A few months ago I wrote about “The Anti-Feature Dream”, an idea of developing and exposing reusable mechanisms (the building blocks that typically recur when building features such as terrain, vegetation systems, etc) and assemble them in a data-driven way within the editor to achieve the final feature. Not only does this make the final features less static and easier to tweak to fit each products specific needs, it also empowers technical artists to more easily experiment with building completely new types of features — things that we can’t foresee.
Since then I’ve had some time to explore this idea a bit further in practice, and today I’d like to talk about what I’ve learned from that experience.
As with any new ambitious system, it’s important to scope the initial development phase carefully to avoid feeling completely overwhelmed by all the design decisions and get stuck for too long trying to figure out all the details and ins and outs of the new system. And while you could argue that the whole point of the “mechanisms” approach is to avoid building an ambitious system there’s still a need for some kind of framework that makes it possible for the various mechanisms to communicate and co-exist. So let’s begin with taking a look at the core framework.
Framework Overview
Since our goal is for TAs and non-programmers to be able to tweak and roll their own features using this system, we’ve opted for using a node graph based front-end. Each mechanism is exposed as one or multiple nodes in a graph, and new features are constructed by connecting wires between the connectors on the various nodes, much in the same way as your typical shader graph system works.
The actual data traveling on the wires is dictated by the nodes. Any plugin can extend the system with new nodes as well as new wire data types.
Right now we’ve dubbed the final features assembled like this “Creation Graphs”. And while we believe that a lot of things in The Machinery eventually will be created through this system my initial goal has been to get something in place that simply outputs content in the form of buffers and images. The first practical use case I could think of was to use this new concept for authoring data pipelines.
Data Pipelines
In any type of game engine, there’s a need for massaging data in various ways to make it run efficiently on the target platform, a process typically referred to as “cooking” or “data compilation”. I usually just refer to it as a data pipeline.
Most traditional game data pipelines are one-directional and rather static in terms of what operations they conduct. Meaning that data (such as images) enters the pipeline in some format together with some metadata that describes its contents, and the pipeline applies a set of pre-defined optimization/compression tasks on the data and then outputs a new piece of data as a result. The output is typically immutable and is what gets loaded by the game engine runtime.
With The Machinery we’ve wanted to move away from this old-school way of looking at data pipelines and instead allow each product using our tech to decide what data should be available for tweaking within the final product and how that data gets processed by the data pipeline. The reason for this is that we’re seeing an increasing trend of user-created content in games, which starts blurring the line between features historically only needed in the game editor and features needed in the game runtime. And between the editor and the runtime sits the data pipeline.
The “Creation Graph” concept fits very nicely to represent data pipelines for massaging various types of data, so let’s dive into a typical data pipeline task — Image Processing.
Image Processing
There are lots of operations involved in building a data pipeline for image processing, e.g format conversions, mipmap generation, compression, range validation, categorization, etc.
When using a Creation Graph for expressing a data pipeline for image processing you typically end up with one node importing a source image from somewhere, then piping that image through a bunch of nodes conducting the various operations of interest until you output the final result as a new image.
Exactly what you do in the graph, and how you do it, depends a lot on its execution context, e.g: It is fine for a Creation Graph responsible for processing traditional game textures authored by an artist in a DCC-tool to take a significant amount of time as they typically only need to run very infrequently (i.e., when the artist imports or updates her texture). On the other hand, a Creation Graph responsible for processing a runtime updated texture has to run very efficiently. It’s all about finding the right balance between your performance, memory and quality constraints.
In The Machinery we have a Cubemap Capture Component that is responsible for acquiring environment cubemaps by rendering the scene from the owning entity’s location into a cubemap. After all sides of the cubemap have been captured you typically need to do some processing of the result to make it useful. This is handled by passing the resulting cubemap to a Creation Graph.
Here’s a simple example of a Creation Graph responsible for taking the result from the capture and outputting Diffuse and Specular cubemaps that can be used for IBL lighting:
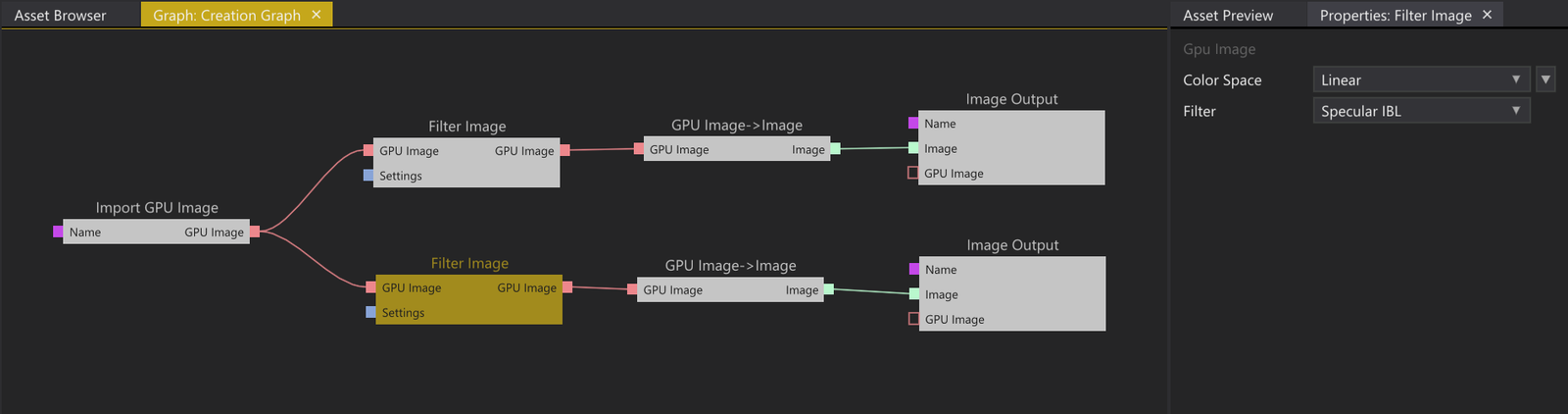
Creation Graph for preparing IBL data.
The “Import GPU Image” node gets the result from the Cubemap Capture Component and runs it through two “Filter Image” nodes, one that outputs a low-resolution irradiance environment cubemap, and one that outputs a prefiltered mipmapped radiance environment cubemap. Both filtering operations are done using compute shaders. The resulting cubemaps are then read back from the GPU to the CPU using the “GPU Image → Image” node, and finally exposed as outputs using the “Image Output” node.
The readback node is there because in this example the Cubemap Capture Component has been set up to only do captures when explicitly told to do so by having the user click a “Refresh Cubemap” button in the editor UI. In other words, it’s part of the regular content authoring process, like a normal texture, and we want to store the final filtered results in The Truth so that it gets serialized when the user saves the project.
But there might be other scenarios where you want real-time updated reflections and then you would simply leave out the read back node and just output the resulting GPU Images directly.
When dealing with image data in a Creation Graph the actual data traveling on the wires can either be of the type “CPU Image” or “GPU Image”. The difference between the two is that the bits of a CPU Image live in system memory, while the bits of a GPU Image live in local video memory (on one or multiple GPUs). Another difference is that a CPU Image stores its data in The Truth, meaning that updates are automatically replicated to all connected collaborators (if the current editing session is connected to a real-time collaboration session).
In common for both the “CPU Image” and the “GPU Image” when traveling on the wires is that they both contain a descriptor (dimension, pixel format, etc) as well a validity_hash. The validty_hash is simply a 64-bit hash value computed by the sending node that can be used by the receiving node to decide if it already has a valid result of its computation cached locally and therefore can be skipped.
There’s a lot of stuff to be said about the caching mechanics, and to touch on all aspects of it is beyond the scope of this blog post, but the core concept is the same for both images and buffers. Each node computes a validity_hash for each output resource by taking into account its local settings and the validity hashes of each input resource. If the author of a node decides its operation is computationally heavy enough to consume the extra memory needed for caching the result it can to do so. When dealing with heavy operations like image filtering and compression there’s a lot to gain from caching the results, while for other operations it might be fine to always run the operation.
I could probably write a whole blog post only about this, and maybe someday I will, for now, let’s just say that design-wise this has been one of the more complicated areas to get right and I’m pretty sure I will revisit my current solution again.
Beyond Image Processing…
When I started writing this post my intention was to cover more areas of Creation Graphs than just image processing in the context of data pipelines, but I realized there’s simply way too much to be said about each area to fit it all in the same post.
As the Creation Graph concept matures I will definitely revisit it in future posts, I feel both very excited but at the same time a bit scared of this new concept. While it’s super powerful to be able to reason about resources and schedule both CPU and GPU work all within the same node graph front-end, it’s easy to become blinded by all its possibilities and it becomes hard to decide when to stop putting stuff in.
To wrap things up here’s another very simple graph doing something completely different,
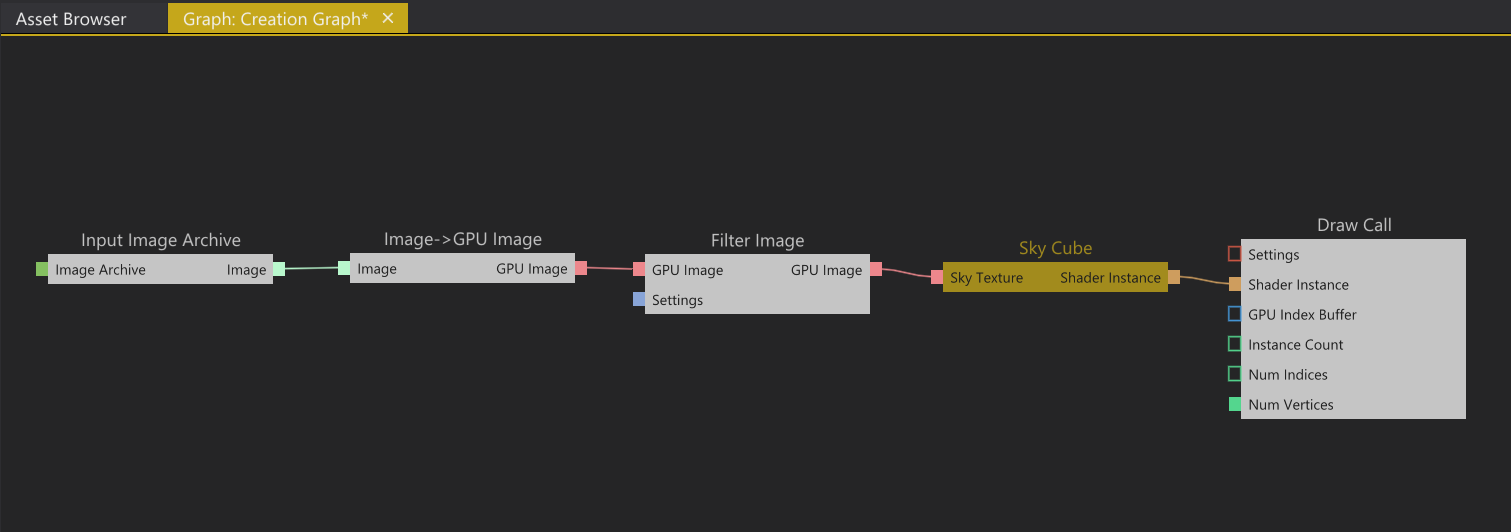
Creation Graph for rendering a skybox.
This graph loads an image from disk into The Truth (Input Image Archive), uploads it to the GPU (Image → GPU Image), generates a mipchain (Filter Image), instances a material and binds the filtered image to a texture slot (Sky Cube) and finally outputs a draw call (Draw Call). This Creation Graph is owned by the Render Component which in turn is responsible for scheduling the outputted work from the Creation Graph (i.e the Draw Call in this case).
The “Sky Cube” node is exposed to the Creation Graph by the shader system and is a very simple shader output node. The actual shader itself can be compiled on demand based on what inputs it has connected, making it possible to express what traditionally is referred to as a “Shader Graph” system but completely authored within the same Creation Graph concept.
If you extrapolate from this very simple example I’m sure you can imagine where this is going. Now the big question is to figure out if this is an awesome idea or a complete fucking disaster that we’ll regret miserably in the future. I’m not sure, but one of our primary goals with The Machinery is to find new ways to empower content creators. And the only way to do that is to move outside of our comfort zone, away from known territory into the unknown…