The simulation model in The Machinery is based around a data-oriented entity-component-system framework (ECS). In this model, components are just chunks of raw data, for example, a Transform Component can be represented as:
struct tm_transform_t
{
tm_vec3_t pos;
tm_vec4_t rot;
tm_vec3_t scl;
};
An entity is a collection of such components. The set of components held by an entity determines its type. For example, a typical rendered object may have the components: (transform, link, mesh). Here, the Link Component links the entity to its parent and the Mesh Component references the mesh to be rendered.
In our system, an entity cannot have multiple components of the same kind — i.e. there can’t be two Transform Components in the same entity. Thus, an entity’s type can be fully identified by a bit mask of its components.
The component data for entities of the same type are stored together, in big blocks of raw memory. When algorithms work on entities of the same type, they can just walk over this memory linearly, which ensures that the operations are cache friendly.
Systems are algorithms that run on all entities that have a certain set of components. For example, the Velocity System runs on all entities that have a Velocity Component and a Transform Component and updates the transform with the velocity integrated over the time step. An implementation of the Velocity System might look something like this:
void velocity_system(tm_transform_t *td, const tm_velocity_t *vd,
uint32_t n, float dt)
{
while (n) {
td->pos = tm_vec3_mul_add(td->pos, vd->vel, dt);
++td, ++vd, --n;
}
}
To run the Velocity System, we first filter out which entities it should run on, by finding all
entities that have Velocity and Transform components. Note that this filter only needs to check
each entity type, since all entities of the same type have the same set of components. If the type
passes the test, the raw buffers of data can then be passed down to the velocity_system() function
for processing.
Running a system over the ECS data is thus really efficient. First, we perform a quick bitmask test for each entity type. (In theory, we could have up to 2^n different entity types, where n is the number of components. But in practice, we expect most entities to have similar sets of components, so the number of entity type will probably stay <1000.) Then, the system runs in bulk over the data stored for each entity type using cache friendly linear memory access.
This all works well as long as we stay inside the ECS model, but it gets trickier when we want to synchronize the changes that happen inside ECS with an external system. For example, consider synchronizing the ECS state with an external, stateful physics system, such as PhysX. This requires us to implement two-way mirroring. If the position of a kinematic actor changes in the ECS world — that change must be copied over to PhysX. Similarly, when a dynamic actor moves in PhysX, that movement must be mirrored back to the ECS world.
In this post, I will look at how we can do that mirroring. I will focus on the ECS → PhysX direction since PhysX → ECS has more to do with PhysX internals (i.e., how to get a list of actors that have moved in the physics world).
The ECS → PhysX Mirroring Problem
There are three kinds of situations we need to handle to have a complete mirroring solution:
When an object is created in ECS that should have a PhysX representation, we need to create that representation.
When an object is moved in the ECS world, the movement must be mirrored to the PhysX world.
When an object is deleted in the ECS world, its corresponding PhysX actor must be destroyed.
All of these are aspects of the same problem — we need to be able to find out when certain things change in the ECS world so that we can mirror those changes to PhysX. Thus, the fundamental question is: how can we track changes in the ECS data in an efficient way?
Note that this problem doesn’t just pop up with physics. We run into it whenever the ECS data needs to be synchronized with an external system or if we for some other reason (performance, etc) want to process just the data that has changed. Rendering, sound, UI and even basic scene tree updates all run into this same issue.
Change Tracking Methods
Let’s attack the problem by first listing all possible ways we can think of tracking changes and then we will try to find the best solution.
Brute force
The simplest and most zen way of doing change tracking is by not doing change tracking. To mirror changes into our external system, we don’t do anything fancy, we just mirror everything. I.e. we run a system every frame on entities with the mask (Kinematic PhysX Actor & Transform). The system copies the transform from the Transform Component over to the Kinematic PhysX Actor Component.
void mirror_kinematics_system(tm_kinematic_actor_t *kd,
const tm_transform_t *td, uint32_t n)
{
while (n) {
kd->actor->setGlobalPose(to_physx(td));
++kd, ++td, --n;
}
}
This approach is super simple and requires no additional data structures. The drawback, of course, is performance. Since we process every object, regardless of whether it has actually moved or not, we are potentially doing a lot of unnecessary work.
How big of a problem is this? It depends. I think one of the key lessons of data-oriented design is
that brute force algorithms can be surprisingly effective when they are parallelized and operate
linearly on cache-friendly data. It’s hard to know how expensive the PhysX setGlobalPose() call is
and it might not be cache friendly (since we don’t control how the PhysX actors are laid out in
memory). However, we can easily get around that by adding a dirty or version flag to the
Transform Component. This way, we can just skip over the objects that haven’t moved since the last
frame and only call setGlobalPose() on the things that have actually moved. The cost of processing
the non-moving objects is then just the cost of traversing their memory.
How bad is this? The worst case would be if we had a scene with say 10 000 actors and only one of them is moving. Even this case is not terrible. Walking through the memory of those 10 000 objects is not that expensive. You could also argue that this is a completely contrived example. Why would you have 10 000 kinematic actors in the scene if they are not moving? In that case, you should probably just use static actors instead and switch them over to kinematic actors once they start to move. That will also reduce the cost of physics collision detection and simulation.
But say that this was a real problem. Is there anything we could do to speed up this case?
Sure! Instead of just storing a version/dirty flag per-object we could create a binary tree of them:
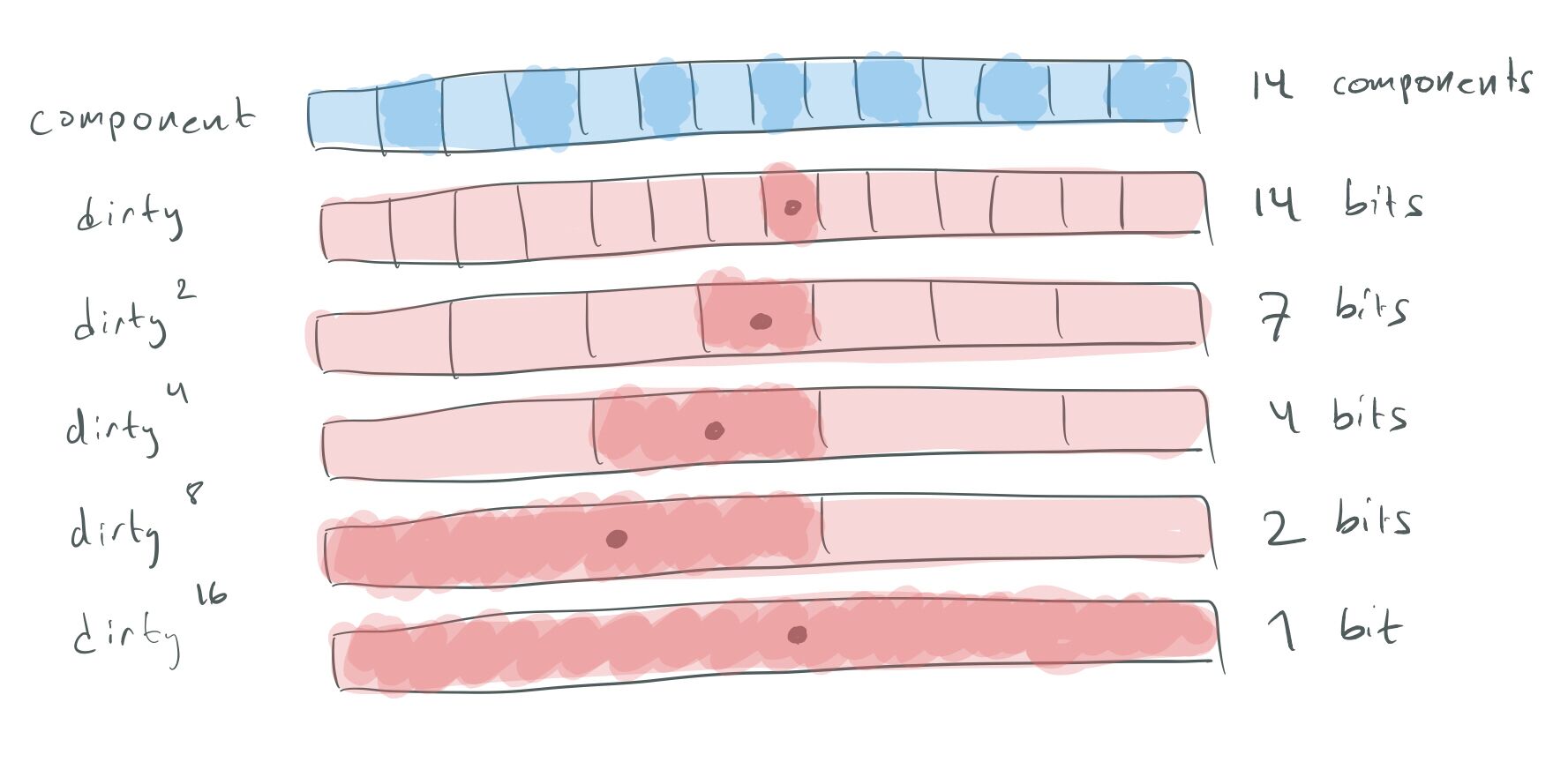
Hierarchical dirty flags.
This tree works similar to a voxel octree for raycasting. First, we check the highest level version/dirty flag to find out if any of our 16 384 objects have changed. If not, we’re done. Otherwise, we check the flag for the first 8 192 objects — if none of them have changed, we skip to the next 8 192 objects and check their flag, and so on.
In the degenerate case above when 1 out of N objects moved, the update cost will just be O(log N) rather than O(N).
Orchestrated by higher-level system
Another way of doing change tracking without doing change tracking is to remove the responsibility from the ECS code altogether. With this approach, we don’t put any change tracking code in the ECS at all. Instead, for change propagation to happen, it must be orchestrated by a higher level system.
In practice, this would work something like this: Say that a higher level system (such as Script or Animation) wanted to move an object. This system would “know” that the Physics system might be interested in such movements. So in addition to moving the object, the higher level system would also send a notification to the Physics system: “Hey, I just moved this object”. The Physics system could then check if the move needed to be mirrored and take appropriate action.
This setup can work in a game where all components are known. In that case, you can enumerate all the possible interactions that can happen between systems and make sure that systems are explicitly notified about changes.
However, it is not a great fit for Our Machinery. We are building a generic engine that can be extended with new components and new systems through plugins. Thus, there is no way for us to predict and enumerate all the possible interactions that can happen.
Callbacks
Callbacks, or the observer/observable pattern, is a very common and traditional way of propagating
changes between systems. With this approach, the system who wants to track changes would register a
callback function to be called whenever a specific component of a specific entity is changed. A
function that modifies component data would call a notify() function on the entity, which in turn
would trigger these registered callbacks.
An advantage of callbacks is that they allow change tracking to be very finely controlled since they can target individual entities. For example, a Follow system that allows one entity to follow another could be set up to only listen to changes to that particular entity’s movements. No other entity transforms would need to be processed.
Another advantage of callbacks is that they can be set up to happen immediately.
The Brute Force method described above is a batch method. We make changes to our ECS world. Then, at some specific point in time, we run the Mirror Kinematics System and the changes get copied over to the physics world. This means that for some time, between the ECS changes and the mirroring, the ECS world and the physics world will be out of sync. If we do a raycast during this time, it might miss objects that it should hit, based on their positions in the ECS world.
In contrast, if we were using callbacks, we could make sure that the physics positions were updated immediately, and the physics world would always match the ECS world.
Out-of-sync physics can create lots of trouble in the gameplay layer. For example, if a car is driving at 100 km/h, it will move a full meter in a 30 Hz frame. Weapons targeting the car with a raycast may miss it completely if the physics is lagging a frame.
There are lots of ways of dealing with out-of-sync issues and lots of ways they can come creeping back in again.
For example, we might make sure that any “gameplay” code (where raycasts are being made) is run “after” the “mirror step”, so when the gameplay code runs, the physics and ECS worlds are synchronized. That works to an extent but breaks down if the gameplay code moves some entities that have physics (either directly or indirectly). Now, those moves won’t be reflected into physics for gameplay code that runs after that.
So maybe we can divide the gameplay code into a “before physics mirror” and “after physics mirror” step? Or run the physics mirror system multiple times? Or have a back door for the gameplay code to tell the physics system that it moved some object, so the physics system can mirror just those objects (basically, an orchestrated solution)?
A ton of possibilities… which can fix some issues but also potentially cause other ones. I won’t dive deeper into these out-of-sync issues here, that could be a whole other post, just note that using callbacks instead of batched updates can potentially fix the problem.
What are the drawbacks of using callbacks? Unfortunately, precisely the things that make them useful.
We want our ECS system updates to run efficiently on multi-core processors. Fortunately, we can achieve a lot of this parallelism automatically without using locks or critical sections (which tend to hurt performance). If we let each system declare which components it reads from and writes to, we can schedule systems to run in parallel as long as no system is writing a component that another system is using (sharing reads is ok).
However, if we have a callback system, that reasoning goes out the window, since we don’t know what the callback might do and how it might interact with other threads. For example, the callback might write to an unrelated component, or touch global data.
There are only two ways out of this. Either we need to defer the calling of callbacks until we’re back on a “main thread” where “touching anything” is safe or we need to add a way of declaring reads and writes for callbacks too so that the system scheduler can reason about when it’s safe to perform the callbacks.
Deferring the callbacks means they no longer happen immediately, so that means we’re back in the situation where the ECS world and the physics world go out of sync. Depending on how long it takes us to get back on the “main thread” that problematic window when the worlds are out-of-sync may be shorter than in the brute force case though, which is a plus.
Calling callbacks immediately can also be bad for performance. It can cause instruction and data cache misses as we’re suddenly jumping to a completely different part of the code.
The notify() call we have to make each time we change component data can also be expensive. Bulk
updates of component data can be as cheap as a memcpy(). If we have to call notify() for each
update, that can add a significant cost.
Lists of changed entities
Instead of calling callbacks whenever an entity is changed, we can just put the changed entity on a list. Later, we can process this list of changed entities and mirror them to an external system, or do whatever other kinds of change tracking we need to do.
Note that this approach is pretty similar to using callbacks when we defer the callbacks to “later”. The only difference is that instead of a list of callbacks to call, we have a list of changed entities that other systems can poll. It’s thus a “poll” rather than “push” method of change tracking.
The advantage of polling is that it gives you more control over the code and data flow. With polling, you know exactly at which point in your code you are doing the polling and when changes are being processed. With callbacks, the callback can come at “any time”. That makes it harder to predict all kinds of code flow that can happen and it is easy to get bugs. (For example, a callback may trigger another callback recursively.)
Systems for processing changes will typically be interested only in specific changes. For example, the ECS → PhysX mirror will be looking for entities with a Transform and a Kinematic Actor component, where the Transform component has changed. If we just have one big list of all changed entities, the mirror code will have to skip past a lot of changes that concern other entities and other components (similar to how the brute force method has to skip over a lot of components that hasn’t changed).
To avoid this we could keep a list for each changed component for each entity type. That way we can use the same filtering technique that we use for our system updates to run our change processing. Another advantage of arranging the lists like this is that since we’re already making sure that no systems that write to the same component run simultaneously, we don’t need any additional synchronization for the changelists. (Since each component has its own changelist and we only add to the changelist if we hold the write lock for the component.)
This is potentially a lot of lists though, so we have to be a bit clever with how we update them.
Using changelists is pretty cheap. We only need to push an item to the end of an array whenever we change component data.
Using the entity type system
Here’s a final idea. We already have an efficient way of filtering system updates — the entity type system. What if we use the same system for tracking changes?
Here is how it would work: Whenever a component (say the Transform Component) is changing, we add an additional component — the Transform Changing Component. To mirror moving objects to the physics system we can then just run a regular system update on all entities that have the components (transform, transform changing, kinematic actor).
Since all the entities that have the same set of components store their data together, the data for processing the moving entities would be efficiently packed, for maximum cache performance.
What is the cost of this? Whenever we change the transform of an entity, we will have to check if it already has a Transform Changing Component or not and make sure we add that component if it’s missing. This could be relatively cheap though.
In addition, we need some way of removing the Transform Changing Component if the entity is no longer moving. When we update our entities with the Transform Changing Component, we could check if the entity hasn’t moved in the last N frames, and in that case, get rid of the component.
This solution also has a cost for adding and removing the Changing component. Every time we do that, we need to move the entity’s data which is not cheap. The cost of this depends on how often this is changing if the entity is starting and stopping a lot.
In addition, there will also be a cost of having a lot of more entity types in the system. If we do this for every component, we are doubling the number of components. Entity types may increase even more. For example, without this, a basic mesh entity would have the type (transform, link, mesh). With this approach, that basic mesh could have any of the following types (based on which components are changing):
- (transform, link, mesh)
- (transform, transform changing, link, mesh)
- (transform, link, link changing, mesh)
- (transform, transform changing, link, link changing, mesh)
- (transform, link, mesh, mesh changing)
- (transform, transform changing, link, mesh, mesh changing)
- (transform, link, link changing, mesh, mesh changing)
- (transform, transform changing, link, link changing, mesh, mesh changing)
A lot more entity types means that all our systems will have to do more filtering and work on smaller batches, which will hurt performance.
Again, the costs depend a lot on the specifics of the setup. Are components mostly static? In that case, we might not get a big proliferation of entity types and it might be worth it to get things nicely sorted.
Conclusions
I think all these systems have their merits.
Brute force: I think this should be the default go-to solution for most change tracking problems. It should be fast enough for most scenarios and in the cases where it is not, adding hierarchical dirty tracking gives a nice speedup.
In The Machinery, we use this for most things.
Orchestrated: I don’t like how this approach requires special knowledge about components, but there are situations where that special knowledge can be used to significantly speed up or simplify a system and in those cases, an orchestrated solution might be the right fit.
As an example of this, in The Machinery, our Link Component API has a
transform()function that propagates any changes to the Link Component (parent, local position, etc) to the Transform Component and its children. This avoids having to run a custom system to check for changes to the Link Component, but it requires that everyone who changes the Link Component data knows about and makes sure to call thetransform()function.In this case, the orchestration isn’t so bad, because anyone who knows about the Link Component should also know about its API. Orchestration is trickier when it involves more than one component. For example, if you need to notify the Physics Mirror System when the Transform Component is changed.
Callbacks: Callbacks are generally problematic and I’d like to avoid them, but there are situations where I still use them. We have
add_component()andremove_component()callbacks that get called whenever a component is added to or removed from an entity. These can be used to perform necessary setup/teardown of a component — for example, create or destroy a corresponding PhysX actor.For propagating changes, the one big advantage of callbacks is that they happen immediately. There are some cases where we really want this. For example, I like to do parent-child scene tree transformations immediately rather than deferred. I.e., when we move the parent, its children are immediately moved. The reason I prefer this is that if you defer the update of the children’s positions then you again end up with out-of-sync issues, where the children’s world positions are lagging a frame until we do the batch update.
Currently, we use callbacks to trigger the scene tree updates. This works, but I’m not super happy with the approach. Anyone modifying the Transform Component needs to call
notify()which adds an extra cost. We are also relying on special knowledge that it’s safe to call this callback from the system update thread since it will only write to the Transform Component (which the system callingnotifyalready has requested write access too).Having all this special knowledge feels ugly. On the other hand, I have no other good way of making sure that child transforms are updated immediately. In theory, we would like our users to be able to implement their own Transform Component and have it work with all our systems, just as well as the Transform Component we supply. In practice, it seems very unlikely that any user would actually want to do that, so maybe we shouldn’t be bending over backward to make that possible.
Lists: I’m not sure lists are that useful. I can’t think of that many real-world scenarios where lists would have a big performance advantage over Brute Force methods. Especially considering the possibility of hierarchical version tracking.
One possible exemption is in the case where you want to do a lot of synchronizations. Suppose that as a way of combating the out-of-sync problems, instead of using callbacks, you just run a lot of batch updates — one before the script runs, one after the script runs, etc, etc. In this case, lists are nice because you are only processing the objects that actually changed and avoid the O(log N) overhead of hierarchical brute force. I think I would still try to do brute force in this case though, and only change it if profiling showed big performance issues.
We currently don’t use lists anywhere in The Machinery.
Entity types: I think adding different kinds of “helper components” can be a powerful way of grouping data for fast updates. I don’t think I would add a Changing component for each component in the system, because of the risk of a blow-up in the number of entity types and also because most components don’t really need it. Having a Transform Changing component might be interesting though. It would kind of mimic the setup we used to have at Bitsquid where we kept separate arrays of moving and non-moving units.
Entity types can be used in other ways too. For example, one way of implementing the Follow behavior discussed above would be to add a Followed Component to any entity that is targeted by a Follow Component. That way, we could easily extract the transforms of all followed entities and apply them to the entities that follow them.
It is a bit unsatisfying that we don’t have a single system for change tracking that we can use across all our different components and systems instead of a hodgepodge of different approaches. It would be nice if we had a single system of tracking and processing changes that we could use for everything. However, right now I can’t see a good single way that will work well in all the situations we need.