More on Creation Graphs
In today’s post, I will dive a bit deeper into the Creation Graph system that I covered back in April, more specifically how they work compared to typical game engine assets such as textures and materials. This will be a short and rather high-level post but nevertheless, I think it’s very important to grasp since it’s one of the core concepts to take into consideration when structuring the data layout of your projects.
In The Machinery there are no such things as texture or material assets, instead, we only have Creation Graphs. Each creation graph ends up becoming a single asset, but depending on what the graph outputs, it can contain any number of buffers, images and/or compiled shaders (materials).
On top of that, it can also contain GPU workloads in the form of draw and compute dispatch calls, as well as CPU workloads and data that can be consumed by other systems, e.g. bounding volumes.
So essentially, the creation graphs make it possible for the user to define the asset granularity of a project. A graph can be set up to output just a single image or a single material, in which case you have the same type of asset granularity as you would see in any of today’s game engines. But there’s nothing stopping you from outputting more data from the graph, giving you a courser asset granularity.
Let’s take a look at a simple example — importing a mesh with textures from a DCC asset. We’ll begin with a classic setup where each graph represents a single asset. As we are dealing with textures, materials, and meshes, we need three graphs:
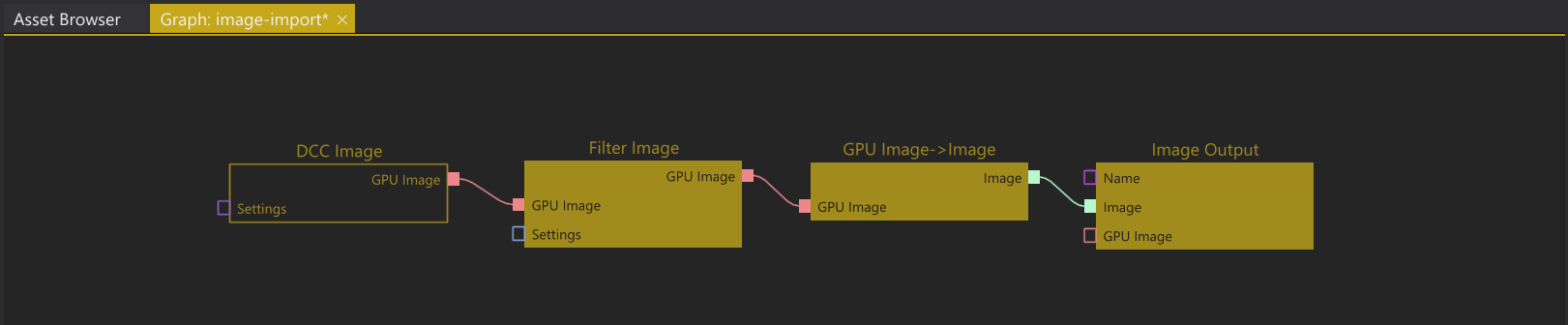
1. Importing a single image stored in a DCC Asset.
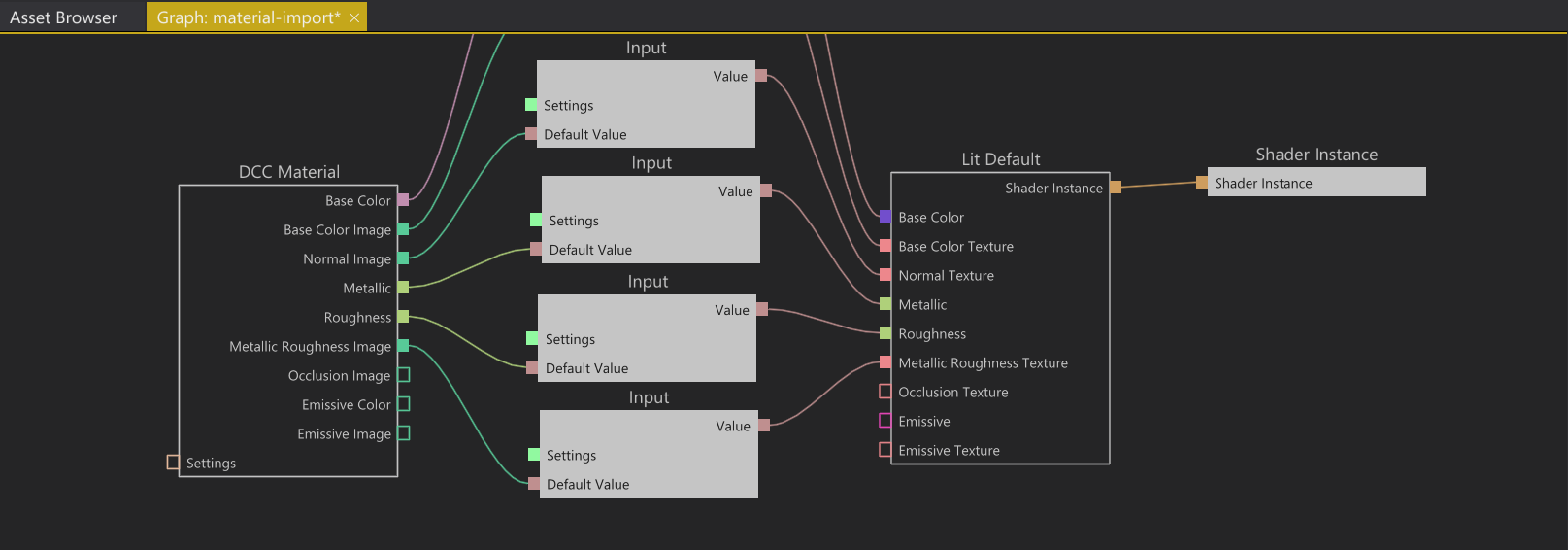
2. Importing material properties from a DCC Asset and binding them to a simple shader. The images created by graph 1 are exposed through the textures slots on the DCC Material node.
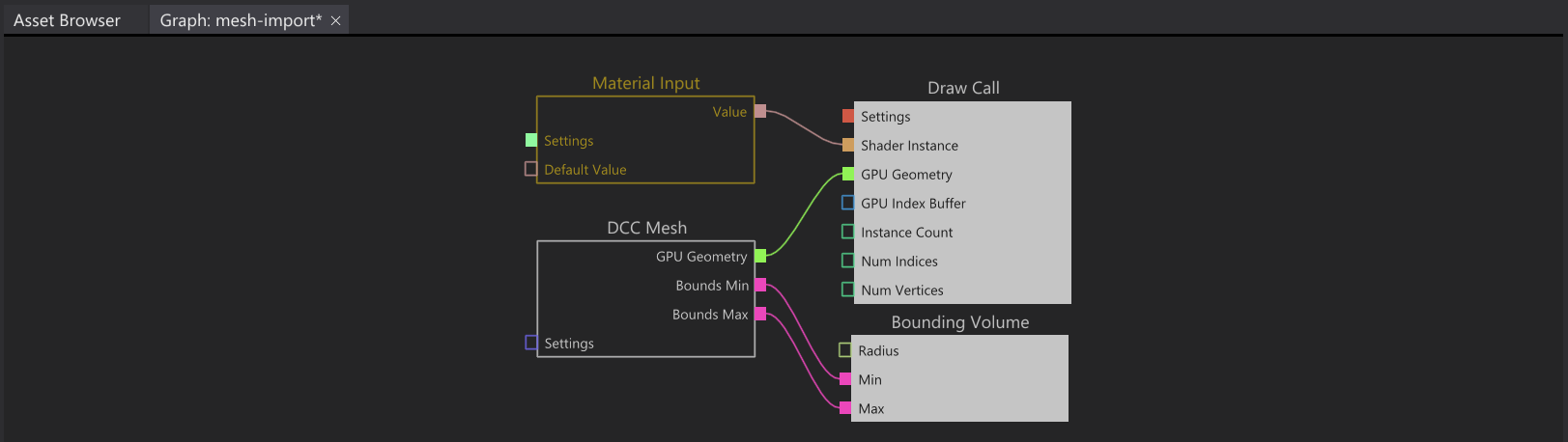
3. Importing the result from graph 2 and binding it as shader to the output draw call, also importing and binding the mesh geometry from a DCC Asset, as well as outputting a bounding volume for the culling system.
Now if the user instead prefers, she can choose to set up the mesh, including its material and texture inputs, as a single asset by rigging everything in the same creation graph:
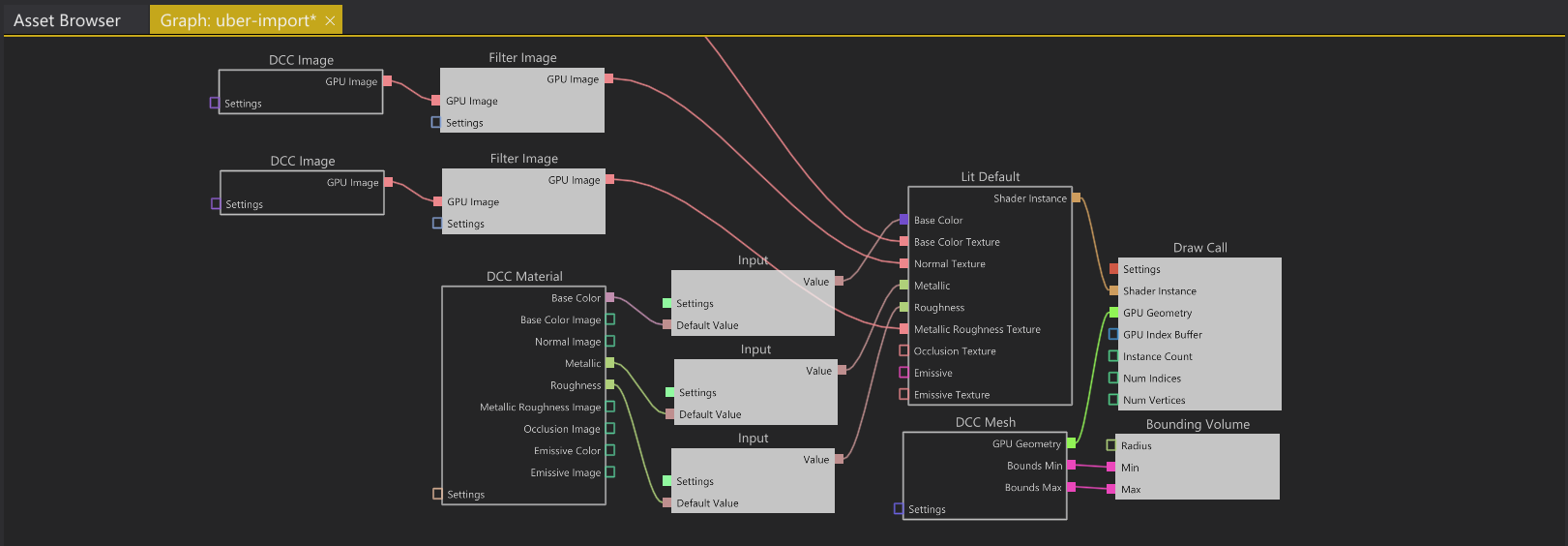
All of the above creation graphs merged into a single uber-graph.
This is somewhat of a hypothetical example, it probably wouldn’t make much sense to structure your basic DCC asset pipeline around these kinds of uber-graphs as it’s usually preferable to have immutable assets (such as imported images, and materials) shareable across multiple objects. But within other contexts there are definitely use cases where you have a tight coupling between unique buffer data and GPU workloads, a few examples being:
- Various sculpting- and paint maps associated with a terrain.
- Additional vertex data generated by a data pipeline, such as UV-unwraps.
- Buffers holding particle state in a VFX system.
By building on top of the creation graph system with its ability to freely allow the user to structure workloads and assets into sub creation graphs in any way they choose, it becomes possible to start creating some pretty advanced features. Features created and defined by technical artists, that output workloads that can be scheduled across multiple GPUs and CPU-cores, potentially even across multiple machines. It can be anything from custom data pipelines to various paint tools, to fully-fledged VFX systems.
At the end of the day, most game engine features are just chains of data transforms with some user-friendly UI on top. I see very little reason why we should pretend it’s something more complicated than that. Sure, the creation graphs might become monster noodle soups when building more complicated stuff, but I think that we as programmers can mitigate that by monitoring pain points and exposing the right type of helper nodes that reduce the graph complexity.
Also worth mentioning is that as with any object type in The Truth, the Creation Graphs can be composed through an inheritance mechanism we call prototypes (a.k.a. “prefabs”), meaning that you can layer any number of graphs on top of each other, deriving from a parent graph, and override and tweak just a subsection of the graph without losing the connection to the parent. This will hopefully reduce the support burden when a lot of features are expressed in graphs.
Our ambition is to build an engine that encourages experimentation and makes the user feel like they can create anything. Ideally without missing out on too much performance, compared to more hard-coded features, and hopefully without needing to involve programmers, even when wanting to try out some really crazy new ideas.
Someone recently asked me if I still feel uncertain if this is a good idea or not (as I wrote in my last post on the subject). The answer is no, today I definitely do think this is the right direction, but that doesn’t mean I’m not scared of it — I am! But I’m also excited, very excited! If you want to build something that stands out, there is little point in just reinventing the wheel, even if it takes more time and makes you feel scared from time to time.