I’ve touched on today’s topic a few times before, but so far not dived into any actual details. However, since I’ve recently spent some time fleshing out and verifying that our APIs for dealing with explicit multi-GPU targeting actually work in practice, I thought it would be nice to do just that.
Background
Taking advantage of multiple GPUs in the same system is something that typically hasn’t been highly prioritized by the games industry. Probably because the install base of multi-GPU enabled consumer PCs hasn’t been that great, but also because graphics APIs prior to DX12 and Vulkan didn’t expose any way to explicitly reason about and control multiple GPUs. Instead game developers had to rely on Nvidia and AMD to patch up their drivers to enable SLI and CrossFire “profiles” for the game in question.
The primary focus for IHVs is usually to achieve positive framerate scaling, and the standard go-to solution has been the same for over ten years, relying on a technique that goes under the name Alternate Frame Rendering (AFR). AFR in a 2-GPU system basically means that GPU 0 renders even frames while GPU 1 renders odd frames. Historically achieving good AFR scaling hasn’t been very hard as most games had very little frame to frame interdependencies, but with the increasing popularity of rendering techniques relying on temporal reprojection, together with the introduction of UHD/4K resolutions things have become “a bit” more complicated. This is due to the increased GPU to GPU memory shuffling and the fact that most history buffers used for temporal reprojection has tendency to not be available until very late in the frame. I’m not sure what the latest tricks are to combat this problem, and to be honest I don’t really care too much about it either. I’m more focused on the future.
With the introduction of explicit multi-GPU control in DX12 and Vulkan (well, not really in Vulkan yet… but almost) the application developer becomes in control of directing and scheduling work across multiple GPUs. This opens the door for doing more exotic and application specific multi-GPU optimizations than AFR. And while I’m sure the games industry will come up with new strategies that behaves well on typical gaming hardware rigs, we are also interested in reaching outside the games industry and want to provide flexibility beyond that.
For other industries the strategies for how to best take advantage of multi-GPU capable systems starts to differ. E.g. increased framerate might not always be the main objective, it might just as well be increasing visual fidelity, or rendering different views into multiple high-resolution screens. And while games typically don’t have to care about scaling to more than 2 GPUs (or maybe 4 in the extreme case), it is not uncommon to see rigs with 8 GPUs in other industries.
So in The Machinery one of our goals has been to provide a rendering API that has multi-GPU awareness as a first-class citizen.
In this post I will try to give you an overview of how I’ve structured that in the low-level rendering APIs, but it’s not unlikely that I will follow up with some more high-level thoughts on the subject in a later post.
Render Backends & Devices
A Render Backend is responsible for translating our graphics API agnostic command buffers to actual graphics API calls (e.g Vulkan, DX12, Metal). Adding support for a new graphics API basically means writing a new plugin that implements the tm_renderer_backend_i interface. I’ve covered the high-level aspects of this API in “A Modern Rendering Architecture” so I won’t go through that again, instead I’ll focus on how to direct work to be executed on one or many GPUs using this API.
A render backend can have one or many devices active simultaneously, with each device wrapping one or many GPUs. Each GPU in a device gets a unique bit in a 32 bit bit-mask we call the device_affinity_mask. A device that wraps *n-*number of GPUs will return a device_affinity_mask that has n-number of consecutive bits set.
There are some terminology differences between DX12 and Vulkan that might be worth mentioning before moving on. In DX12 a ID3D12Device is created from an enumerated “Adapter”, an Adapter that wraps multiple GPUs is called a Multi-Adapter or a “linked node adapter”.
In Vulkan a GPU is referred to as a “Physical Device” and a VkDevice that wraps multiple physical devices is called a Device Group.
Both DX12 and Vulkan use a bit-mask to direct commands to one or many GPUs in a device, this is identical to our device_affinity_mask concept except that our bit-mask also has the ability to address multiple devices in a backend.
Here’s some pseudo code that hopefully will clear up what I mean by that:
// integrated_gpu and device_group_gpu0_gpu1 are assumed to come from some kind of device enumeration code.
wanted_devices[] = { integrated_gpu, device_group_gpu0_gpu1}
uint32_t device_affinities[2];
create_devices(2, wanted_devices, device_affinities);
// If create_devices() succeeds:
// device_affinities[0] = 0b1
// device_affinities[1] = 0b110
// To create a device affinity mask for broadcasting to all GPUs in all devices simply or them together (0b111):
uint32_t device_affinity_mask_all = device_affinities[0] | device_affinities[1];
So now when we have the concept of the device_affinity_mask for addressing individual GPUs within multiple devices sorted out, let’s take a look at what this means for our API for creating, updating and destroying resources — tm_renderer_resource_command_buffer_api.
Resource Management
The tm_renderer_resource_command_buffer_api is used to create, update and destroy backend resources. At the time of writing we have a total of six different types of backend resources: buffers, images, shaders, samplers, “queue fences” and “resource binders”. Most of them behave fairly similar with respect to the device_affinity_mask so I won’t cover all of them in detail, but let’s take a look at what they have in common.
Creation
The basic idea is that all create_() functions takes a device_affinity_mask as argument. Only the devices who’s bit has been set in the mask will create the resource in question.
When creating a buffer or an image resource in a “device group“ (a device wrapping multiple GPUs) the device_affinity_mask must either address all the GPUs in the device or just one. In the case where a resource is only created for one GPU in the group, it will only allocate local memory for the resource on that specific GPU.
Updating
All update_() functions used for updating the contents within a resource also takes a device_affinity_mask as argument. This makes it possible to let the contents of a resource diverge between GPUs. This can be really useful when doing certain types of parallel rendering across multiple GPUs, e.g in VR where you might want to render the view from the left eye on GPU0 simultaneously as you render the view of the right eye on GPU1.
As for resizing of buffers and images I’ve decided to not allow the sizes to diverge across different devices and GPUs. I thought about it and reached the conclusion that it will become too mind-boggling to keep track of, both for the user of the API, and for the person implementing new backends. At the moment I also don’t see any real use cases where it would be needed.
Scheduling, Execution and Synchronization
With resource creation and updating covered, it’s time to look at how we target execution of graphics, compute and transfer commands to happen on specific queues of specific GPUs.
It’s not enough to only target specific GPUs, we also have different queues within each GPU that runs in parallel. There are three types of different queues: Graphics, Compute and Transfer (or Copy) queues. The number of queues on a GPU differ depending on hardware. With today’s hardware there is never more than one Graphics queue per GPU, but there can be any number of Compute and Transfer queues.
Here’s a quick sketch of what we are dealing with (reflecting the hypothetical device creation pseudo code from the example above):
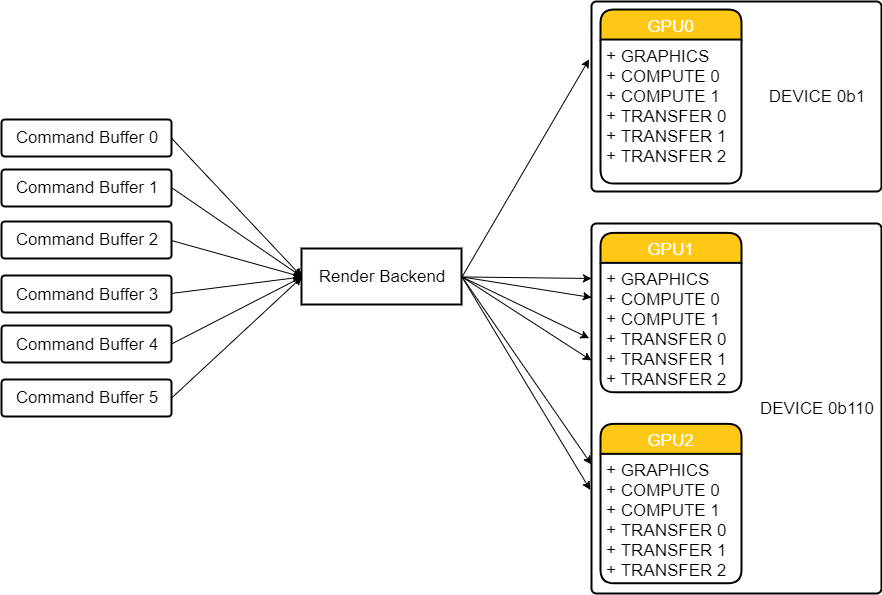
Dispatching commands to GPUS.
On the left in the image above, the worker threads in the application are filling command buffers using the tm_renderer_command_buffer_api. Scheduling (i.e ordering) of the commands in these buffers is handled through the 64-bit sort key that was covered in my post about “Simple Parallel Rendering”.
When all command buffers (that have some kind of ordering interdependencies between them) are filled, they are submitted to the Render Backend. The Render Backend then translates the commands in the these buffers into graphics API calls, i.e it builds new graphics API specific command buffers that get submitted for execution on the various queues of the GPUs.
For this to work in practice we need two things,
- To be able to direct commands to target a specific queue within one or multiple GPUs.
- To be able to synchronize queues and GPUs with each other.
Directing Commands
In tm_renderer_command_buffer_api there are two functions for directing commands:
void (*bind_render_pass)(struct tm_renderer_command_buffer_o *inst, uint64_t sort_key, const struct tm_renderer_render_pass_bind_t *render_pass, uint32_t device_affinity_mask);
and
void (*bind_queue)(struct tm_renderer_command_buffer_o *inst, uint64_t sort_key, const struct tm_renderer_queue_bind_t *queue_bind, uint32_t device_affinity_mask);
Both functions takes a device_affinity_mask as argument, and similar to the create_() functions in the tm_renderer_resource_command_buffer_api it is used to specify which devices and GPUs that should be targeted. There’s one distinct difference though, when binding a render pass or queue we are also implicitly entering a “broadcast scope”, where all of the following commands will be directed according to the last bound device_affinity_mask.
bind_render_pass() is used for binding a set of render targets and will implicitly target the Graphics queue.
bind_queue() is used for directing non-draw commands to target the Graphics, Compute- or Transfer queues:
// Command for switching execution to another command queue.
typedef struct tm_renderer_queue_bind_t
{
// One of the `tm_renderer_queue_*` enums.
uint8_t queue_family;
// 0--maximum value returned from `tm_renderer_backend_i::num_command_queues`.
uint8_t queue_index;
// Scheduling information, describes queue synchronization as well as
// broadcasting to multiple devices.
tm_renderer_scheduling_t scheduling;
} tm_renderer_queue_bind_t;
queue_family specifies the queue family: Graphics, Compute or Transfer, and queue_index specifies which queue within the family that should consume the commands.
That’s all we need for explicitly directing commands to a specific queue to be executed by one or multiple GPUs.
Synchronization
The last missing piece to the puzzle is some way to synchronize between queues and GPUs. For that we use a resource that, in lack of a better name, I have dubbed a “queue-fence”. In Vulkan a queue-fence maps to a VkSemaphore, and in DX12 it would map to a ID3D12Fence.
At the moment queue-fences only support synchronization within the same device. Copying data between two different devices requires reading back the resource data from the source device to main memory and then use that to update the resource on the destination device. This might not sound very useful in practice but depending on your latency requirements it might not be too bad. We support asynchronous read backs of both buffers and images so there’s no need for stalling.
Within the same device a queue-fence can be used both for synchronizing different queues with each other as well as synchronizing between GPUs within a device group.
In both tm_renderer_render_pass_bind_t and tm_renderer_queue_bind_t there’s a struct called tm_renderer_scheduling_t which looks like this:
typedef struct tm_renderer_scheduling_t
{
// Resource handles for queue-fences to wait on before starting command
// (optional).
uint32_t wait_queue_fences[TM_RENDERER_MAX_QUEUE_FENCES];
uint32_t num_wait_fences;
// Resource handle for queue-fence to signal when command is done (optional).
uint32_t signal_queue_fence;
// Device affinity mask identifying the GPU that will be signalling the
// queue-fence.
uint32_t signal_device_affinity_mask;
} tm_renderer_scheduling_t;
This is hopefully fairly self-explanatory, the idea is rather simple. The command queue on the executing GPU(s) will be blocked until all queue-fence resources referenced in wait_queue_fences have been signaled.
If signal_queue_fence is specified it will be signaled by the GPU referenced in signal_device_affinity_mask (which must reference a single GPU within the same device group). The signal will trigger as soon as the currently bound render pass or queue has completed all of its work.
Wrapping up
I think that covers most of how our low-level rendering API works with respect to multiple devices, GPUs and command queues.
For those of you who have some experience with “asynchronous compute” (or in other ways taking advantage of multiple GPU command queues), this shouldn’t feel too hard or weird. For those of you who hasn’t, this might feel a bit overwhelming and rather hard to get grip of at a first glance. And in a way it is, especially when you get down to the nitty-gritty details. Our ambition though is to try to make it as easy as possible to take advantage of multi-GPU systems in The Machinery, and while we realize that this might not be a high priority for today’s game developers, there are other industries where this is becoming super-important.