The Story behind The Truth: Designing a Data Model
I’ve talked a little bit before about The Truth — the system we use for representing data in The Machinery. But I haven’t said that much about the rationale behind it — why we chose this approach over something else. Jascha Wedowski wrote to us on Twitter and wanted to know more about that and I think it makes for a really interesting blog topic, so here we go!
What is a data model and why should you have one?
Let’s start at the beginning. Most software programs need some way of representing and storing data. To have a word for it, we call it the application’s data model. There are many possible kinds of data models:
- XML files together with some kind of schema.
- JSON files with some agreed upon structure.
- An application specific custom binary format.
- A shared binary format with a well defined structure, such as ASN.1.
- A relational database.
- A non-relational database (nosql).
- An hierarchy of versioned objects with hash identifiers (like a git repository).
- Etc…
An application can have multiple representations of the same data. For example a program may use JSON configuration files on disk, but when the program is booted those files are read into in-memory data structures. The JSON files are permanent, have a well-defined structure and can be easily shared between programs. The in-memory representation is faster to access, but temporary, lacks a high-level structure and can’t be easily shared.
In this post, when I talk about the data model I’m mostly talking about these more permanent, structured models.
Most programs do not handle that much data and computers are pretty fast so they can convert between a structured file representation and a high-performance memory representation each time the program is run, or each time you open a file. But games are different. They often deal with gigabytes of data and need to run really fast. Converting all that data on each boot of the game would lead to really long startup times. Therefore, they often convert from the structured format to the in-memory format in a separate data-compile step. They store the in-memory representation on disk (it needs to be stored somewhere), but in such a way that it can be quickly streamed into memory and used immediately without any costly parsing or conversion.
Why not just use the in-memory format all the time and skip the compile step? You could, but typically the more structured format (whatever format it takes) has some advantages. For example, the compiled data might be one big .pak file, which doesn’t work well with version control. It might not merge well and thus not be a good fit when more than one person works on the project. It might also throw away information such as debug strings or compress textures to reduce the size of the final game.
Having a structured data model is useful because it allows us to implement features that we want our data to have on the data model itself, rather than on the systems that use it. This means that we only have to implement the feature once, and all systems will get it, rather than having to do a separate implementation in each system.
For example, consider backward compatibility. Backward compatibility means that a future version of our program is able to open files from an older version, even if the data has changed in some way (for example, we may have added new properties to an object). It is a pretty essential feature, because without it, an application update would break all the users’ old files.
Without data model support, supporting backward compatibility might mean keeping all the code around for parsing every past version of the data. Your code might look something like:
if (version == VERSION_1_0) {
...
} else if (version == VERSION_1_1) {
...
} ...
In contrast, if your data model handles backward compatibility you don’t have to do anything. As an example of how that might work, consider JSON. As long as you are just adding and removing properties, and give any new properties reasonable default values, JSON will automatically be backward compatible. JSON can also do a decent job of forward compatibility — i.e., allowing old executables to open newer data. The old executables will just ignore any properties they don’t understand. Forward compatibility is hard to achieve without some sort of structured data model, since you can’t do an if (version == ???) test for unknown future versions of the data.
In addition to backward and forward compatibility there are a bunch of other things that a data model can potentially help with:
-
Dependency tracking. If the data model has a consistent way of representing references, you can use it to detect missing or orphaned objects (objects not used by anyone).
-
Copy/paste. If the data model supports cloning objects, copy/paste operations can be implemented on top of that. This means that you don’t have to write custom copy/paste code for all your different objects.
-
Undo/redo. If the data model keeps track of a history of changes, undo can be implemented simply by rewinding the history. This is a lot simpler than using something like the Command Pattern to implement undo.
-
Real-time collaboration. If the data model has a synchronization protocol, you get collaboration for free. Users can just make local changes to their data, and through the replication protocol, those changes will be propagated to other users in the same session.
-
Offline collaboration. By offline collaboration, I mean collaboration where you explicitly push and pull changes from collaborators (instead of all changes happening in real-time). In other words, the regular version control model. Since most version control tools are based around text-based merging, in order to support offline collaboration nicely, your file formats must be human readable and merge easily (unless you want to write your own merge tools).
In short, by putting a lot of responsibilities on the data model you can make the UI code for the editor a lot simpler. This is really important to us, because one of the problems we had in Bitsquid/Stingray was that we spent a lot of time on developing UI and tools. Sometimes we would spend 30 minutes to add a feature to the runtime and then a week to create a UI for it. In The Machinery we wanted to address that imbalance and make sure that we could write tool and UI code as efficiently as runtime code. (Of course, anything involving human interface design will always be somewhat time consuming.)
The Bitsquid/Stingray data model
Picking a data model means balancing a range of different concerns. How fast does the code need to run? How much data does it need to handle? Do we need the model to support Undo, Copy/Paste, Collaboration, etc?
It’s not an easy choice, and once you’ve made it you’re usually stuck with it. You can’t change the data model without either breaking all your users’ data or writing a data migration tool, which can be tricky and time-consuming.
To understand our choices for The Machinery, it is helps to compare it to the data model we used for our last big project — Bitsquid/Stingray. The choices we made for The Machinery are in part a reaction to the problems we saw with that model.
In the Bitsquid engine, data was represented as JSON files on disk (with some exceptions, we used binary data for things like textures). The data was read by a federation of independent, but co-operating executables, such as an Animation Editor, Sound Editor, Level Editor, etc. For the runtime, this JSON data was compiled into efficient .pak files that could be streamed from disk directly into memory.
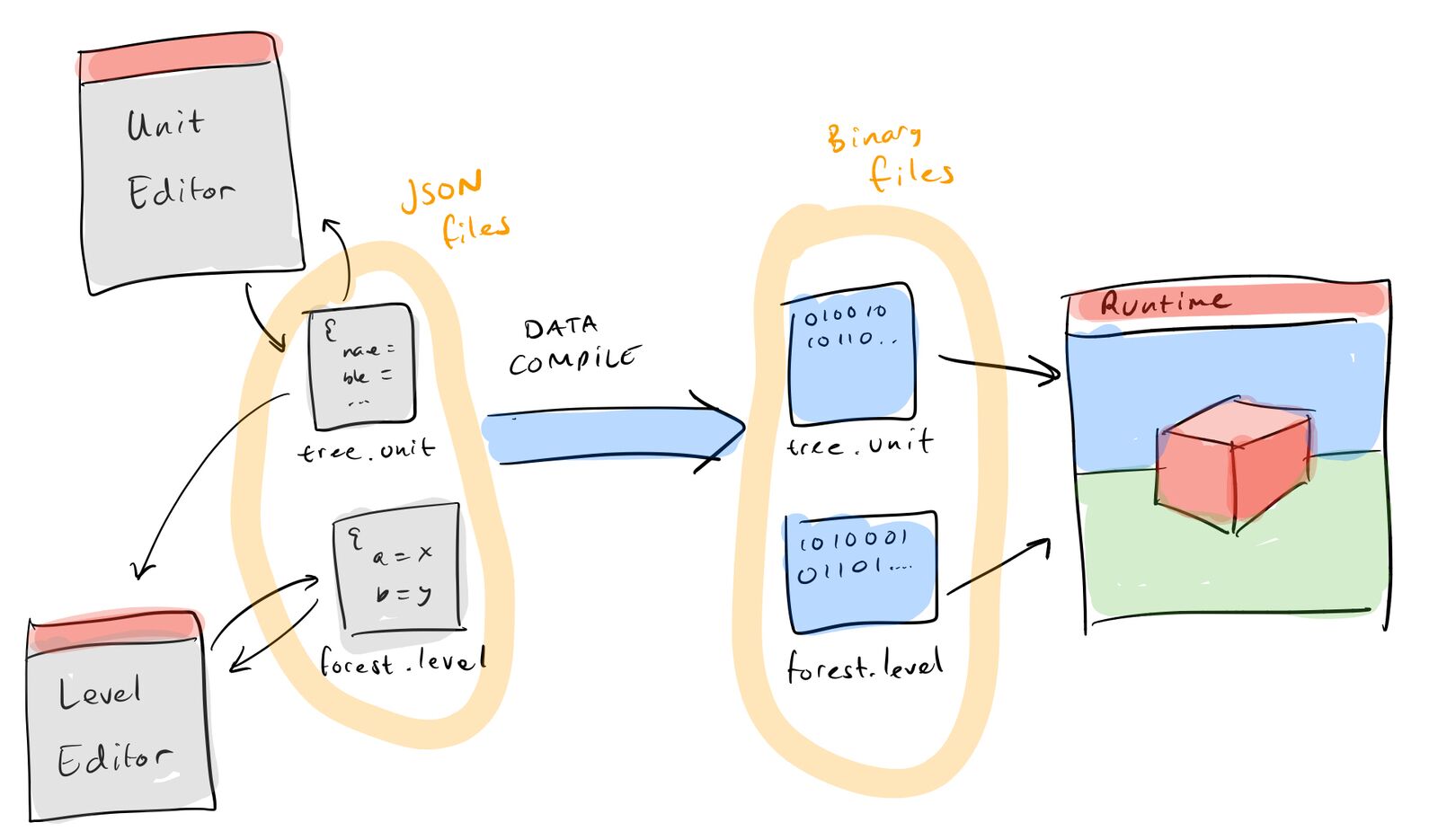
The Bitsquid/Stingray data model.
This model of having multiple independent tools and a separation between editor and runtime data has both advantages and disadvantages.
On the plus side it provides a lot of independence. The runtime doesn’t care about the tools, it just needs to be fed data in the format it likes. And the tools don’t even need to know about each other. Each tool can be focused on a specific task, making the source code small and manageable. It is easy to throw a new tool into the mix, or replace an existing tool with a new one. Unwanted coupling is one of the biggest problems of large software systems, so this independence is really valuable.
A drawback is that you end up with a lot of repetition, since a lot of tools will need similar functionality: UI, engine viewports, copy/paste, undo, JSON parsing, etc. To some extent this can be mitigated with the use of common libraries, but relying on common libraries means coupling starts to creep back in. As these common libraries grow larger and larger with more shared functionality, the tools get less and less independent.
By design, co-operation between the different tools and between the tools and the runtime is also tricky. Remember that the data model consists of the JSON files on disk. This means that a tool cannot see changes made by another tool unless those files are saved to disk. In the case of the runtime, the changes must be saved to disk and compiled to the runtime data format.
This has a number of implications. First, it prohibits any real-time co-operation between the tools, since they don’t share data. Second, it means that the 3D viewports in the tools (which are using the runtime) cannot show the user’s changes until those changes have been saved and compiled. Finally, since the runtime can only access the compiled data, it is not possible to edit data using the runtime. This means it becomes tricky to create things like a VR editor — where you edit stuff from within the runtime.
These problems can be hacked around in various ways and for the most part that is what we ended up doing. To give an example, to workaround the problem that the editor viewports can only show “saved” data, the tools would continuously save the user’s unsaved edits to temporary files that could then be compiled and displayed by the runtime.
While hacks like this can be made to work, it is not a very nice solution. It makes the system complex and tricky to reason about. There are a lot of unnecessary disk operations, and race conditions can occur when multiple tools try to write temporary files and compile the project.
When Autodesk acquired Bitsquid and renamed it Stingray, we wanted to move from this collection of tools to a single unified editor. While this in theory should have made it possible to share data between the tools and fix some of these issues — the rewrite was such a big project that it in fact never fully completed during our time at Autodesk. In the end, there were still some tasks that required using the “old tools”, and the basic setup with the JSON files on disk being “authoritative” wasn’t changed.
Other problems with the Bitsquid data model were:
-
Since the model was disk-based (the JSON files on disk were authoritative) it couldn’t represent in-memory operations such as Copy/Paste and Undo. These operations therefore had to be custom-written for each tool.
-
While the data model could represent references to other files with a path
texture = "trees/03/larch"these “reference strings” were not distinguished from other strings in the JSON files. Thus, you couldn’t reason about references without knowing the semantics of each file. Also, there was no consistent way of representing references to a sub-object inside a file. -
Again, with a disk-based model there was no way of implementing real-time collaboration in the data model. While the Bitsquid level editor had real-time collaboration support (based on serializing the commands in its undo-queue), the lack of a consistent data model between the tools meant that collaboration didn’t carry over to the other tools. And when the tools were unified to a single all-in-one editor, this collaboration feature was lost.
The Truth: The data model we use for The Machinery
In The Machinery we store our data as objects with properties. This is somewhat similar to the JSON model we used in Bitsquid, except as explained later, we don’t actually represent the data as text files. Each object has a type and the type defines what properties the object has. Available property types are bools, integers, floats, strings, buffers, references, sub-objects and sets of references or sub-objects.
The object/properties model gives us us forward and backward compatibility and allows us to implement operations such as cloning without knowing any details about the data. We can also represent modifications to the data in a uniform way (object, property, old-value, new-value) for undo/redo and collaboration.
In contrast with the Bitsquid approach, the model is memory-based rather than disk-based. I.e. the in-memory representation of the data is considered authoritative. Read/write access to the data is provided by a thread-safe API. If two systems want to co-operate, they do so by talking to the same in-memory model, not by sharing files on disk. Of course, we still need to save data out disk at some point for persistence, but this is just a “backup” of the memory model and we might use different disk formats for different purposes (i.e. a git-friendly representation for collaborative work vs single binary for solo projects).
Since we have a memory-based model which supports cloning and change tracking, copy/paste and undo can be defined in terms of the data model. Real-time collaboration is also supported, by serializing modifications and transmitting them over the network. Since the runtime has equal access to the data model, modifying the data from within a VR session is also possible. This fixes a lot of the pain points with the Bitsquid approach.
We make a clear distinction between “buffer data” and “object data”. Object data is stuff that can be reasoned about on a per-property level. I.e. if user A changes one property of an object, and user B changes another, we can merge those changes. Buffer data are binary blobs of data that are opaque to the data model. We use it for large pieces of binary data, such as textures, meshes and sound files. Since the data model cannot reason about the content of these blobs it can’t for example merge changes made to the same texture by different users.
Making the distinction between buffer data and object data is important because we pay an overhead for representing data as objects. We only want to pay that overhead when the benefits outweigh the costs. Most of a game’s data (in terms of bytes) is found in things like textures, meshes, audio data, etc and does not really gain anything from being stored in a JSON-like object tree.
Sometimes it can be tricky to draw the line between what should be considered “buffer data” and “object data”. What about animation data for instance?
I would say that anything that can be considered as a big array of uniform items works better as buffer data. So I would put the raw animation tracks (positions, rotations) into buffers, but blend trees and state machines into object data.
In The Truth, references are represented by IDs. Each object has a unique ID and we reference other objects by their IDs. Since references have their own property type in The Truth, it is easy for us to reason about references and find all the dependencies of an object.
In general, a data model can reference things either by unique IDs (dc002eba-19a5-40d1-b9b8-56c46173bc8f) or by paths (../textures/03/larch). For example, file systems often support both hard links (which correspond to IDs) and symbolic links (which correspond to paths). They each have advantages and disadvantages. With IDs, the system can make sure that references never break (by keeping objects alive as long as they are referenced). They’re also cheaper to resolve since they don’t require any string processing. And, they can be easier to reason about, since the same reference will always resolve to the same object.
Paths, on the other hand, are human readable which makes them easier to edit and hack. They can be used to refer to things that may or may not exist or things that might not exist now, but may exist in the future. I.e. ../head/hat might resolve to NULL now, but refer to the hat I’m wearing once I put it on. They can also refer to different things based on context. I.e. ../head/hat will refer to different things for different characters. On the downside, paths are more fragile. If an object is moved or changes name, the reference might break.
Choosing between using paths or IDs is not easy and I’ve gone back and forth over the years. With The Machinery we decided that our primary goal was to make sure that references didn’t break, so we decided to use IDs as the main mechanism. In addition this makes the code run faster and saves us a lot of checks to verify that referenced objects actually exist.
We might still use path references in some places where a more “loose” and “dynamic” resolution can be beneficial. For example, using .. to refer to an entity’s owner (which might change depending on where in the hierarchy the entity is instanced) can be really useful while scripting entity behaviors. In this case, we pay the cost of slower code and extra checks to get the benefit of a looser connection.
Sub-objects in The Truth are references to owned objects. They work just as references, but have special behaviors in some situations. For examples, when an object is cloned, all its sub-objects will be cloned too, while its references will not.
Is The Truth awesome?
Did we achieve what we set out to do with The Truth data model? Definitely.
Having a single in-memory representation of the editor state has made implementing UI and tools a lot easier. There is a ton of stuff we get for free with The Truth: automatic propagation of changes between different editor windows, copy/paste, undo and even real-time collaboration. What’s more, all of this works not only in our own code, but also in plugins made by other developers.
But I would stay it is still a bit too early to do a full post-mortem of The Truth. It takes time and perspective to get a full picture of the advantages and disadvantages of a system. We need to throw more people and bigger projects on it to see how it works out. And there are still some unanswered questions:
-
While the data in The Truth can be accessed really quickly, it is still not as fast as a packed custom binary format. So there is still a need for “runtime” data formats. How and when is that runtime data generated? Is it stored in The Truth (as buffers) or somewhere else?
-
For large projects, it will be prohibitively expensive to have all the data in memory. How is data partially loaded and unloaded from The Truth and how do we reason about the data that isn’t loaded?
-
How do we represent The Truth data on disk in a git-friendly way (i.e. in a way that supports textual merge)? Do we need multiple representations to account for the fact that git-friendly data can be orders of magnitude slower to load than git-unfriendly data?
Some people think that you shouldn’t start to implement a system until you’ve planned out in every detail how every little part of that system is going to work. I strongly disagree. The more you implement and work with a system, the more knowledge you get of usage patterns, potential pitfalls, problem areas, etc. Making decisions upfront, when you have the least information is the worst possible time.
Instead I like to set a general direction, make sure I have a decent idea of what I want the system to do and how to achieve that (just to make sure I don’t paint myself into a corner) and then get my hands on a keyboard and start implementing. Of course, you can’t be afraid to rewrite as you learn more about how the system should work.
So far this journey with The Truth has gone well. I’m interested to see where it will take us next.