make an exception to that in an attempt to clarify some concepts in my brain and hopefully land in a cleaner solution.
Systems
Right now I’m exploring a single solution that solves all of the above points and goes under the somewhat tentative name “Systems”. The idea is fairly simple:
The author of a shader declares one or many variations to compile, each variation is defined by listing one or many systems it depends on. Each system can both inject arbitrary shader code as well as import constants and resources. Constants declared within a system will end up in its own constant buffer, and any resource declared will be bound to the shader using its own resource binder.
A system is defined using the same building block as a regular shader: tm_shader_decalaration_o but won’t be compiled into a functional shader. Instead it compiles into a tm_shader_system_o which only provides methods for instancing constant blocks and resource binders with helper methods for updating arbitrary constants and resources within those.
Typically a tm_shader_system_o defines some kind of context, a few arbitrary examples:
- Frame parameters — frame number, time, delta time, anything you can think of that changes at most once per frame.
- View context — camera properties, relevant information about output render targets and similar.
- Lighting environment — arrays of visible light sources and various acceleration structures.
Above examples have in common that they can be thought of as a way to bind global data that is constant for lots of draw/dispatch calls, where the update frequency of the data is easy to control using some form of scope based mechanism.
For these type of systems I use a stack based mechanism to control activation/deactivation of systems and what data they expose to the shaders. I call this stack tm_shader_system_context_o and it gets passed down to all rendering systems as a const object. Since we are running heavily parallel we can’t allow arbitrary mutation of the context, so if the receiver wants to mutate the context (to temporarily enable some additional system) she has to clone the context first, enable the wanted system, and then pass down the cloned context to any other rendering systems it needs to call.
The actual variation selection within a shader is currently based on a doing a hash map lookup using a hash generated from all active systems. Each time a system is activated/deactivated in the context the hash is recomputed. For this to work, all shader variations the shader author creates have to list their system dependencies in the exact same order as they will appear in the context, also they cannot omit any systems even if the shader isn’t depending on them. My gut feeling tells me that this is a too rigid requirement that I will regret as it creates an implicit coupling between shaders and all available systems. In practice this means that shader authors will have to be aware of all existing systems (together with their activation order) which will make it close to impossible to introduce new systems without updating existing shader code. So right now I’m leaning towards rewriting it, my plan for the rewrite is to associate each system with a unique bit in an arbitrary long bitmask, and then create a bitmask representing all active systems and use that to lookup the correct variation instead.
A nice thing with a looser lookup is that we easily can use the same method for handling platform specialization of shaders. Say that we author a shader that has different quality settings and hardware requirements, with a more loose lookup we can simply describe each setting using a system. Then based on user settings and/or hardware capabilities we just activate the corresponding “setting systems” and the correct shader variation will be selected.
Increasing the update frequency
So far we’ve only discussed systems who’s data is constant across lots of draw/dispatch calls, but there’s also a need to handle systems who’s input data tends to vary more frequently than that. A typical example is various types of vertex deformations like skinning or morph targets. In this case we have data that is constant across multiple views and materials, but that varies between object instances.
As mentioned earlier, a system can instantiate any number of constant buffer and resources binder instances, so there’s nothing stopping us from using the same system concept to handle this scenario. The only difference is that we don’t push/pop these systems on to the tm_shader_system_context_o, instead we pipe them explicitly to the function that selects the right shader variation based on active systems and assembles all the data needed to bind the shader with all its inputs.
Materials
If you read part 1 of this series you might remember that I talked about the idea of letting the shader system have two tiers. So far we’ve only talked about tier 0 which doesn’t have any concept of multi-pass shaders or frame scheduling. In my previous shader systems I’ve had those concepts built into the regular shader object, but I’ve always struggled coming up with good terminology describing the different abstraction layers you end up with when shoving everything into the same object. As if it wasn’t bad enough that a shader isn’t just a wrapper over a shader program but rather a wrapper around a set of shader programs (one per active shader stage), if we also add the concepts of multi-pass shaders into the mix, a shader becomes something even more obscure that wraps multiple shaders with each shader in turn wrapping multiple shader programs.
On top of that we end up with having to introduce some kind of frame scheduling awareness into the shader system, something that can reason about when in the frame (into which layer, like e.g the g-buffer or the skydome layer) a particular shader within the shader should execute.
This is where tier 1 of the shader system comes in, introducing something that I have decided to simply call a Material for now.
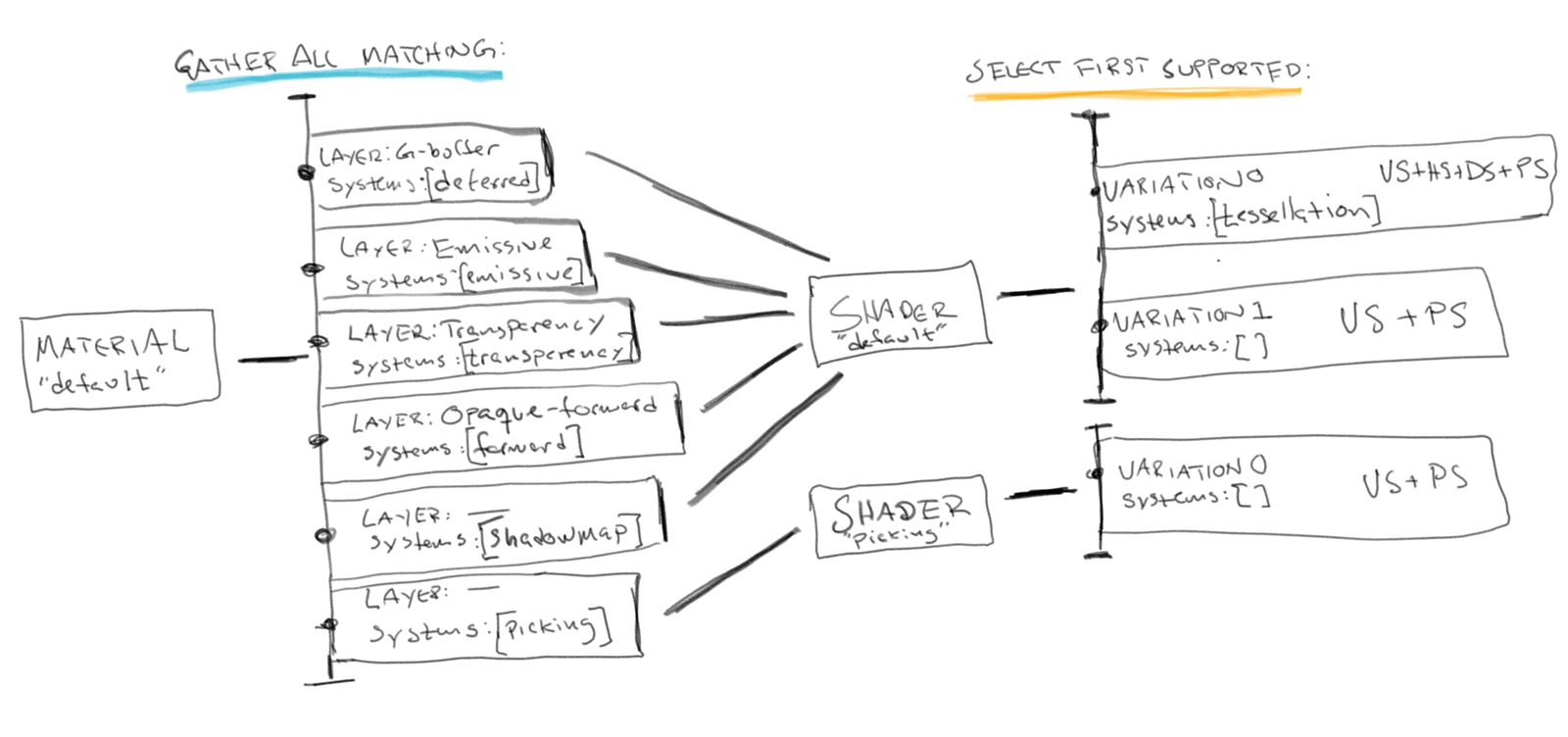
Setup of a material
A Material is a high-level concept and can be though of as an array of shaders to compile. Each element in the array points out the render graph which provides us with the ability to schedule a particular shader for execution at any time during the frame.
Here’s an example of what the JSON front-end representation of the Material illustrated above might look like:
{ "material" : [
{ "layer": "g-buffer", "shader" : "default", "systems": ["deferred"] },
{ "layer": "emissive", "shader" : "default", "systems": ["emissive"] },
{ "layer": "transparency", "shader" : "default", "systems": ["transparency"] },
{ "layer": "opaque_forward", "shader" : "default", "systems": ["forward"] },
{ "shader": "default", "systems": ["shadow_mapping"] },
{ "shader": "picking", "systems": ["picking"] }
]}
This will compile the shader declaration named “default” into five variations, together with a single variation of the shader declaration named “picking”.
All of the resulting shaders will get a shared resource binder and constant buffer representation (i.e a super-set of all referenced resources and constants will be generated during the material compilation). This is important as it solves the issue of having to broadcast the same constant or resource into multiple constant buffers or resource binders which otherwise can happen if two or more shaders reference the same constant or resource and there’s no a awareness between the different shaders, the Material creates that knowledge bridge.
The selection of which shaders to use when rendering with a material is quite similar to the variation selection that happens within a shader, except that a material does not stop after it has found the first shader that matches the active system list. Instead it will go on and gather all shader variations that matches the full list of active systems and potentially return an array with more than one shader to execute.
Wrap up
I think that covers the core idea behind my current attempt at solving a bunch of rather complicated problems using a single concept — “shader systems”. The code I have in place today still needs to be iterated on to behave exactly as described in this post, while doing that it’s not unlikely that some design will change. Overall though I feel fairly confident that this is a decent approach that will work out better than my previous solutions.